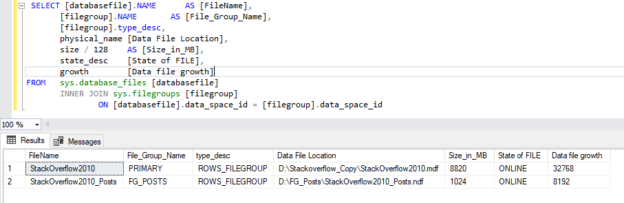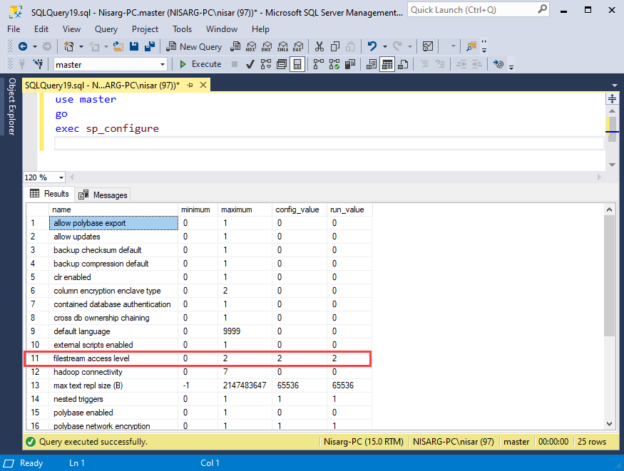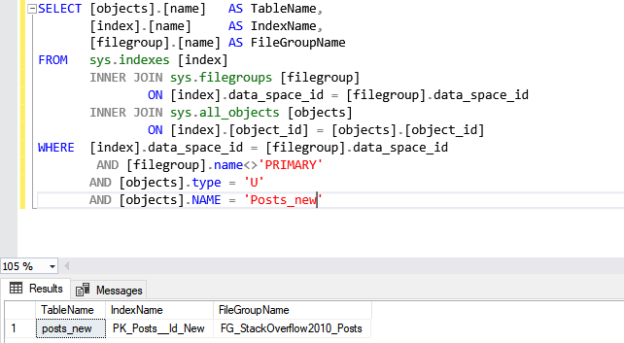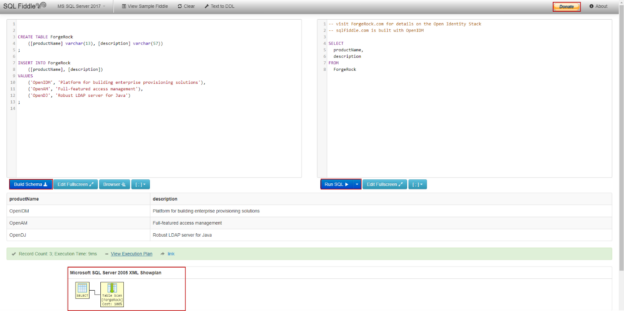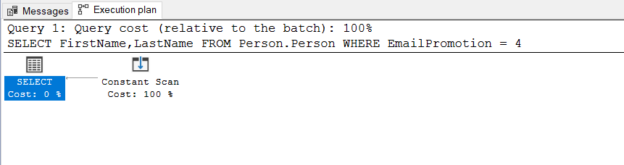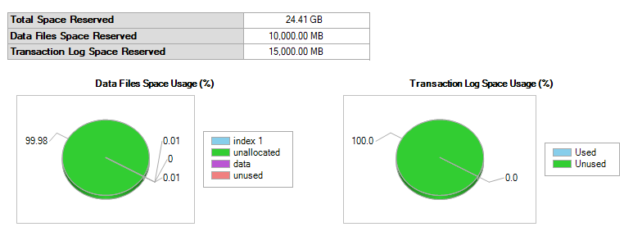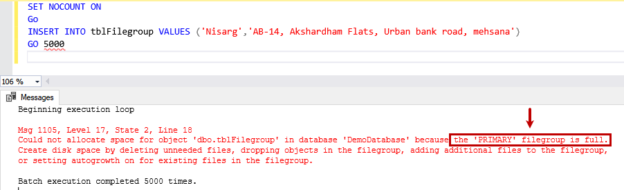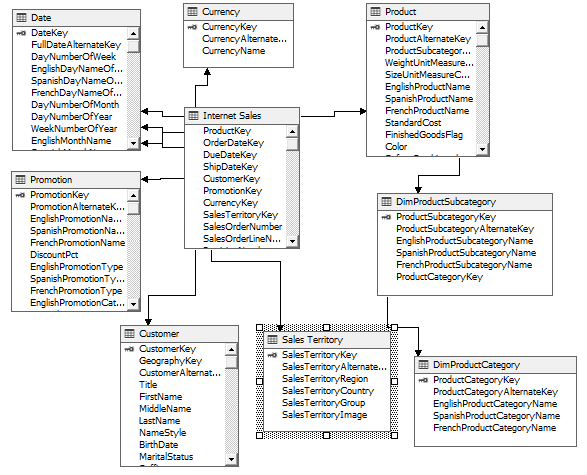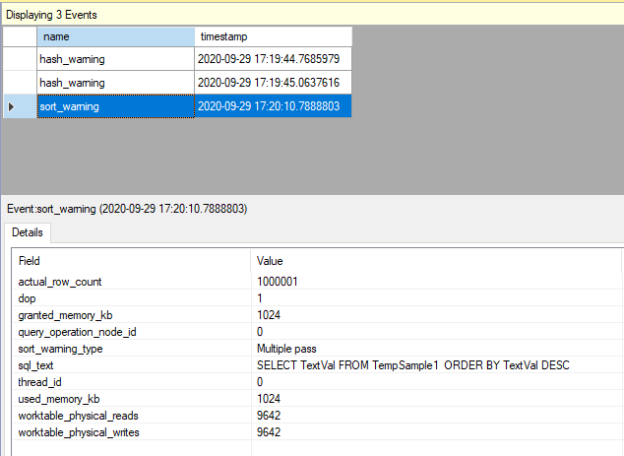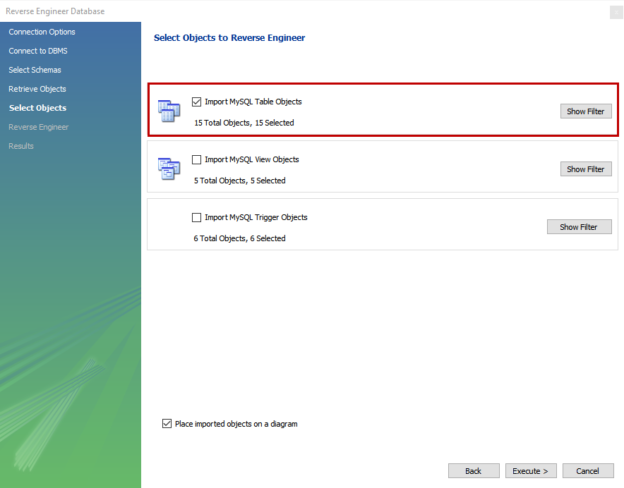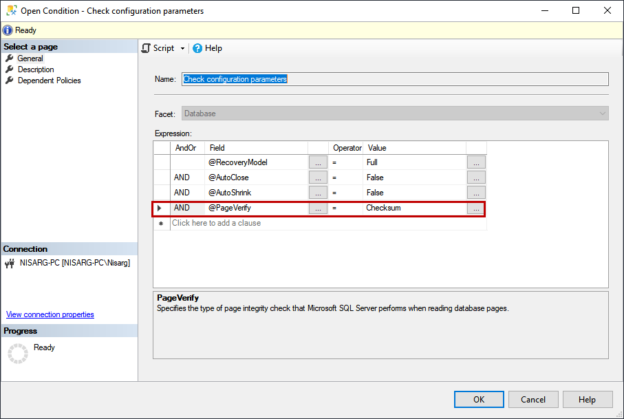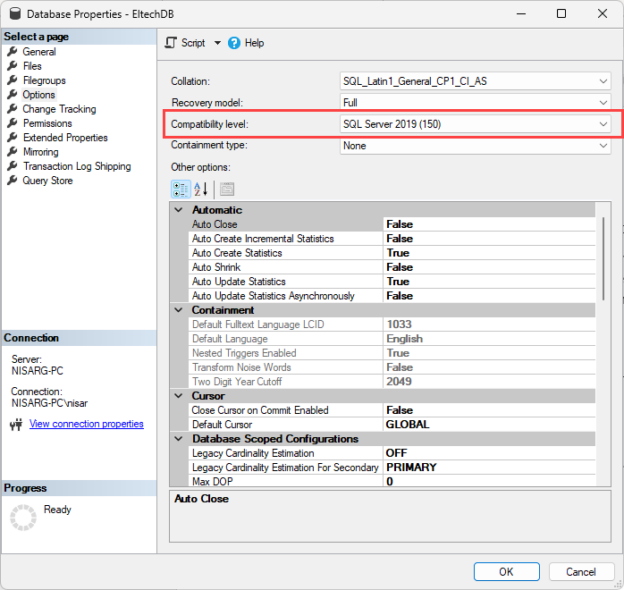
Compatibility level in SQL Server refers to a database property that determines the syntax and behavior of the database, allowing it to be compatible with earlier versions of SQL Server. Each version of SQL Server introduces new features, improvements, and changes to the query optimizer, which may affect how queries are executed and how results are returned.
Read more »