
Introduction
Graph database
A graph database is a type of database whose concept is based on nodes and edges.
Graph databases are based on graph theory (a graph is a diagram of points and lines connected to the points). Nodes represent data or entity and edges represent connections between nodes. Edges own properties that can be related to nodes. This capability allows us to show more complex and deep interactions between our data. Now, to explain this interaction we will show it in a simple diagram
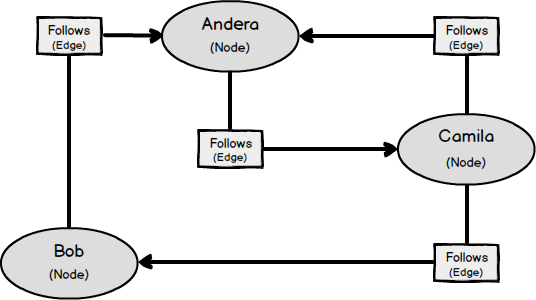
The diagram above shows the basic model of the graph database concept.
The nodes are Andera, Bob and Camila and Follows (edges) provide connections between nodes. This database model cannot be treated as an alternative to a relational database model but faced with some specific problems the graph database model can be alternative and effective.
If you look at the diagram closely, maybe you can design this data model in a relational database by joins but imagine that if you have a lot of nodes and edges then how many joins will you need? And, another consideration could be how this design would perform? For this reason, when handling some business problems we need a graph database.
In the context of social media, for example, there are a lot of social actions like connect, follow etc. and each social action creates a mark. When we combine these marks, it looks like a spider’s web. The graph database model is ideally suited to store this type of data.
SQL Server 2017 and graph database
Microsoft announced graph database in SQL Server 2017. This feature allows us to create graph data models. SQL Server 2017 and graph database architecture contains two types of tables. They include the node table and edge table.
We can demonstrate it with a diagram.
NODE TABLE: Node table defines entity in a graph model.
|
1 2 3 4 5 6 |
DROP TABLE IF EXISTS Users CREATE TABLE Users (ID INTEGER PRIMARY KEY, NickName VARCHAR(100)) AS NODE; INSERT INTO Users VALUES (1,'Andera'),(2,'Bob'),(3,'Camila') SELECT * FROM Users |
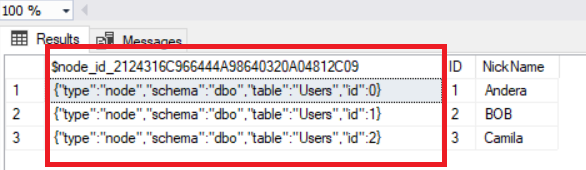
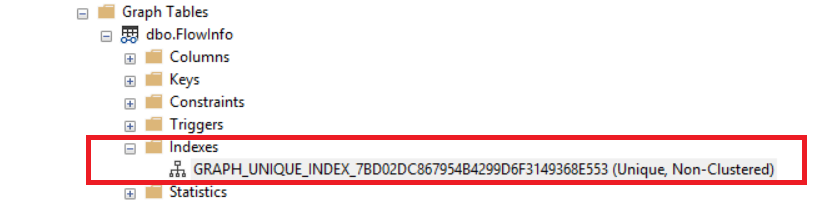
$NODE_ID: It is an important column in a node table. When a node table is created, this calculated field is automatically generated by the SQL engine. This field describes a given node uniquely. After we create the objects, we will look at the objects through the object explorer in Management Studio. You will see a new folder named as Graph Tables. This folder contains all graph tables.
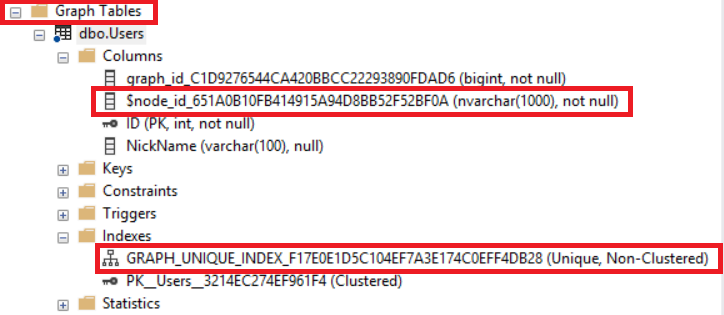
SQL Server adds a GUID to the end of $NODE_ID column’s name but we can also use this column without GUID extension (pseudo-column). If we do not create a unique constraint or index on $NODE_ID column, the SQL engine automatically creates unique, non-clustered indexes when the node table is created. This guarantees the uniqueness of $NODE_ID column.
EDGE TABLE: An edge table defines connection between node table entities
|
1 2 3 |
DROP TABLE IF EXISTS FlowInfo CREATE TABLE FlowInfo AS EDGE SELECT * FROM FlowInfo |

When we create an edge table, the SQL engine creates three implicit columns.
$EDGE_ID: It defines unique edge in edge table. For this reason, the SQL engine automatically creates a unique non clustered index
$FROM_ID: It defines the starting point for the entity of edge.
$TO_ID: It defines the end point for the entity of edge.
Now we will define an edge connection to the edge table.
The insert statement for the step when Bob follows Andera is
|
1 2 3 4 |
INSERT INTO FlowInfo ($from_id ,$to_id ) VALUES ( (SELECT $node_id from Users where ID=2) ,(SELECT $node_id from Users where ID=1)) |
The insert statement for the step when Camila follows Andera is
|
1 2 3 4 |
INSERT INTO FlowInfo ($from_id ,$to_id ) VALUES ( (SELECT $node_id from Users where ID=3) ,(SELECT $node_id from Users where ID=1)) |
The insert statement for the step when Camila follows Bob is
|
1 2 3 4 5 |
INSERT INTO FlowInfo ($from_id ,$to_id ) VALUES ( (SELECT $node_id from Users where ID=3) ,(SELECT $node_id from Users where ID=2)) select * from FlowInfo |

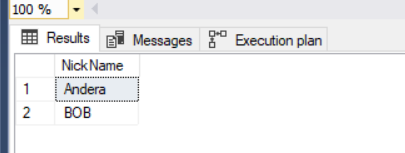
The following query explains Camila’s connections
|
1 2 3 4 |
SELECT UsersFol.NickName FROM Users Users, FlowInfo, Users UsersFol WHERE MATCH(Users-(FlowInfo)->UsersFol) AND Users.NickName = 'Camila'; |
In this query we saw some new T-SQL syntax “MATCH”, “-“, “->”.
“-“sign represents $FROM_ID and “->” sign represents $TO_ID field on edge table.
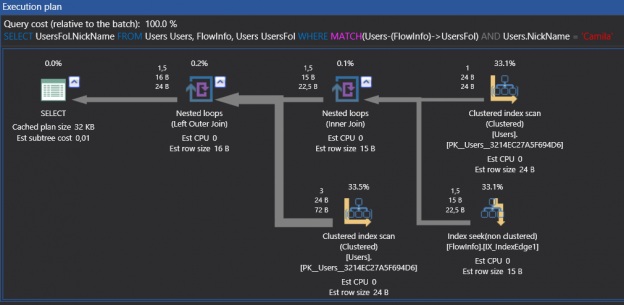
Have a look at the execution plan of this query
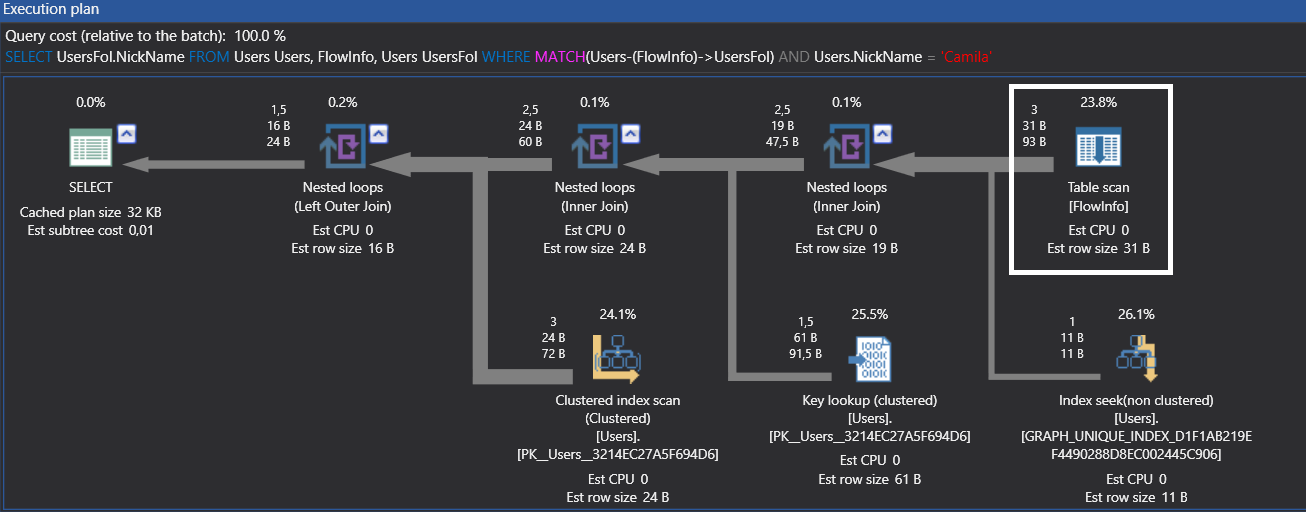
There is a table scan in the execution plan of this query because there isn’t any index in the $FROM_ID and $TO_ID columns in FlowInfo edge table. We will create a unique non clustered index in these columns and we will look at the execution plan again
|
1 2 3 4 5 |
CREATE UNIQUE NONCLUSTERED INDEX IX_IndexEdge1 ON [dbo].[FlowInfo] ( $from_id,$to_id )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] |
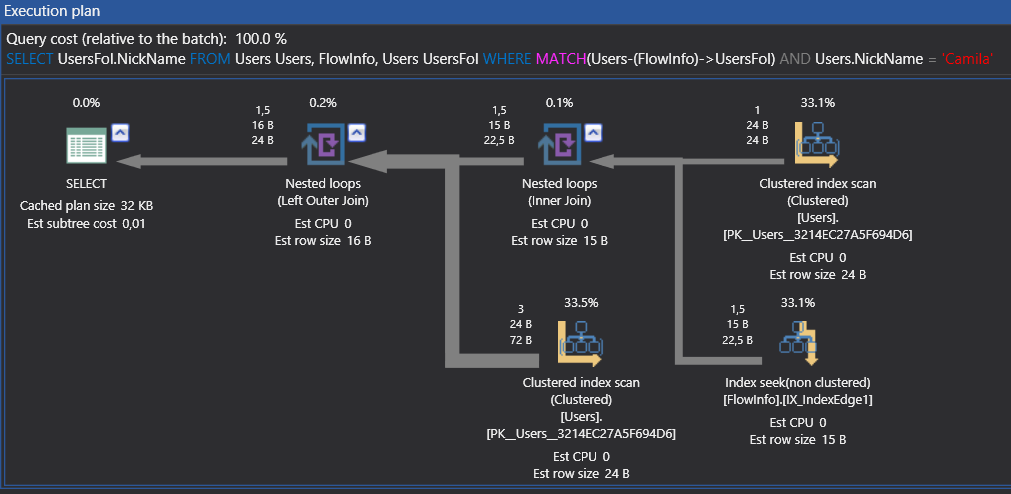
After adding an index and then avoiding table scans from the key lookup and nested loop we can see its performance. In case of having a heavy read request on a graph model, we have to add an index.
Now, we will create a little bit more complex example using the graph database model. Imagine that we have an online book application and customers. Customers can read books online and can connect with other customers. And while using the application we want to show a pop-up to our customers that if your connections like this author or authors
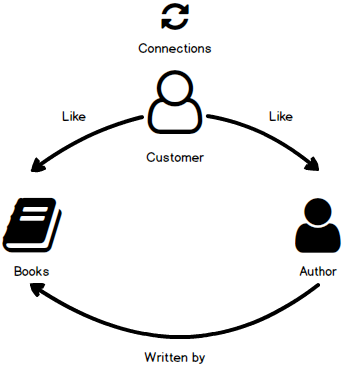
After this, we will create our graph database model objects
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
DROP TABLE IF EXISTS Customer CREATE TABLE Customer (ID INT PRIMARY KEY IDENTITY(1,1), CustName VARCHAR(100)) AS NODE INSERT INTO Customer VALUES('James'),('Brian'),('Jason'),('Edward') DROP TABLE IF EXISTS Author CREATE TABLE Author (ID INT PRIMARY KEY IDENTITY(1,1), AuthorName VARCHAR(100)) AS NODE INSERT INTO Author VALUES('William Shakespeare'),('William Golding'),('Fyodor Dostoyevsky'),('Kathryn Stockett') DROP TABLE IF EXISTS Books CREATE TABLE Books (ID INT PRIMARY KEY IDENTITY(1,1), BookName VARCHAR(100)) AS NODE INSERT INTO Books VALUES('Romeo and Juliet'),('Lord of the Flies'),('Crime and Punishment'),('The Help') |
In the next step, edge tables will be created and connections between nodes are defined
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
DROP TABLE IF EXISTS CustomerConnect CREATE TABLE CustomerConnect AS EDGE --James connects Jason INSERT INTO CustomerConnect VALUES ((SELECT $node_id from Customer where ID=1),(SELECT $node_id from Customer where ID=3)) --Brian connects Jason INSERT INTO CustomerConnect VALUES ((SELECT $node_id from Customer where ID=2),(SELECT $node_id from Customer where ID=3)) --Brian connects Edward INSERT INTO CustomerConnect VALUES ((SELECT $node_id from Customer where ID=2),(SELECT $node_id from Customer where ID=4)) DROP TABLE IF EXISTS CustomerLikeAuthor CREATE TABLE CustomerLikeAuthor AS EDGE --James Likes William Shakespeare INSERT INTO CustomerLikeAuthor VALUES ((SELECT $node_id from Customer where ID=1),(SELECT $node_id from Author where ID=1)) --Edward Likes Kathryn Stockett INSERT INTO CustomerLikeAuthor VALUES ((SELECT $node_id from Customer where ID=4),(SELECT $node_id from Author where ID=4)) DROP TABLE IF EXISTS CustomerLikeBooks CREATE TABLE CustomerLikeBooks AS EDGE --James Likes Crime and Punishment INSERT INTO CustomerLikeBooks VALUES ((SELECT $node_id from Customer where ID=1),(SELECT $node_id from Books where ID=3)) --Edward likes The Help INSERT INTO CustomerLikeAuthor VALUES ((SELECT $node_id from Customer where ID=4),(SELECT $node_id from Books where ID=4)) DROP TABLE IF EXISTS AuthorWriteBooks CREATE TABLE AuthorWriteBooks AS EDGE INSERT INTO AuthorWriteBooks VALUES ((SELECT $node_id from Books where ID=1),(SELECT $node_id from Author where ID=1)) INSERT INTO AuthorWriteBooks VALUES ((SELECT $node_id from Books where ID=2),(SELECT $node_id from Author where ID=2)) INSERT INTO AuthorWriteBooks VALUES ((SELECT $node_id from Books where ID=3),(SELECT $node_id from Author where ID=3)) INSERT INTO AuthorWriteBooks VALUES ((SELECT $node_id from Books where ID=4),(SELECT $node_id from Author where ID=4)) |
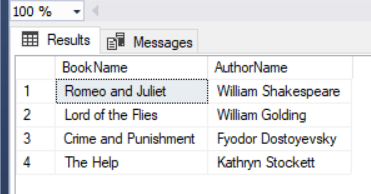
This query shows the book with its author’s name in the adjacent column to it
|
1 2 3 4 |
SELECT Books.BookName ,Author.AuthorName FROM Author,AuthorWriteBooks,Books WHERE MATCH(Books-(AuthorWriteBooks)->Author) |
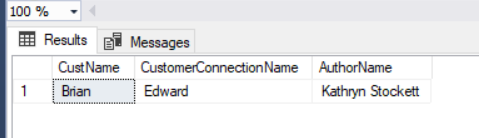
This query gives an answer to our question mentioned above
|
1 2 3 4 5 |
SELECT CustTo.CustName ,CustFrom.CustName AS CustomerConnectionName,Author.AuthorName FROM Customer CustTo, CustomerConnect CustCon ,Customer CustFrom ,CustomerLikeAuthor ,Author where MATCH (CustTo-(CustCon)->CustFrom-(CustomerLikeAuthor)->Author) and CustTo.CustName='Brian' |
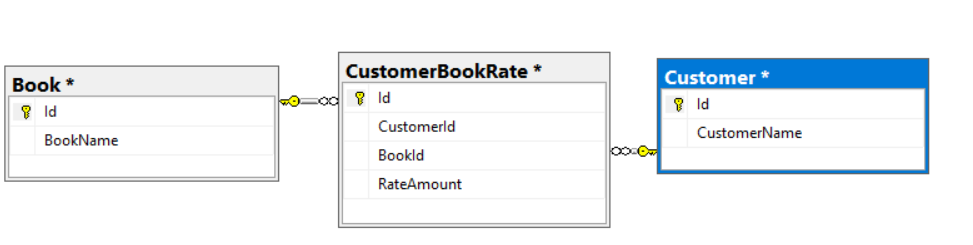
Graph database model or relational database model
The major difference between these two database models is how they define relations within your data. In relational database model we can create relationships with primary or foreign keys but, on the other hand, in a graph database model we define connections (edges) and we can add properties to these connections (edges). Let us differentiate it with an example.
Imagine that our customers rank books. We want to store this rank point of books. If we create this model in relational model it will look like:
Now, as in case of graph model
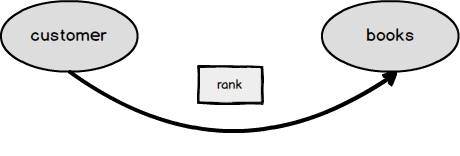
Now we will create node and edge tables. The key point here is that we will create our edge table with a rank property.
The node table is defined as follows:
|
1 2 3 4 5 6 7 8 9 |
DROP TABLE IF EXISTS Customer CREATE TABLE Customer (ID INT PRIMARY KEY IDENTITY(1,1), CustName VARCHAR(100)) AS NODE INSERT INTO Customer VALUES('James'),('Brian'),('Jason'),('Edward') DROP TABLE IF EXISTS Books CREATE TABLE Books (ID INT PRIMARY KEY IDENTITY(1,1), BookName VARCHAR(100)) AS NODE INSERT INTO Books VALUES('Romeo and Juliet'),('Lord of the Flies'),('Crime and Punishment'),('The Help') |
The edge table with rank property is defined as follows
|
1 2 3 |
CREATE TABLE CustomerBookRate(ID INT PRIMARY KEY IDENTITY(1,1) ,RankAmount SMALLINT) AS EDGE SELECT * FROM CustomerBookRate |

Firstly, we will insert data in the edge table with connections and rank amount:
“Brian” gives “Lord of the Flies” “5” points.
|
1 2 3 |
INSERT INTO CustomerBookRate VALUES( (SELECT $node_id from Customer where ID =2) ,(SELECT $node_id from Books where ID =2),5) |
After this, we will generate some dummy data
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
INSERT INTO CustomerBookRate VALUES( (SELECT $node_id from Customer where ID =1) ,(SELECT $node_id from Books where ID =2),3) INSERT INTO CustomerBookRate VALUES( (SELECT $node_id from Customer where ID =1) ,(SELECT $node_id from Books where ID =4),3) INSERT INTO CustomerBookRate VALUES( (SELECT $node_id from Customer where ID =1) ,(SELECT $node_id from Books where ID =1),2) INSERT INTO CustomerBookRate VALUES( (SELECT $node_id from Customer where ID =4) ,(SELECT $node_id from Books where ID =1),2) select * from CustomerBookRate |

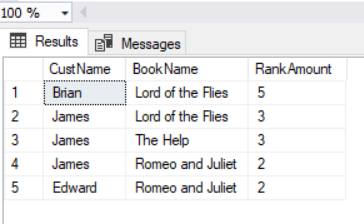
These queries will show us which customer likes which book and which book is highly ranked
|
1 2 |
select Customer.CustName,Books.BookName,CustomerBookRate.RankAmount from Customer,CustomerBookRate,Books where MATCH (Customer-(CustomerBookRate)->Books) |
|
1 2 3 |
select Books.BookName,sum(CustomerBookRate.RankAmount) from Customer,CustomerBookRate,Books where MATCH (Customer-(CustomerBookRate)->Books) group by Books.BookName |
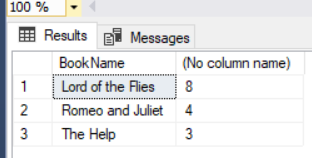
Another major difference is that the graph database model happens to give better performance in heavy connections. Like, in some business problems, the application needs a complex hierarchy. A graph database would be a compelling option in that case because graph database offers better performance and simple data modeling.
There is the possibility of finding other differences as well but generally these two topics are discussed.
Conclusions
In this article, we discussed graph database and SQL Server 2017 graph database features. SQL Server graph database is a fantastic feature. We can implement both graph database and relational database models in the same database engine. This hybrid architecture allows us to use SQL Server engine capabilities with a graph database. T-SQL syntax support graph database queries. Graph database does some limitations notwithstanding these limitations there are many exceptional features in SQL Server 2017, that make it a compelling technology to consider.

Most of his career has been focused on SQL Server Database Administration and Development. His current interests are in database administration and Business Intelligence. You can find him on LinkedIn.
View all posts by Esat Erkec
- SQL Performance Tuning tips for newbies - April 15, 2024
- SQL Unit Testing reference guide for beginners - August 11, 2023
- SQL Cheat Sheet for Newbies - February 21, 2023