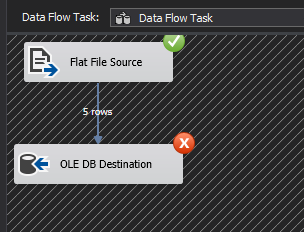
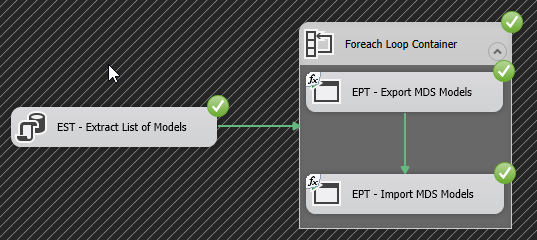
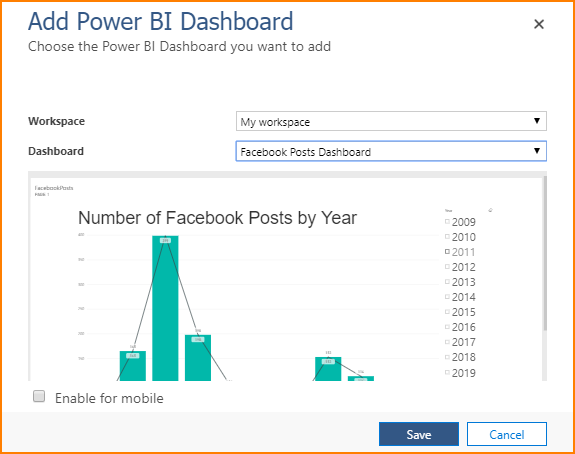
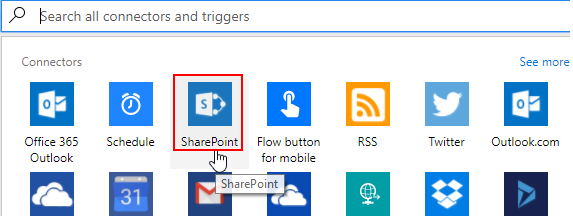
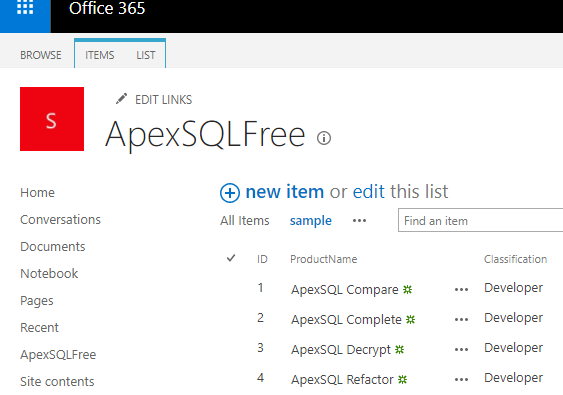
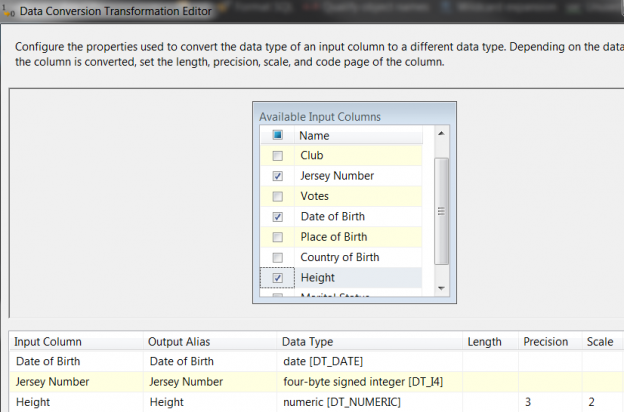
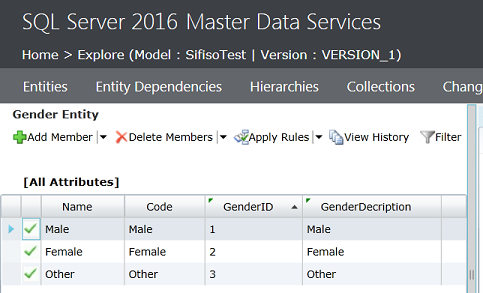
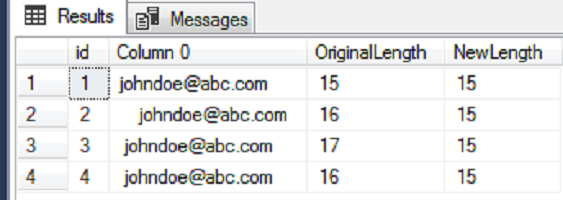
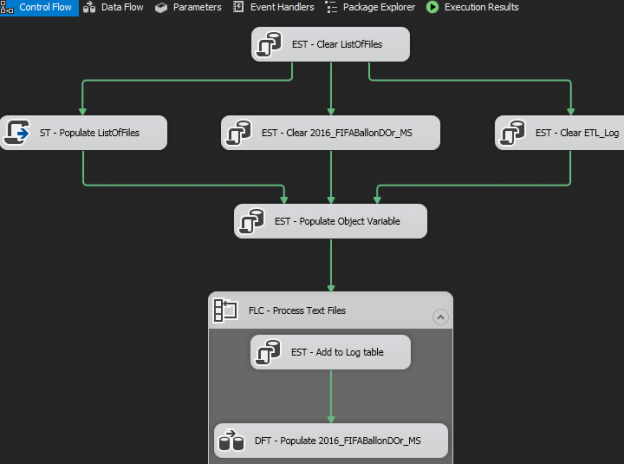
Data extraction is a pivotal part of any business process particularly when it comes to running reports and facilitating business decision-making. In the article, How to configure OData SSIS Connection for SharePoint Online, I covered data extraction off a SharePoint Online list using SQL Server Integration Services (SSIS). You would have noticed in the aforementioned article that getting SSIS to successfully integrate with SharePoint Online lists can be a laborious exercise, especially if you haven’t installed the correct SharePoint SDK files. Thus, in business environments where business and Power Users have more control of data extraction processes, SSIS could get complicated for an ordinary business user to operate. Therefore, given the nature of our source data and the platform in which it resides, ETL architects and developers alike may need to find alternative ETL tools to SSIS. This brings me to Microsoft Flow which could be one possible alternative to using SSIS for data extraction. Microsoft Flow is part of Office 365 applications and just like SharePoint Online, is a cloud-based application that is freely available, easier to operate and effortlessly integrates with – amongst other applications – SharePoint Online. The aim of this article is to demonstrate the convenience of extracting data from one SharePoint Online list to another using Microsoft Flow.
Read more »