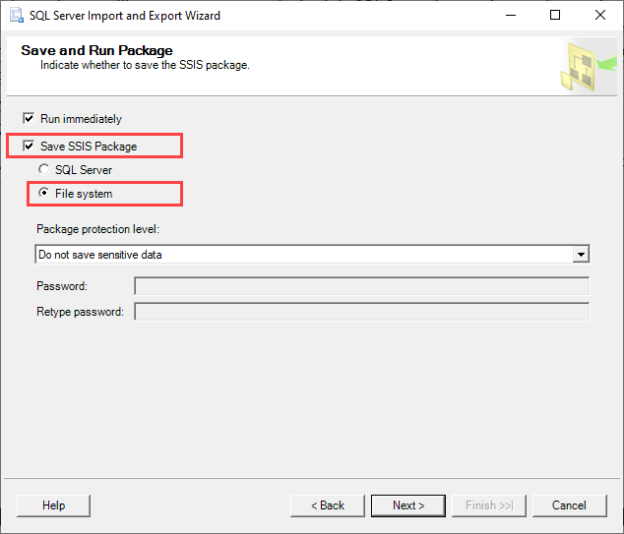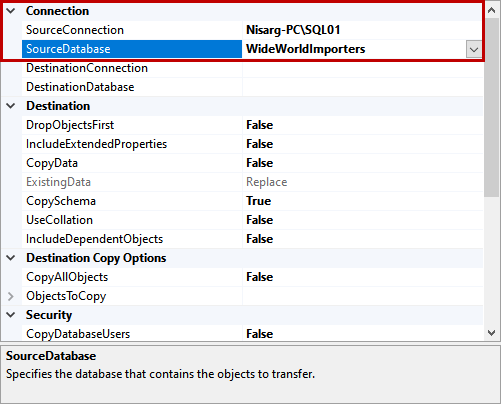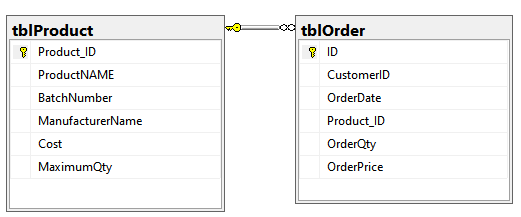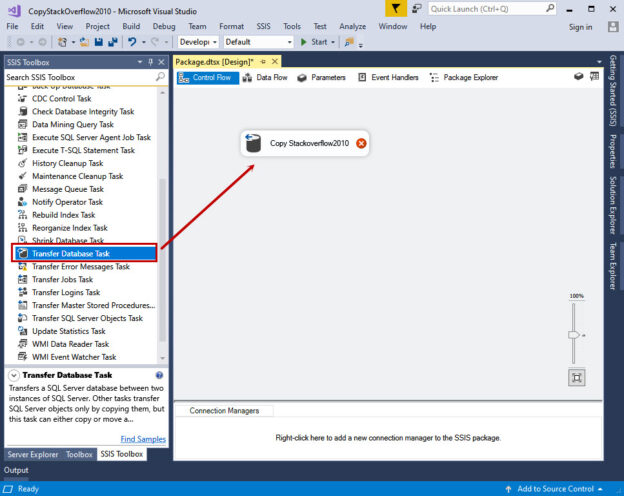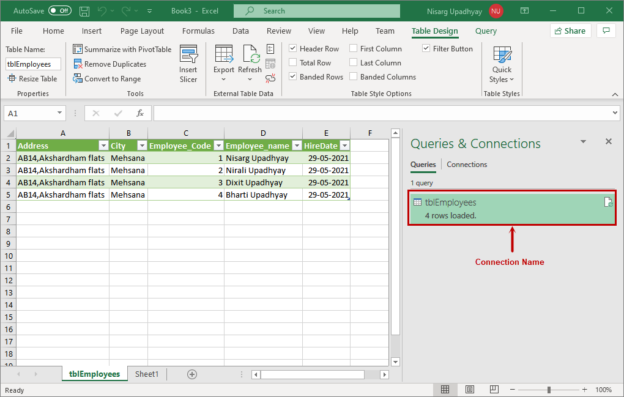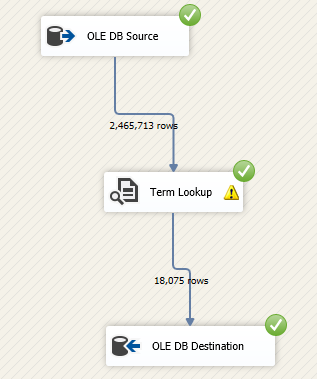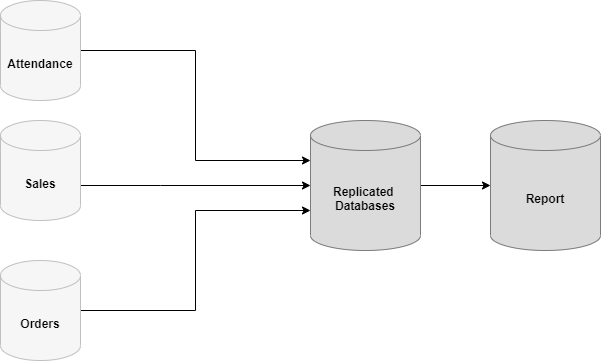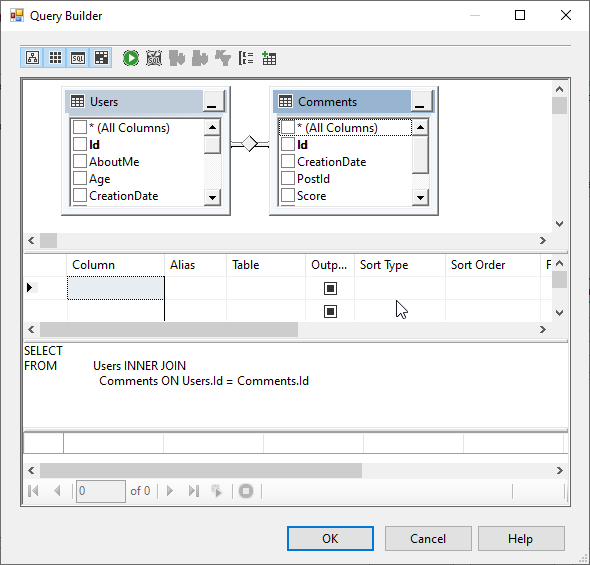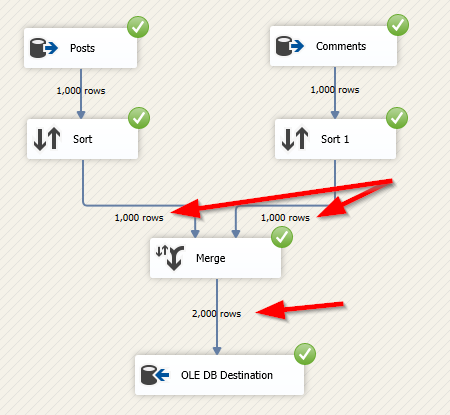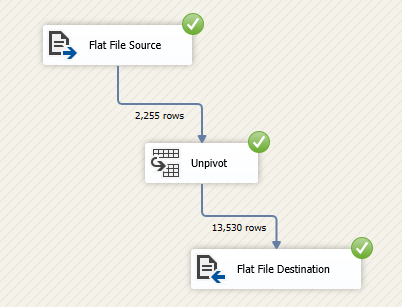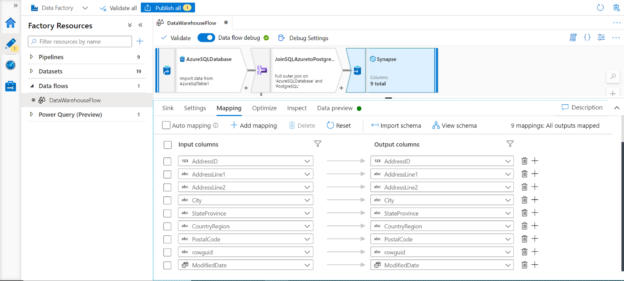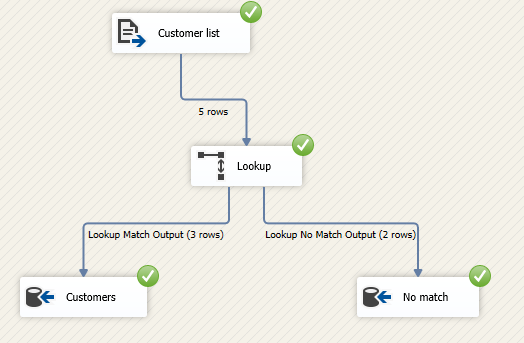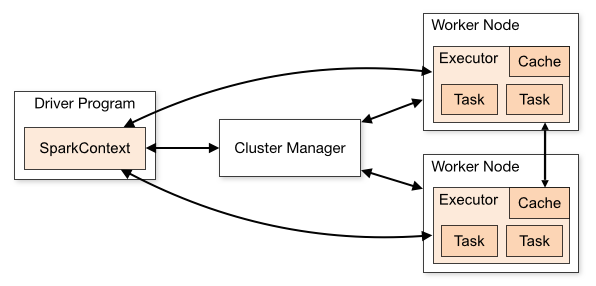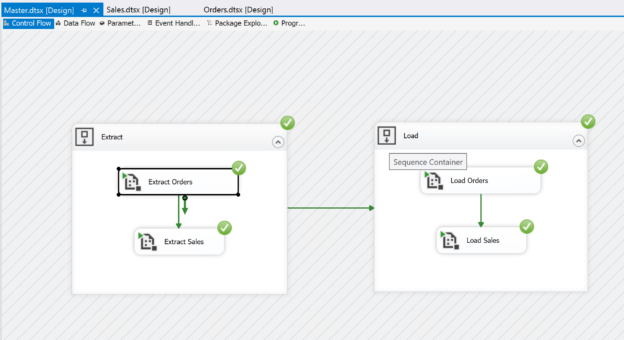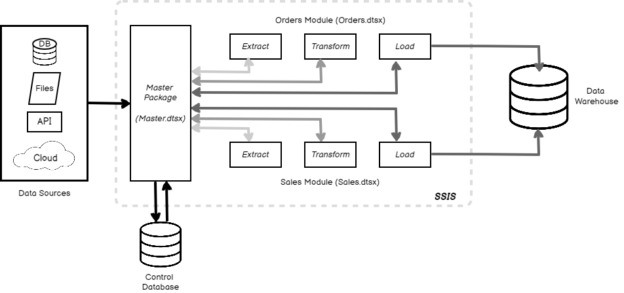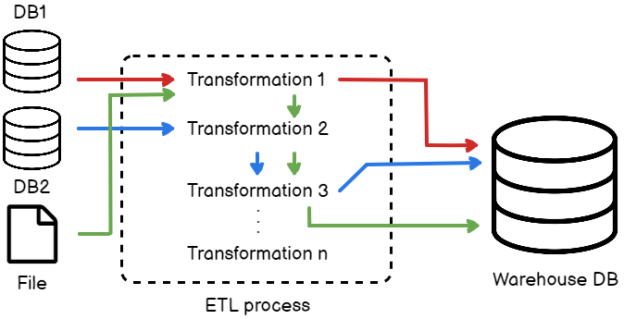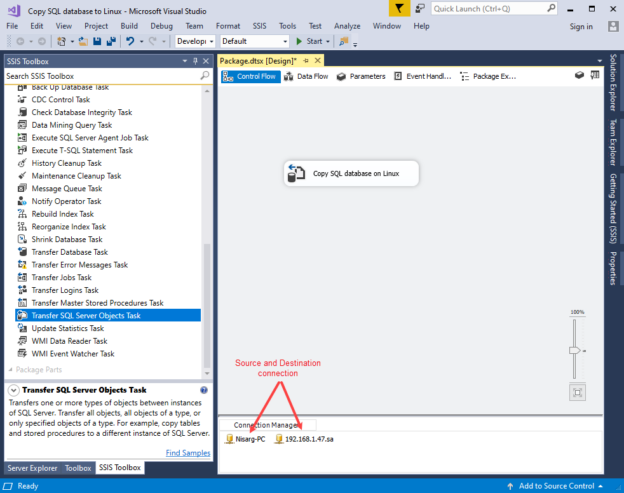
In this article, we are going to learn how to copy the SQL database created on different instances of the SQL Server. This article is the fourth article on Manage SQL Server on CentOS topic. In my previous article, Copy SQL Databases between Windows 10 and CentOS using the SQL Server import-export wizard, we learned how to copy data SQL database between windows 10 and CentOS Linux using the wizard.
Read more »