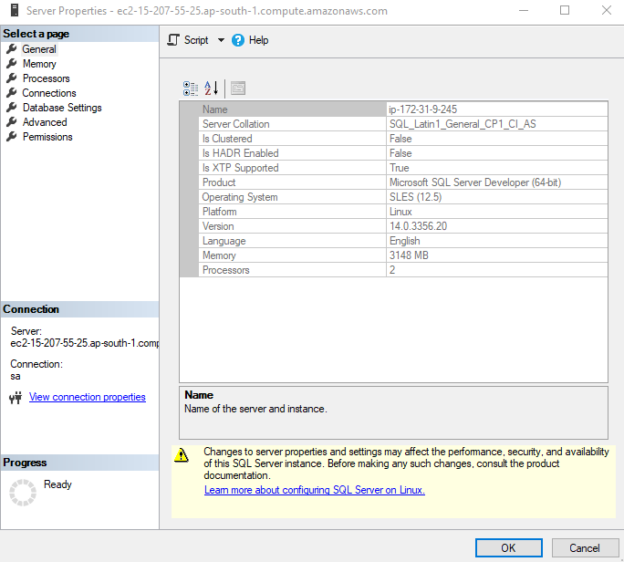
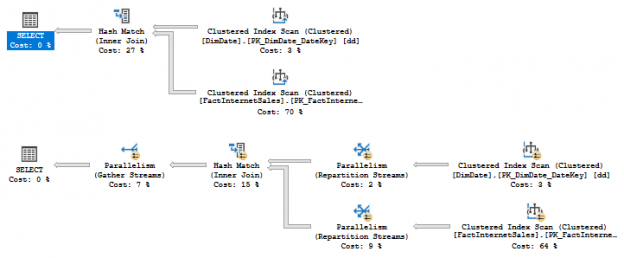
In this post, I continue the exploration of SQL Server 2017 and we will look at the nonclustered columnstore index updates.
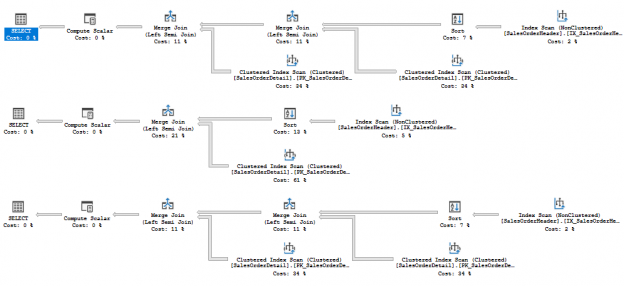
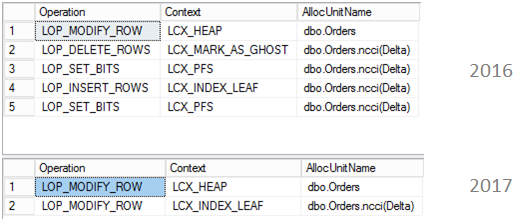
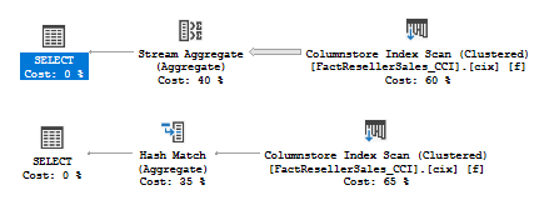
Columnstore index has some internal structures to support updates. In 2014 it was a Delta Store – to accept newly inserted rows (when there will be enough rows in delta store, server compresses it and switches to Columnstore row groups) and a Deleted Bitmap to handle deleted rows. In 2016 there are more internal structures, Mapping Index for a clustered Columnstore index to maintain secondary nonclustered indexes and a deleted buffer to speed up deletes from a nonclustered Columnstore index.
Updates were always split into insert + delete. But that is now changed, if a row locates in a delta store, now inplace updates are possible. Another change is that it is now possible to have a per row (narrow) plan instead of per index (wide) plan.
Let’s make some experiments.
Read more »