Introduction
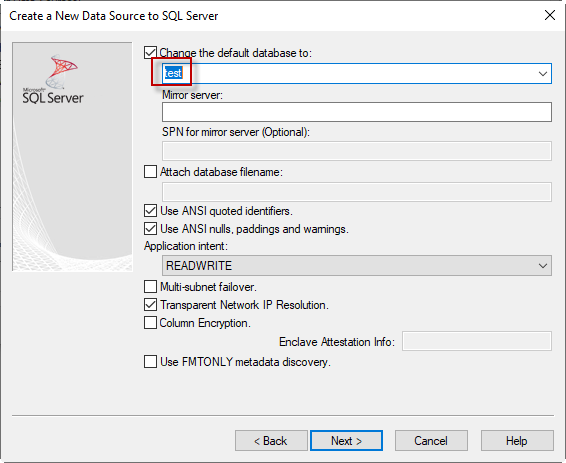
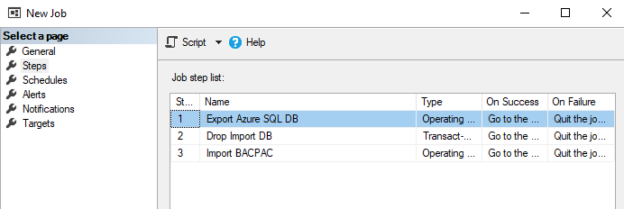
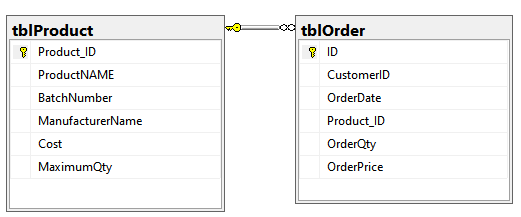
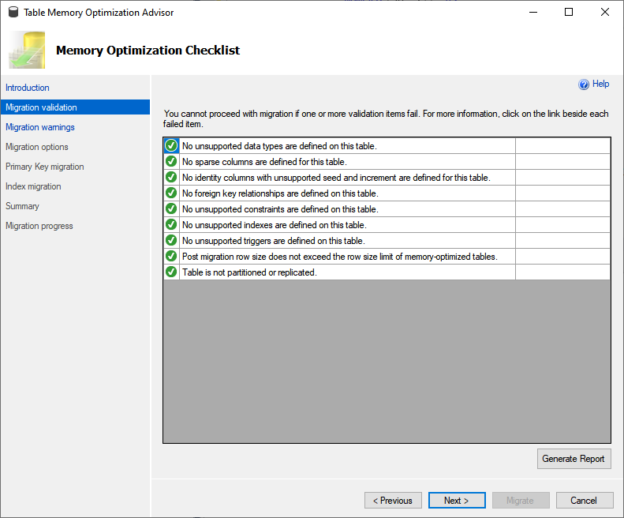
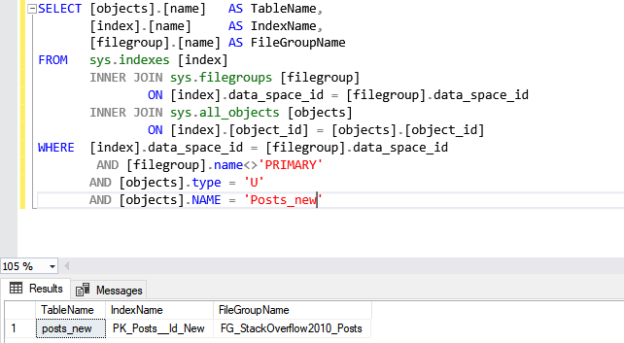
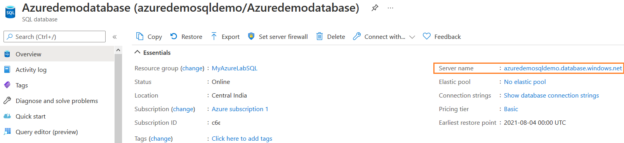
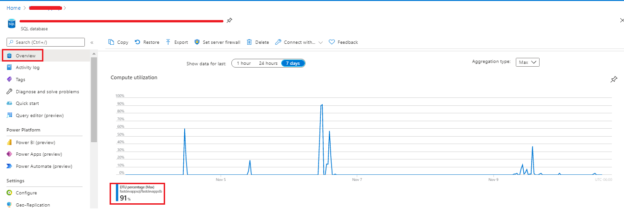
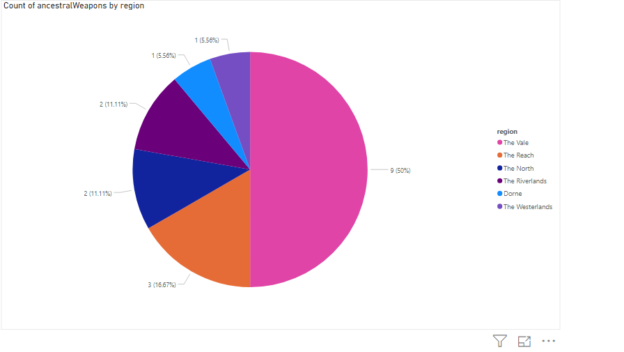
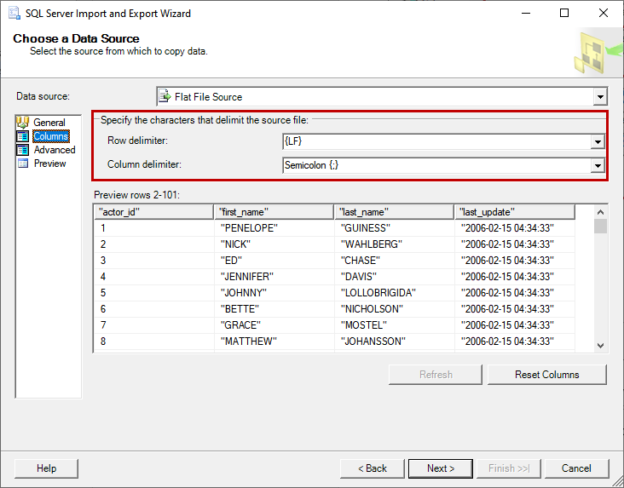
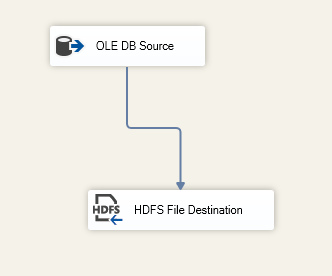
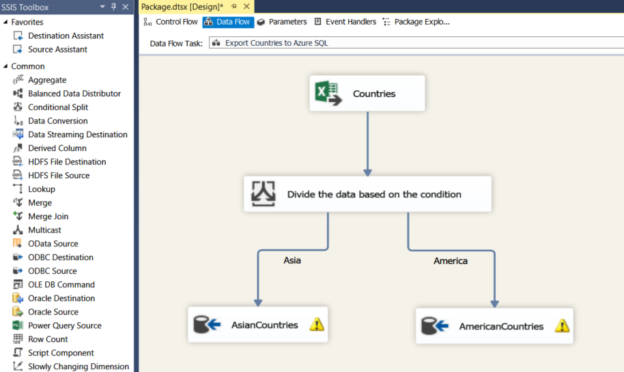
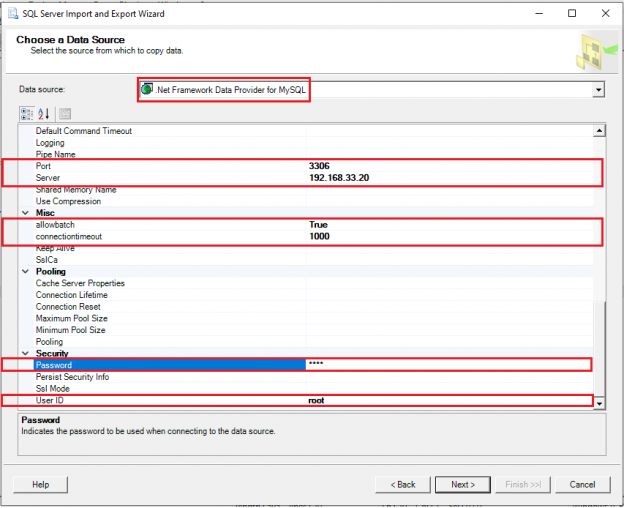
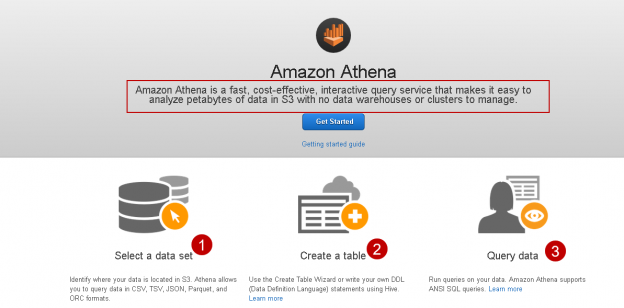
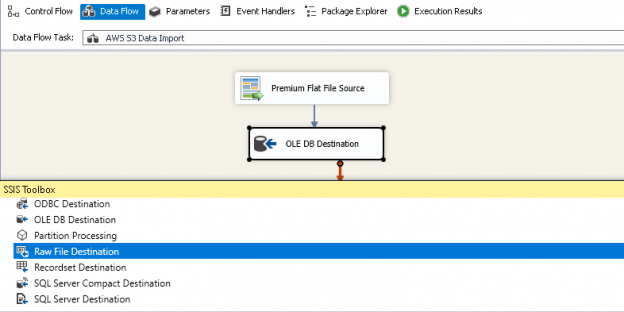
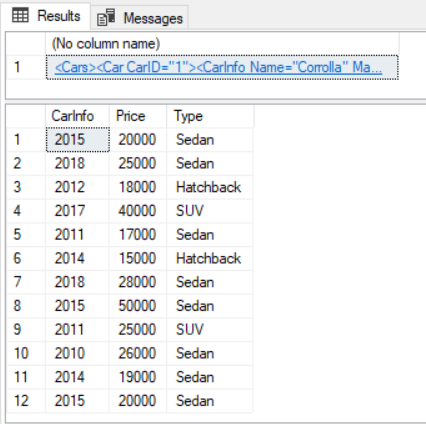
In previous articles, we saw how to connect with ODBC to SQL Server using the ODBC Data Source Administrator in Windows. This time, we will connect to Azure and export the data from one table in Azure to SQL Server on-premises using SSIS.
Read more »