The SQL MIN function is an aggregate function that is used to find the minimum values in columns or rows in a table.
Read more »

The SQL MIN function is an aggregate function that is used to find the minimum values in columns or rows in a table.
Read more »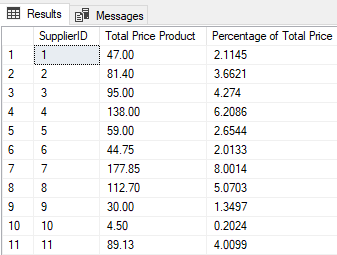
In this article, you will see the different ways to calculate SQL percentage between multiple columns and rows. You will also see how to calculate SQL percentages for numeric columns, grouped by categorical columns. You will use subqueries, the OVER clause, and the common table expressions (CTE) to find SQL percentages.
Read more »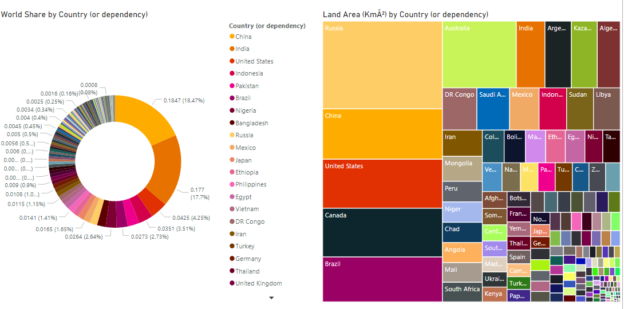
Microsoft’s Power BI is a data analytics tool that can be used to plot rich reports and graphs for data analysis without writing a single line of code. Among myriads of other features, you can apply different types of Power BI report themes to change the outlook of your reports.
Read more »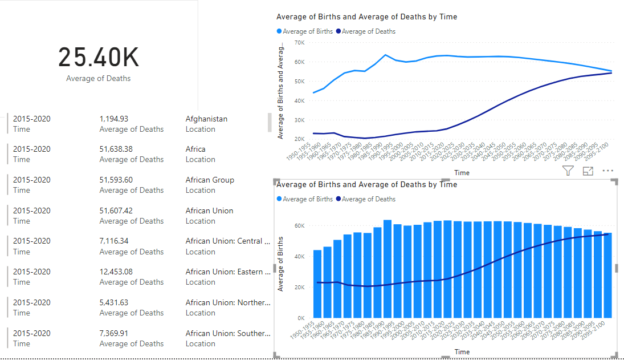
In this article, you will look at Power BI Waterfall charts and see how they can be used to plot distributions of numeric data against categorical data. You will also see how you can combine multiple charts in reports view to create Power BI combined visuals.
Read more »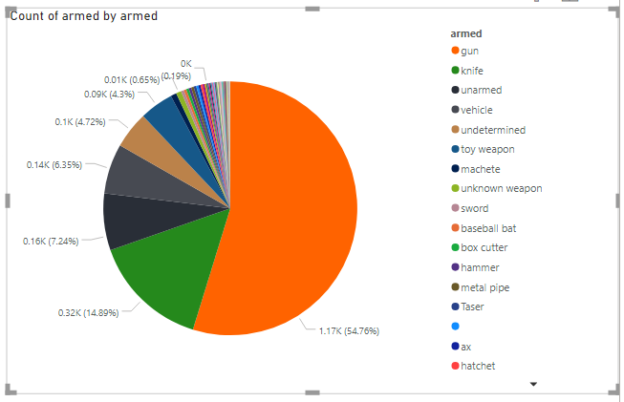
This article shows you how to use Power BI conditional formatting and apply different color schemes to reports in the Reports View of Power BI desktop. The same process can be applied for Power BI conditional formatting in the cloud.
Read more »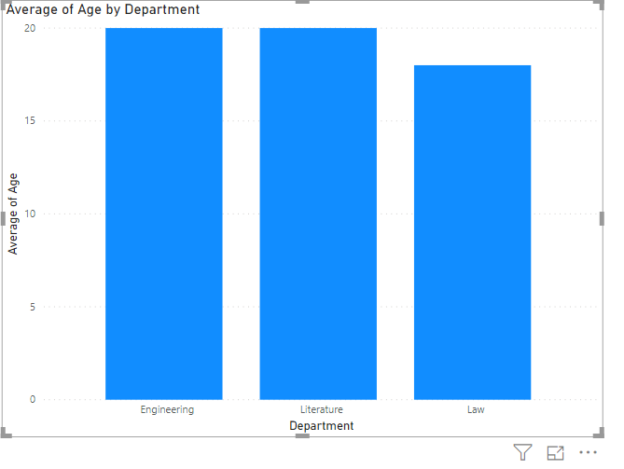
Microsoft Power BI is a data analytics and visualization tool that can be used to visualize data in the form of different types of reports, without writing a single line of code.
Read more »
Microsoft Power BI is a data analytics tool available in two flavors: Power BI Desktop and a Power BI Service.
Read more »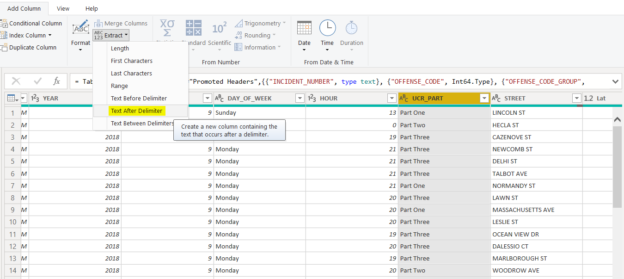
In this article, you will see how to use the Extract function in Power BI to extract information from columns in a Power BI dataset.
Read more »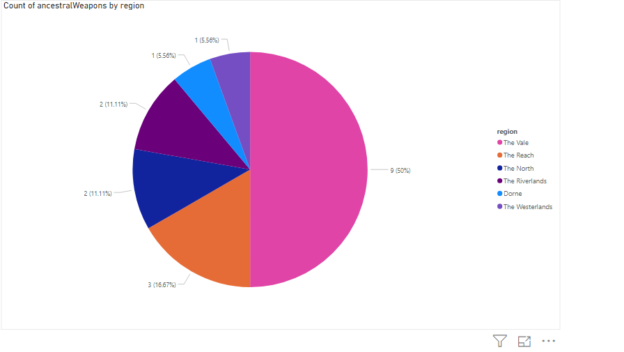
In this article, you will see how to import data from JSON files and Power BI Rest API into the Power BI environment.
Read more »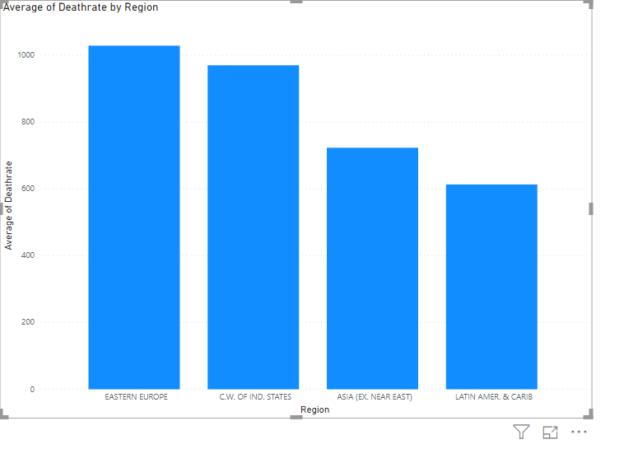
Power BI is a data analytics tool that can be used to analyze data with the help of Power BI visuals.
Power BI is a Microsoft application and is available as a desktop application as well as a cloud service. It comes with a variety of visual and filtering options that can be used to create Power BI visuals.
Read more »
In this article, you will learn how to work with Treemaps and Tables, which are two of the most commonly used Power BI visuals. You will also see how slicers can be used in Power BI to dynamically update the data in Treemaps and Tables. Power BI Visuals are extremely easy to create and don’t require you to write any code.
Read more »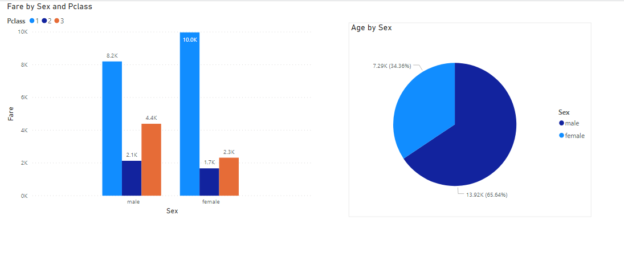
The Report View in Power BI can be used to create beautiful visualizations in Power BI.
Read more »
Microsoft Power BI supports two different languages, M language and DAX (Data Analysis Expression) that can be used to filter, manage, and visualize data.
Read more »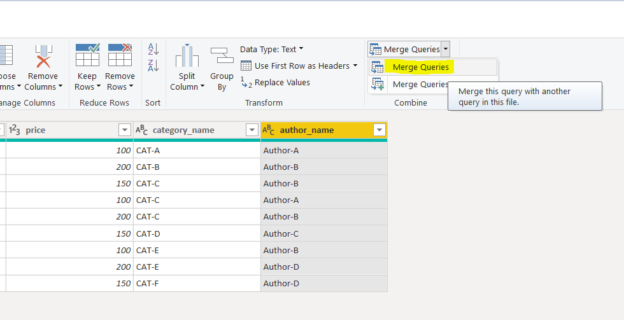
In this article, you will see how to implement a star schema in Power BI. Microsoft Power BI is a business analytics tool used to manipulate and analyze data from a variety of sources.
Read more »
In this article, we look at how to create different types of relationships between two or more tables in the Power BI data model.
Read more »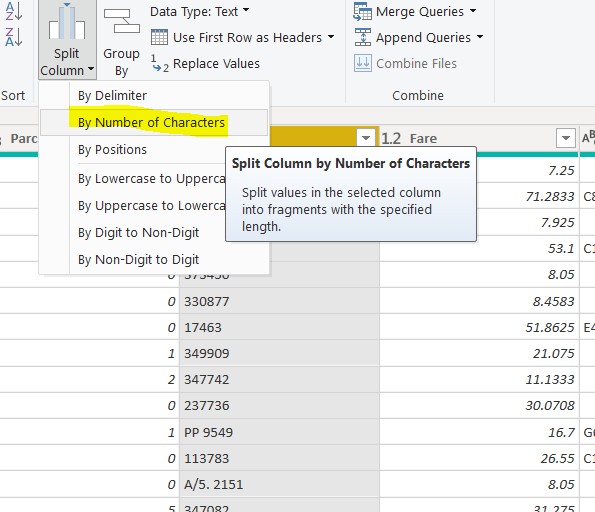
Power BI is a data analytics tool developed by Microsoft used to visualize data and find useful insights. In this article, you will see how to work with the Query Editor in Power BI desktop. Power BI comes in various versions, i.e., Power BI Desktop, Power BI Service, Power BI Mobile, and Power BI Developer. Power BI desktop is the free version, and the query editor is available in all three versions.
Read more »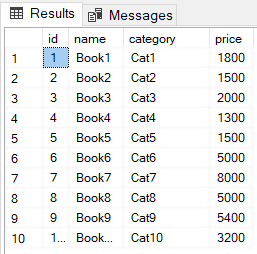
The SQL CREATE INDEX statement is used to create clustered as well as non-clustered indexes in SQL Server. An index in a database is very similar to an index in a book. A book index may have a list of topics discussed in a book in alphabetical order. Therefore, if you want to search for any specific topic, you simply go to the index, find the page number of the topic, and go to that specific page number. Database indexes are similar and come handy. Particularly, if you have a huge number of records in your database, indexes can speed up the query execution process. There are two major types of indexes in SQL Server: clustered indexes and non-clustered indexes.
Read more »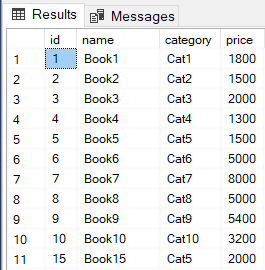
The rollback SQL statement is used to manually rollback transactions in MS SQL Server.
Read more »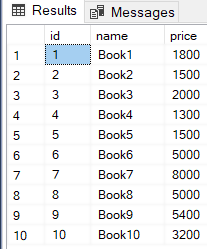
A SQL injection attack is one of the most commonly used hacking techniques. It allows hacks to access information from a database that is otherwise not publically accessible.
Read more »
The sp_executesql stored procedure is used to execute dynamic SQL queries in SQL Server. A dynamic SQL query is a query in string format. There are several scenarios where you have an SQL query in the form of a string.
Read more »
The SQL EXCEPT statement is one of the most commonly used statements to filter records when two SELECT statements are being used to select records.
The SQL EXCEPT statement returns those records from the left SELECT query, that are not present in the results returned by the SELECT query on the right side of the EXCEPT statement.
Read more »
This article covers how to connect a Python application to Microsoft SQL Server using a 3rd party Python SQL library. The library that we are going to use is called “pyodbc”, which is freely available. We will use “pyodbc” to perform CRUD (Create Read Update and Delete) operations on a Microsoft SQL Server database.
Read more »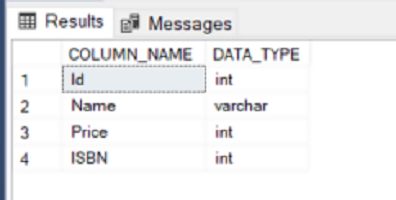
This article explains SQL DDL commands in Microsoft SQL Server using a few simple examples.
Read more »
The SQL While loop is used to repeatedly execute a certain piece of SQL script.
Read more »
In this article, you will see how to use different types of SQL JOIN tables queries to select data from two or more related tables.
Read more »© Quest Software Inc. ALL RIGHTS RESERVED. | GDPR | Terms of Use | Privacy