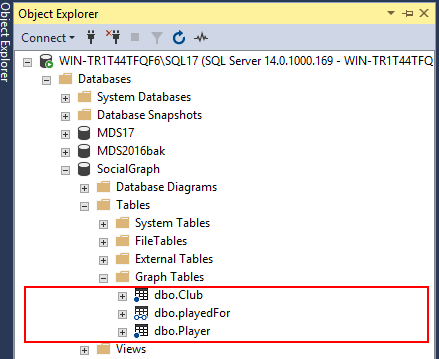
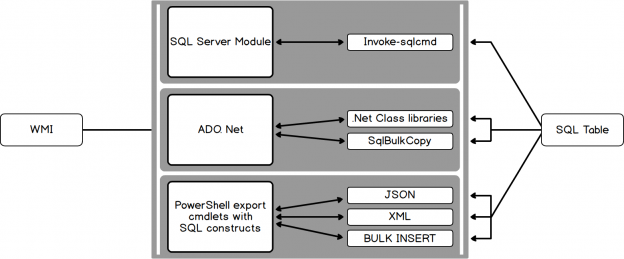
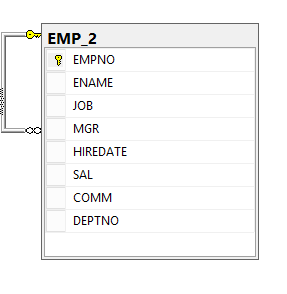
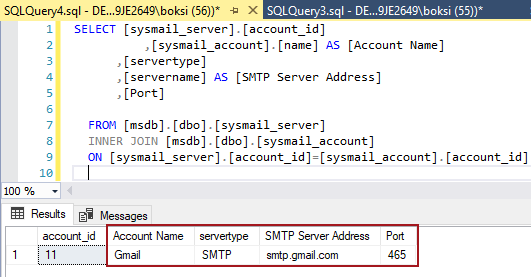
A few years ago, one common business case I came across in my professional career that required modelling of data into a many-to-many entity relationship type was the representation of a consultants and their projects. Such a business case became a many-to-many entity relationship type because whilst each project can be undertaken by several consultants, consultants can in turn be involved in many different projects. When it came to storing such data in a relational database engine, it meant that we had to make use of bridging tables and also make use of several self-joins to successfully query the data.
Read more »