
Every data warehouse developer is likely to appreciate the significance of having surrogate keys as part of derived fields in your facts and dimension tables. Surrogate keys make it easy to define constraints, create and maintain indexes, as well as define relationships between tables. This is where the Identity property in SQL Server becomes very useful because it allows us to automatically generate and increment our surrogate key values in data warehouse tables. Unfortunately, the generating and incrementing of surrogate keys in versions of SQL Server prior to SQL Server 2017 was at times challenging and inconsistent by causing huge gaps between identity values. In this article, we take a look at one improvement made in SQL Server 2017 to reduce the creation of gaps between identity values.
Problem
Because versions of SQL Server prior to SQL Server 2016 used a memory cache to keep track of identity values to generate, database corruption or unexpected shutdowns of SQL Server instances led to the creation of gaps between identity values. In order to demonstrate the issue at hand, we make use of the following steps:
Step 1: Create the sample table
In this step, we create a table that will store a list of ApexSQL products. Script 1 shows a create table statement for the [dbo].[ApexSQL_Products] table that will be used to store our product list. Furthermore, the script also indicates that [ProductID] is our surrogate key that makes use of the Identity property.
|
1 2 3 4 5 6 |
CREATE TABLE [dbo].[ApexSQL_Products] ([ProductID] INT IDENTITY(1, 1) NOT NULL, [ProductName] [VARCHAR](50) NOT NULL, [DateInserted] DATETIME2 DEFAULT(GETDATE()) NOT NULL ) ON [PRIMARY]; |
Step 2: Populate the sample table
The next step involves populating the newly created table with 3 out of the 6 ApexSQL products as shown in Script 2.
|
1 2 |
INSERT INTO [dbo].[ApexSQL_Products]([ProductName]) VALUES('ApexSQL Compare'), ('ApexSQL Complete'), ('ApexSQL Refactor'); |
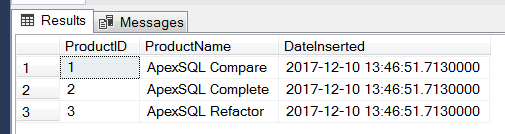
A preview of our [dbo].[ApexSQL_Products] table indicates that the execution of Script 2 was successful as the 3 inserted products appear in the table as shown in Figure 1.
Step 3: Shut down SQL Server
Having inserted 3 of the 6 ApexSQL products, we forcibly shut down our SQL Server instance without performing database checkpoints by using the command shown in Script 3.
|
1 |
SHUTDOWN WITH NOWAIT; |
Step 4: Resume table inserts
In this step, we restart the SQL Server instance that we stopped in step 3 and we then do an insert of the remaining ApexSQL products using the syntax shown in Script 4.
|
1 2 |
INSERT INTO [dbo].[ApexSQL_Products]([ProductName]) VALUES('ApexSQL Search'), ('ApexSQL Plan'), ('ApexSQL Propagate'); |
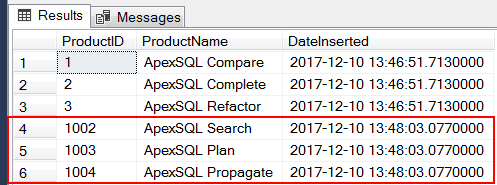
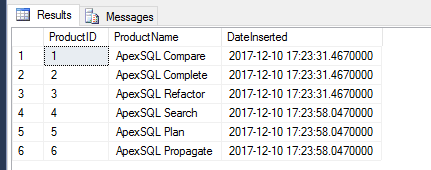
Following the execution of Script 4, a preview of our [dbo].[ApexSQL_Products] table in Figure 2 confirms that the additional products we successfully inserted. However, it can also be noticed that, following an unexpected shutdown of our SQL Server instance, the identity values allocated for ProductID jumps from 3 to 1002.
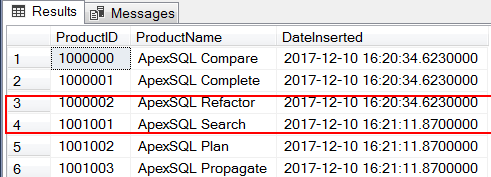
It looks like whenever a SQL Server instance goes through an unexpected shutdown, the next identity value to be generated will be a 1000 more than the previously generated value. For instance, say we drop and recreate our [dbo].[ApexSQL_Products] table but this time around our identity starts at 1 000 000 and is incremented by 1, as soon as we complete steps 2-4, a latest preview of our table in Figure 3 indicates that the value for the 4th row jumps from 1000002 to 1001001.
Solution
Database-scoped configurations introduced in SQL Server 2016 has luckily been extended in SQL Server 2017 to include IDENTITY_CACHE option for enabling and disabling of caching of identity values. Thus, ensuring that database corruption or unexpected SQL Server shutdown does not create gaps between last generated identity value and the next identity value. By default, caching of identity values is enabled in SQL Server 2017.
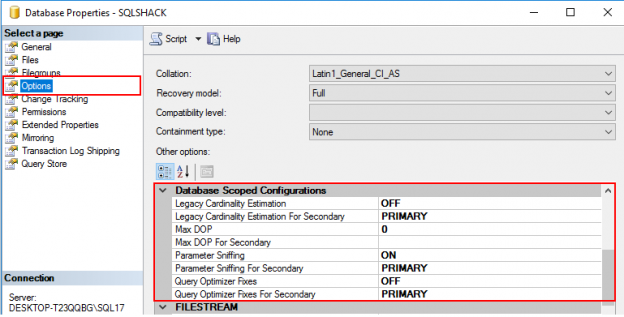
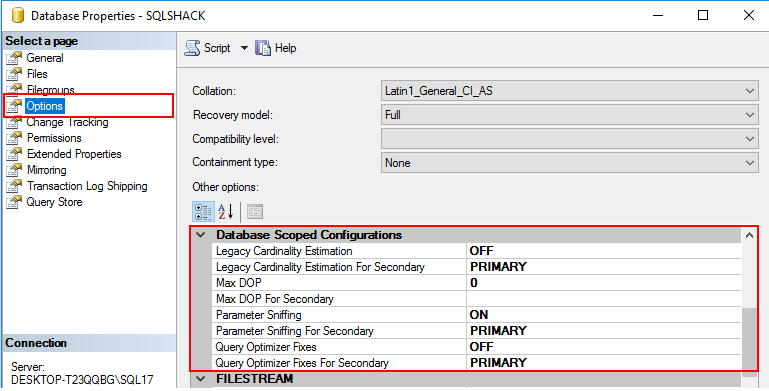
Whilst setting of database scoped configurations such as specifying Max DOP and Parameter Sniffing could be performed directly in SSMS by navigating to database Options > Database Scoped Configurations (as shown in Figure 4), the setting of IDENTITY_CACHE option in SQL Server 2017 can only be done through T-SQL commands.
Script 5 shows a T-SQL command for disabling identity cache in SQL Server 2017
|
1 2 |
ALTER DATABASE SCOPED CONFIGURATION SET IDENTITY_CACHE = OFF GO |
The enabling and disabling of identity cache occurs instantaneously without the need to restart the SQL Server service. As a result of successfully executing Script 5, when we recreate our target table and populate it according to steps 1-4, we end up with a surrogate key that doesn’t have gaps in between as shown in Figure 5.
IDENTITY_CACHE not quite the silver bullet
Although disabling of identity caching in SQL Server 2017 helps deal with gaps in identity values, it must be noted that database corruption and unexpected SQL Server shutdowns are not the only causes for gaps in identity values. Some other causes relate to batch INSERT statement failures that, despite the transaction being rolled back, the allocated identity value is never rolled back thus causing a gap.
To demonstrate this issue, let’s add a unique non-clustered index to the table we created using Script 1 as shown in Script 6.
|
1 2 |
CREATE UNIQUE NONCLUSTERED INDEX [NCI_IDX] ON [dbo].[ApexSQL_Products]([ProductName] ASC) WITH(PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]; GO |
If we try to insert product ApexSQL Complete again, we receive an error message citing a violation of our unique non-clustered index as shown in below:
|
1 2 3 |
Msg 2601, Level 14, State 1, Line 19 Cannot insert duplicate key row in object 'dbo.ApexSQL_Products' with unique index 'NCI_IDX'. The duplicate key value is (ApexSQL Complete). The statement has been terminated |
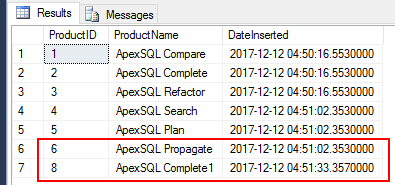
However, if we modify our insert script by adding 1 at the end of product ApexSQL Complete, the INSERT statement successfully commits. Yet, if you have a look at the last identity value generated for our surrogate key, you will notice the jump from 6 to 8, as shown in Figure 6. Admittedly, the gap between last and next identity value is no longer a 1000 like we had when we unexpectedly shut down a server but it is still a jump.
Summary
The new IDENTITY_CACHE feature in SQL Server 2017 significantly improves the consistency of generating identity values for data-repository environments such as a SQL Server-based data warehouse. Yet, just because you have disabled the caching of identity values does not necessarily mean that you are not going to have gaps between your identity values as unsuccessful INSERT statements continue to create a jump between last and next identity values.

Sifiso's LinkedIn profile
View all posts by Sifiso W. Ndlovu