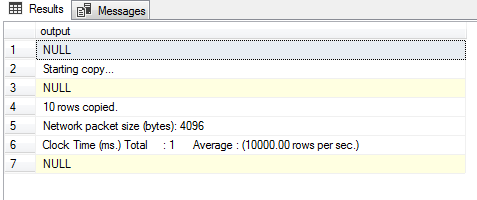
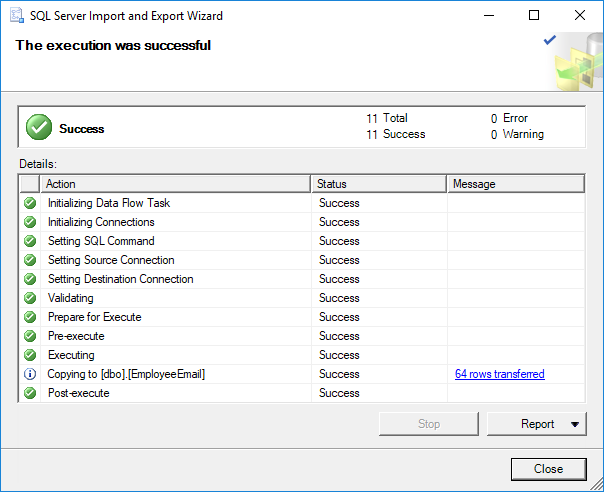
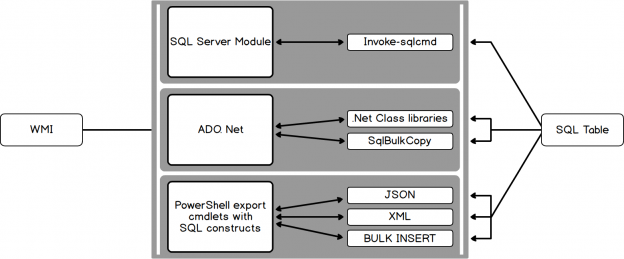
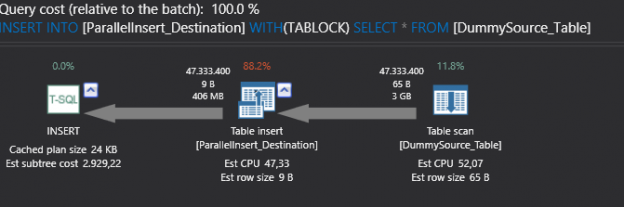
PowerShell has become the ultimate choice for many database administrators because of its efficient way of handling and managing automation in a simple, quick way. It’s built on .NET Framework and uses Object Models such as COM, ADSI, ADO, and WMI. PowerShell has replaced the traditional way of scripting that used many legacy scripting practices to monitor SQL instances.
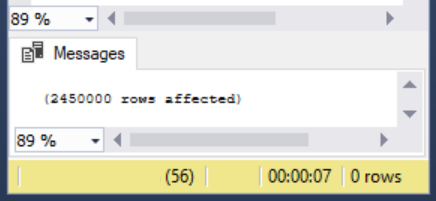
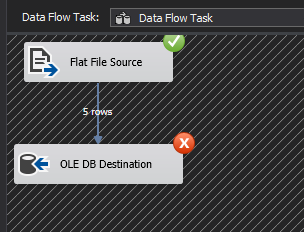
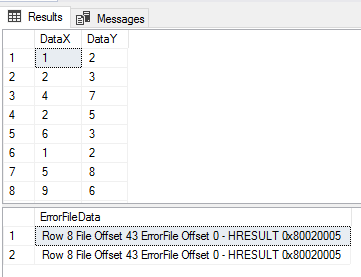
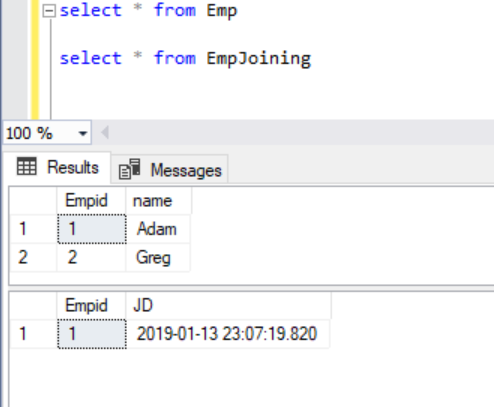
I’ve been asked on several occasions about how to store the output of PowerShell WMI data into the SQL table. The question comes up so frequently that I decided to write this article.
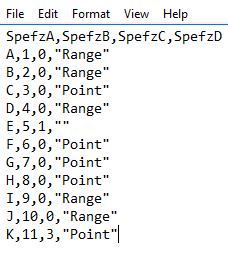
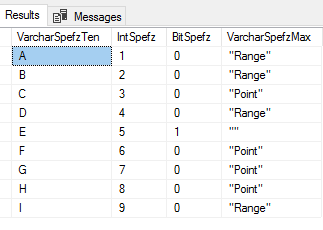
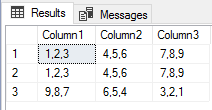
When sending data within a system (such as a PowerShell object to a cmdlet), the process is straightforward. However, with non-native data interchange (for instance, WMI to SQL), the process can potentially get complicated. Due to this, many purists suggest sticking to simple interchange formats, such as CSV, JSON or in some cases, XML.
Read more »