The SQL update statement is used to modify an existing record or records in a table and it is commonly widely used in databases applications. In this article, we will examine the update statement in terms of the performance perspective.
Read more »
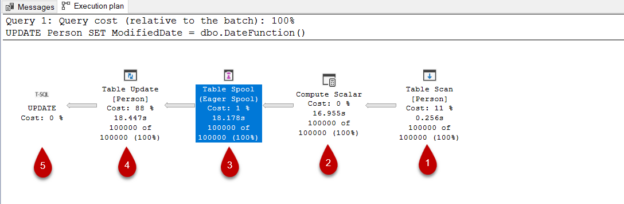
The SQL update statement is used to modify an existing record or records in a table and it is commonly widely used in databases applications. In this article, we will examine the update statement in terms of the performance perspective.
Read more »
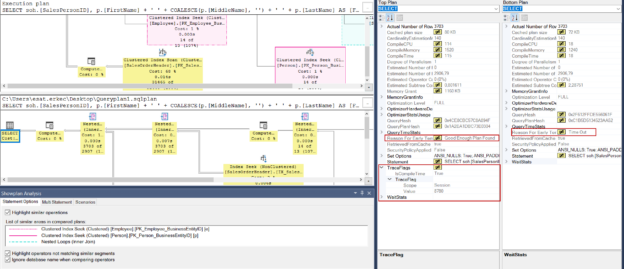
In this article, we will learn some query hints and trace flags that impact the query performance and also influence the SQL Server query optimizer’s default execution plan generation algorithm.
Read more »
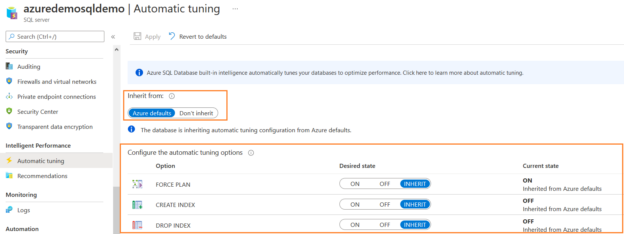
This article will explore automatic index advisor (CREATE_INDEX, DROP_INDEX) for Azure SQL Database.
Read more »
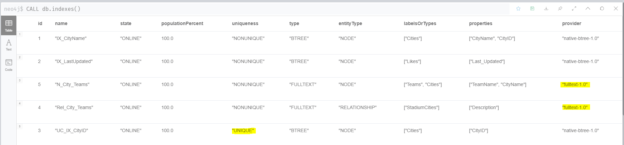
In our previously published article in this series, we explained how to migrate SQL Server graph tables into Neo4j and why migration could be beneficial. We only mentioned how to migrate node and edge tables, and we did not mention indexes and constraints. This article is an extension of the previous one, where we will explain how to export the supported indexes and constraints from SQL Server to the Neo4j graph database. In addition, all codes are added to the project we already published on GitHub.
Read more »
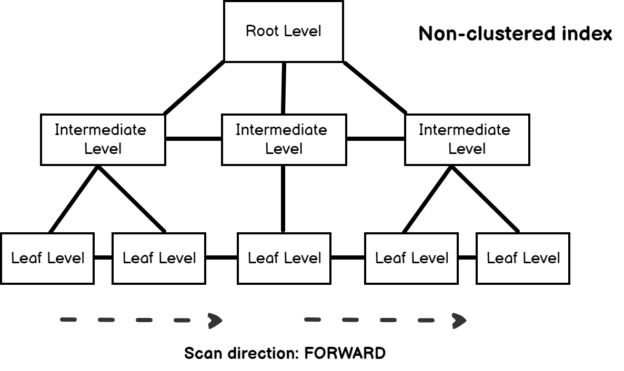
Gaining experience in SQL query tuning can be very difficult and complicated for database developers or administrators. For this reason, in this article, we will work on a case study and we are going to learn how we can tune its performance step by step. In this fashion, we will understand well how to approach query performance issues practically.
Read more »
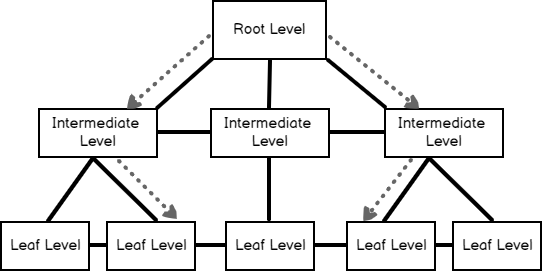
In this article, we will learn the SQL Server clustered index concept and some internal details. Indexes are the database objects that accelerate the performance of data accessing when are designed properly. A clustered index is one of the main index types in SQL Server and the working principle is a bit complicated but in the next sections of this article, we are going to simply learn the clustered index working principle and uncover the secrets.
Read more »
In this article, we will be talking about Manticore Search, which is an open-source search engine first released in 2017 as a fork of the Sphinx search engine. We will try to describe this search engine briefly, mention some of its differences from the Sphinx search engine, and we will provide a step-by-step guide on how to build full-text indexes from SQL Server databases. Finally, we will show how to connect to the Manticore engine from the SQL Server management studio using a linked server object. In our previously published articles in this series, we talked briefly about the Sphinx search engine and how to create full-text indexes from SQL Server databases.
Read more »
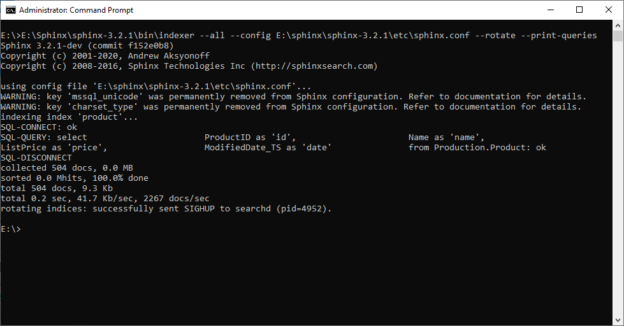
In the previously published article, Getting started with Sphinx search engine, we talked about the Sphinx search engine and how to install it on the Windows operating system. In this article, we will talk about building full-text indexes using Sphinx. We will be covering seven topics:
Read more »

In this article, I am going to explain how we can automate the index and statistics maintenance of Azure SQL Database using an Elastic Job Agent.
Read more »
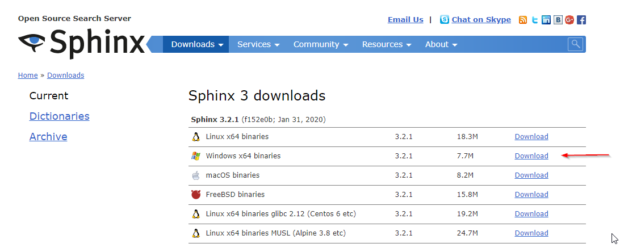
In this article, we will be talking about the Sphinx search engine and how to use it to install it on the Windows operating system.
Read more »
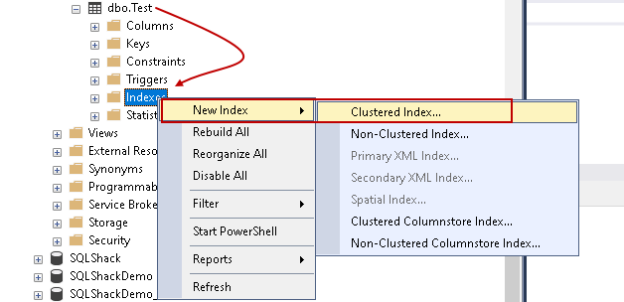
This article gives you an insight into SQL Server Index properties in SSMS.
Read more »

This article gives you an overview of Unique Constraints in SQL and also the Unique SQL Server index. Along the way, we will look at the differences between them.
Read more »
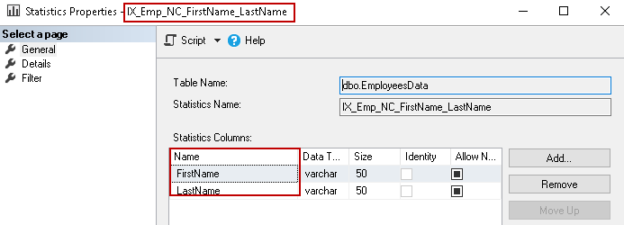
In this article, we will explore the Composite Index SQL Server and the impact of key order on it. We will also view SQL Server update statistics to determine an optimized execution plan of the Compositive index.
Read more »
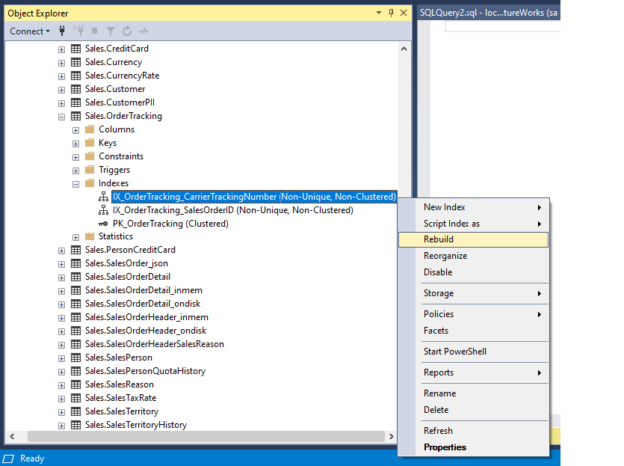
In this article, we will learn how to identify and resolve Index Fragmentation in SQL Server. Index fragmentation identification and index maintenance are important parts of the database maintenance task. Microsoft SQL Server keeps updating the index statistics with the Insert, Update or Delete activity over the table. The index fragmentation is the index performance value in percentage, which can be fetched by SQL Server DMV. According to the index performance value, users can take the indexes in maintenance by revising the fragmentation percentage with the help of Rebuild or Reorganize operation.
Read more »
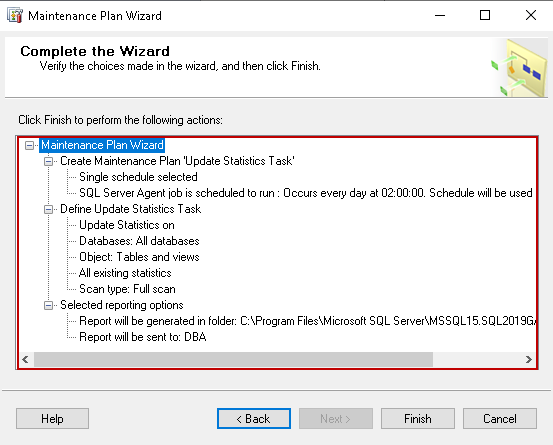
This article explores SQL Server Update Statistics using the database maintenance plan.
Read more »
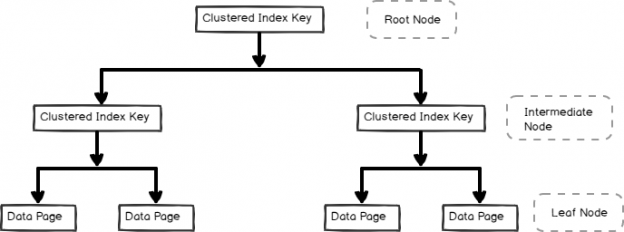
This article gives an introduction of the non-clustered index in SQL Server using examples.
Read more »
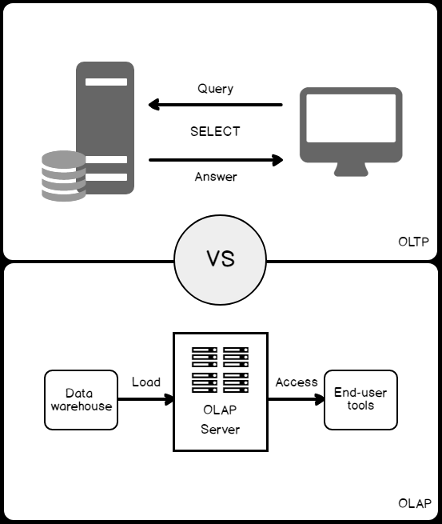
In this article, we will discuss the most important points that we should consider when designing an optimal SQL index. Before going through the index design procedure, let us revise the SQL Server index concept.
Read more »
The SQL CREATE INDEX statement is used to create clustered as well as non-clustered indexes in SQL Server. An index in a database is very similar to an index in a book. A book index may have a list of topics discussed in a book in alphabetical order. Therefore, if you want to search for any specific topic, you simply go to the index, find the page number of the topic, and go to that specific page number. Database indexes are similar and come handy. Particularly, if you have a huge number of records in your database, indexes can speed up the query execution process. There are two major types of indexes in SQL Server: clustered indexes and non-clustered indexes.
Read more »
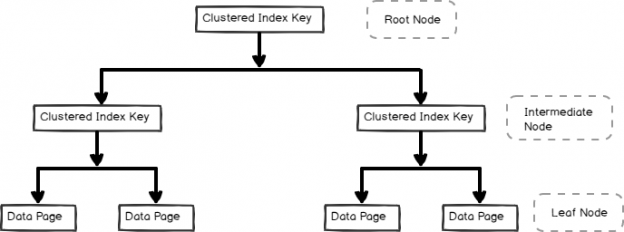
This article targets the beginners and gives an introduction of the clustered index in SQL Server.
Read more »
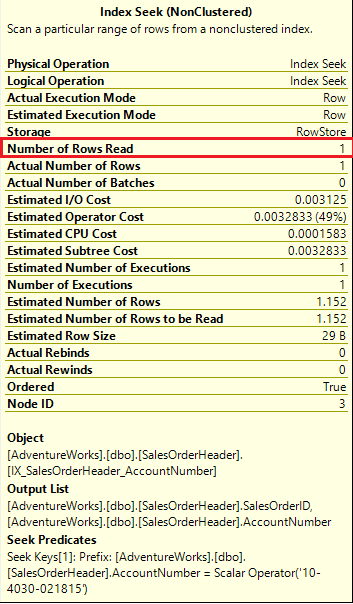
In this article, we’ll discuss data type VARCHAR and query performance issues associated with utilizing the lower level VARCHAR data type. CHAR, VARCHAR and NVARCHAR are data types that support storing information in text format in a SQL Server database. These data types allow a wide assortment of character sets in the defined field or column in the database table.
Read more »
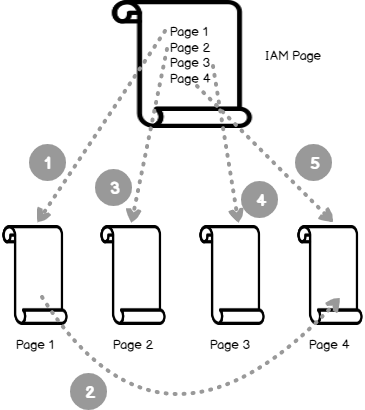
This article discusses the Forwarded Records and its performance issues for heap tables in SQL Server.
Read more »
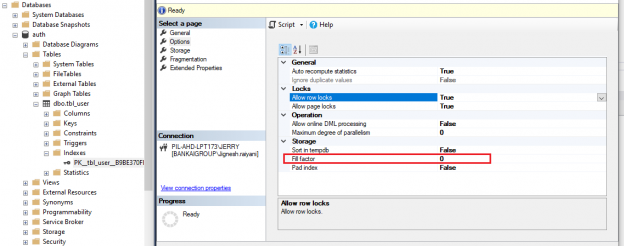
In this article, we will study in detail about the how SQL Server Index Fill factor works.
Read more »

This article is about techniques for optimizing the SQL Server indexes strategy. It is an appendix of the SQL index overview and strategy article in which I covered different areas like what indexes actually do, how to create them, and I briefly mentioned some index design guidelines. Furthermore, I also presented an example of how to design them by tuning and optimizing queries, so I’ve really tried to cover all but there is always more when it comes to SQL Server indexes.
Read more »
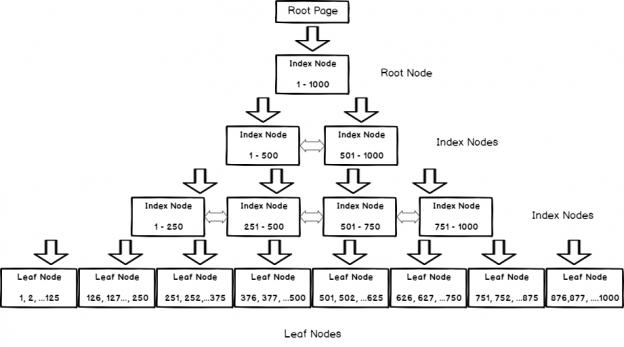
There are few topics so widely misunderstood and that generates such frequent bad advice as that of the decision of how to index a table. Specifically, the decision to use a heap over a clustered index is one where misinformation spreads quite frequently.
Read more »
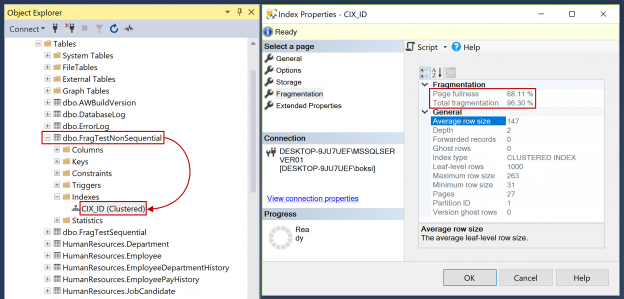
One of the main DBA responsibilities is to ensure databases to perform optimally. The most efficient way to do this is through indexes. SQL indexes are one of the greatest resources when it comes to performance gain. However, the thing about indexes is that they degrade over time.
Read more »© Quest Software Inc. ALL RIGHTS RESERVED. | GDPR | Terms of Use | Privacy