As tracking behavioral data becomes increasingly popular, firms may overlook areas where they can collect the same information while data masking details that can be used in a compromise. Behavioral data collection can be extremely dangerous as it allows attackers a wide range of attacks, from spoofing targets to automating custom attacks on targets. Since behavior can reveal key details about us, this information may be as costly as private identifiable information. When tracking behavioral data, we want to weigh risks, and, in some cases, we can accomplish the same result without specific details. In other cases, we may want to mask specific behavioral information on reports that are generated, even if we retain the specific time. We’ll look at a method where we can accomplish either – updating data to remove time or data masking specific time while returning the information we want.
Read more »Timothy Smith

Tim manages hundreds of SQL Server and MongoDB instances, and focuses primarily on designing the appropriate architecture for the business model.
He has spent a decade working in FinTech, along with a few years in BioTech and Energy Tech.He hosts the West Texas SQL Server Users' Group, as well as teaches courses and writes articles on SQL Server, ETL, and PowerShell.
In his free time, he is a contributor to the decentralized financial industry.
View all posts by Timothy Smith
He has spent a decade working in FinTech, along with a few years in BioTech and Energy Tech.He hosts the West Texas SQL Server Users' Group, as well as teaches courses and writes articles on SQL Server, ETL, and PowerShell.
In his free time, he is a contributor to the decentralized financial industry.
View all posts by Timothy Smith
Latest posts by Timothy Smith (see all)
- Data Masking or Altering Behavioral Information - June 26, 2020
- Security Testing with extreme data volume ranges - June 19, 2020
- SQL Server performance tuning – RESOURCE_SEMAPHORE waits - June 16, 2020

Security Testing with extreme data volume ranges
June 19, 2020When we develop security testing within inconsistent data volume situations, we should consider our use of anti-malware applications that use behavioral analysis. Many of these applications are designed to catch and flag unusual behavior. This may help prevent attacks, but it may also cause ETL flows to be disrupted, potentially disrupting our customers or clients. While we may have a consistent flow of data throughout a time period – allowing for a normal window of behavior to occur – we may also have an inconsistent data schedule or inconsistent amount of data that cause these applications to flag files, directories, or the process itself.
Read more »
SQL Server performance tuning – RESOURCE_SEMAPHORE waits
June 16, 2020When dealing with SQL Server performance tuning waits, we may see RESOURCE_SEMAPHORE waits along with other related monitoring that indicates memory as a possible pain point for our server (such as the below image that shows memory being one of the top waits overall).
Read more »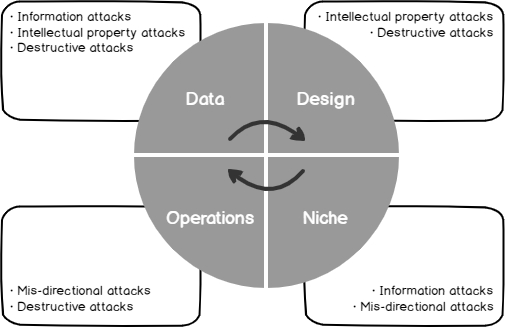
Security Testing Around Our Business Model and Risks
June 9, 2020When we create an environment and consider our security testing from development to production and how changes are deployed throughout each environment, we want to consider what we’re protecting and how much resources we’ll devote to this protection. Every company has limited resources, so protecting against all possible threats will not be something we can achieve.
Read more »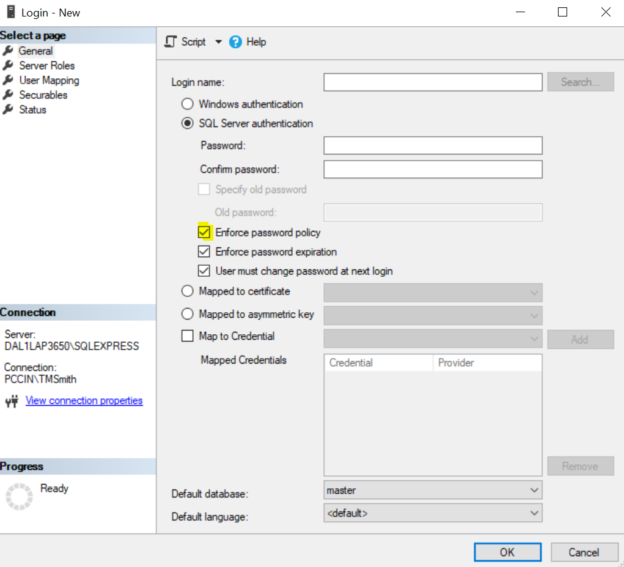
Security Testing SQL Logins with the PWDCOMPARE function
June 3, 2020In this article, we’ll look at using the built-in PWDCOMPARE function in SQL Server for security testing passwords. While this tool may seem like it exposes a weakness in Microsoft SQL Server because we can test for passwords, it should be of note that an attacker could do the same attack by attempting to login to our database server assuming the attacker was able to access a connection to it. Therefore, this function does not increase the risk of an attack on SQL Server but does help us identify possible weaknesses in our environment so that we can quickly mitigate these risks. In addition, we’ll also combine this with other related tools in SQL Server to help us with logins.
Read more »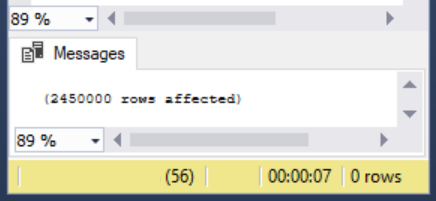
Lock Configurations with SQL Bulk Insert
May 11, 2020One challenge we may face when using SQL bulk insert is whether we want to allow access during the operation or prevent access and how we coordinate this with possible following transactions. We’ll look at working with a few configurations of this tool and how we may apply them in OLAP, OLPT, and mixed environments where we may want to use the tool’s flexibility for our data import needs.
Read more »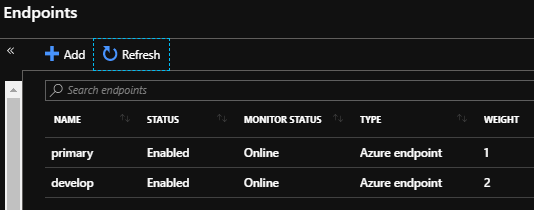
Situations When We May Want Higher Azure Costs
June 17, 2019We’ve looked at methods to reduce costs within Azure. We may experience situations where a slight increase in Azure costs will benefit us to help protect our resources and customers when it involves security or other critical updates. When we consider these situations, we must keep up-to-date with the latest patches, updates to development libraries, as well as the possible effects of these updates to our existing code. Likewise, related to resource usage, a resource may be unused or seldom used by a percent of our customers that we keep when we’re ready to switch all our customers while we make the appropriate upgrades to our resources to help with costs. We’ll look at some techniques that we can use to manage the challenge of critical updates while also keeping costs down, or putting costs into a context about what may be more expensive.
Read more »
Finding Unused Resources Impacting Azure Costs
June 10, 2019To reduce Azure costs on unused and unnecessary resources, we should design with prevention in mind – considering whether we want to commit to reserved use or test with a pay-as-we-go model. We may experience situations where we already have many resources, but are unsure of their use – are these consistently used, sometimes used, never used? Before we can answer whether an unused resource (or what appears to be an unused resource) is unnecessary, we have to determine whether it’s used. In this tip, we’ll look at this challenge.
Read more »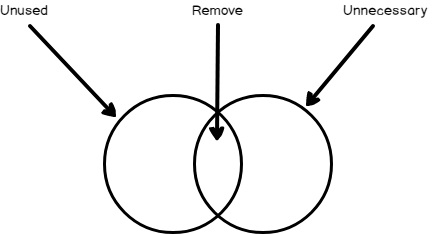
Handling Unused and Unnecessary Resources Impacting Azure Costs
June 5, 2019Two of the more challenging causes of an increase in Azure costs are unused and unnecessary resources. Unused and unnecessary resources may not always be the same, even though they can overlap. If we know the difference between these resource categories or when these resources categories overlap then we will see improvements in preventing these from adding to our costs. In addition, when we think about unused resources, we should consider options that we have with Azure to optimize for these, as an unused resource may still be necessary sometimes. In this tip, we’ll look at these topics to assist us with reducing our Azure use.
Read more »
Tracking Azure Costs with Cost Management
June 3, 2019The Azure Portal offers the free tool Cost Management that we can use for managing Azure costs. As we’ll see, we can use this tool to organize how we manage our spending along with setting limits for thresholds to alert the appropriate members. While this tool can be useful for our organization, it has the potential to cause noise or disruptions, so we still want to review how we use it within our organization for managing the spending of our teams.
Read more »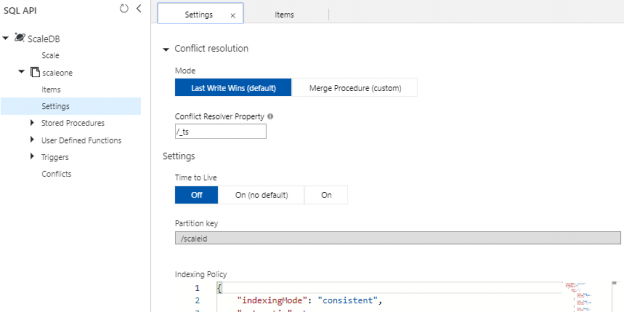
Creating Containers with PowerShell For Azure Cosmos DB
May 30, 2019In many situations, we will develop, test or prove new concepts by horizontally scaling new SQL API containers in Azure Cosmos DB over possibly using existing containers. As we’ve seen in previous tips, we can create and remove Cosmos database accounts and databases by using the Azure Portal or PowerShell’s Az module along with making some updates to the configuration, such as the RUs for performance reasons. Similarly, we can create and remove a container through the Azure Portal along with creating and removing the container with PowerShell’s Az module.
Read more »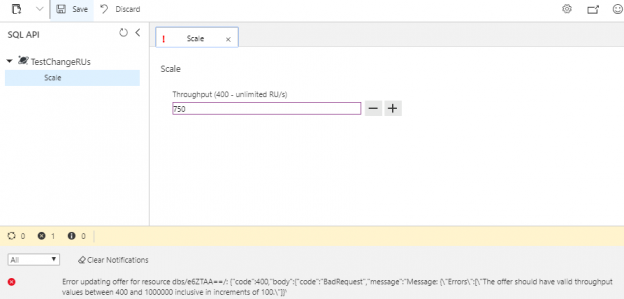
Increasing or Decreasing Scale for Azure Cosmos DB
May 28, 2019Now that we can create and remove an Azure Cosmos DB and databases that we can use for automation purposes, along with obtaining some information about these accounts, we’ll look at making some changes to these accounts for contexts related to performance. It’s possible that our unit and security testing or development with proof-of-concepts may face performance problems where we need to upgrade the settings of our database account. In this tip, we’ll be working with the SQL API database layer in a Cosmos database account by building on our get, create and remove automation to update its performance.
Read more »
Creating and Removing Databases with PowerShell In Azure Cosmos DB
May 27, 2019Our testing or development may call for dynamic creation on the database level for Azure Cosmos DB rather than the account level. As we’ve seen with dynamically working with a Cosmos database account using PowerShell, we can create, remove, and obtain properties of the account. Identically, we can do this on the database level as well and we may use this in testing if we need the same Cosmos database account for other testing purposes. Development situations may also involve use cases where we want to test a concept and dynamically create a database within our Cosmos database account. In this tip, we’ll look at working with our Azure Cosmos database account on the database object level where we do nothing to manipulate the account itself, only add databases to the account once it’s been setup.
Read more »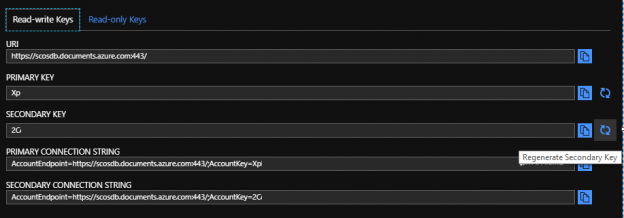
Getting and Updating Connection Information for Azure Cosmos DB
May 24, 2019After we set up our Azure Cosmos DB, we may want to get, add to, or update existing properties. We may use some of the get functionality that PowerShell provides to dynamically save values to encrypted configuration files or tables that we use for application purposes and this functionality could be added to the creation of the Cosmos database account, or a separate step in addition to the creation. In secure contexts, this ensures security without the properties after passing through human eyes since they are saved directly to an encrypted location. In the same manner, we may want to regenerate the keys for the account and save the connection strings with the new keys.
Read more »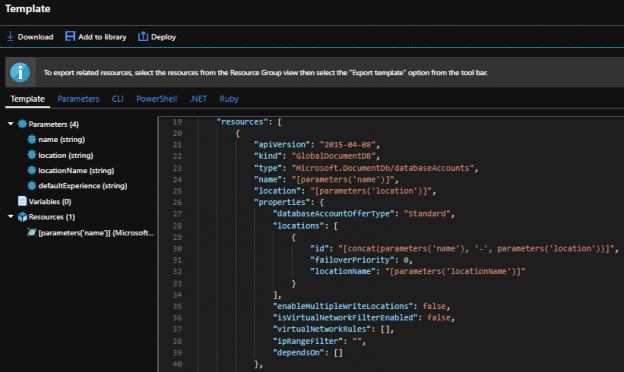
Creating and Removing Azure Cosmos DBs with PowerShell
May 21, 2019When managing Azure Cosmos DB, we can use the Azure portal and create resources through the interface or use the command line in the portal and create resources. PowerShell also supports some functionality for creating and managing these resources, which can help development teams automate the creation of these databases for quick creations, unit and security tests, removals if the resources aren’t required following the tests. We can also use these scripts for creating templates that we may use in multi-scaling creations (like databases in a group designed for horizontal scale). Generally, in one-off situations, the Azure Portal will suffice for deployments if there is a cost to develop automation that is not required. In this tip, we’ll look at the process of creating a blank and removing the same Azure Cosmos DB.
Read more »
Extract Azure Costs Using PowerShell
May 20, 2019With strong organization and design for our development teams, cloud infrastructure and security considerations, we’ll now extract Azure cost information that we can share with our organization. In addition, we will see that we can retain this information if needed to track growth (or reduction) in costs. This step is important as it will allow our teams to have an insight into their development and it will also be another audit we can use on the security side to catch unusual growth (or significant reductions) in resource costs that may be the result of an attacker. Our ultimate goal with tracking these costs and sharing them with teams is to improve our development and possibly re-organize it as needed, giving us the ability to further reduce our spending.
Read more »
User Security and Risks to Azure Costs
May 16, 2019We’ve looked at both the organization and development side of managing Azure costs. One risk we have is attackers who compromise an account and mis-scale resources (such as scaling up), driving up our costs. Another scenario is attackers scaling resources too low that affects client’s ability to do their work (performance problems) – a separate risk that may result in lower costs on the cloud side, but higher costs against our reputation. A third risk is reconnaissance of our Azure use: this allows the attackers to get information about our design and later make a wide range of attacks that will appear as normal to us – in this case, Azure costs may be only one of the impacts with other impacts being as severe.
Read more »
Controlling Azure Costs Using Scaling and Tags
May 13, 2019Depending on our design and security, we can create functions or use built-in tools to control our Azure costs. In some contexts, we may look at the overall cost of what tools we’re using, which the Azure portal conveniently shows. Applying what we’ve looked at on the organization and development level, we can organize resources on their design (or ad hoc, as we’ll see) along with creating scripts that control our scale for situations where we may want higher or lower scale. We’ll look at both of these scenarios and how they can help us in both organization and development contexts.
Read more »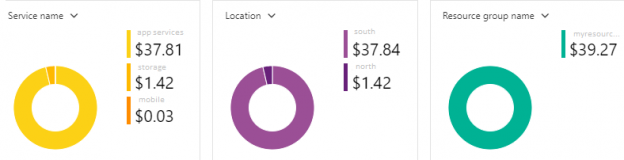
Azure Costs Tracking with Security and Design Considerations
April 30, 2019Azure costs can quickly mount, without careful supervision and management. This article will detail cost mitigation strategies using security and design
Read more »
Securely Working with Invoke-SqlCmd
March 26, 2019We have a convenient tool for working with PowerShell and SQL Server when using Invoke-SqlCmd. As we saw when running statements, we can run DDL and DML changes with the command without writing our own custom scripts. This carries advantages when we need to quickly develop with PowerShell, but it can come with drawbacks on security if we’re not careful how we use this function. We’ll look at security when using this function by starting with a few examples of what we can do when we have unlimited access along with how we can design to limit our environment to be strict with our use of this tool.
Read more »
Working with PowerShell’s Invoke-SqlCmd
March 18, 2019PowerShell features many one-line commands for working with SQL Server, one of which is Invoke-SqlCmd. This tool can be useful in many development contexts where we need to quickly execute scripts or test code and it helps to know some of the parameters we’ll often use. In addition, because we may want a custom script using some of the underlying .NET objects, we’ll look at an alternative where we will be able to create a custom PowerShell script that connects to SQL Server in order to run commands. The latter can be useful because one-line scripts have a tendency to change in future versions of PowerShell and working with the library directly can sometimes avoid this challenge.
Read more »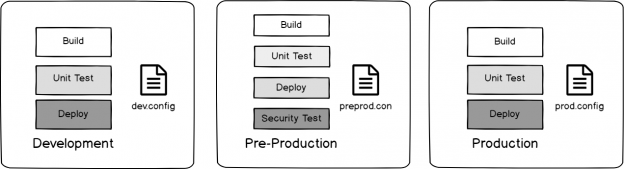
DevSecOps: Security Testing Around Builds and Shared Information
March 11, 2019One big component of DevSecOps surrounding security testing involves how we build and deploy with shared information access of details that may be valuable to an attacker. In order to understand these risks, we must think like attacker who wants to compromise an environment that is focusing on quickly writing code, building the code, testing it, and deploying it across multiple environments. An attacker’s ultimate target will be the highest environment – often a production environment, but some attackers may target lower environments because they may be able to inject code that is deployed to production. In addition, an attacker may only be trying to learn about how an environment is laid out to attack in other ways, such as using social engineering with key information.
Read more »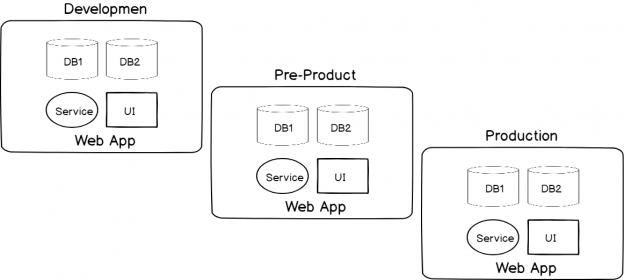
DevSecOps: Developing with Automated Security Testing
March 6, 2019A key component of DevSecOps and identical to running unit tests to validate code after a build, running automated security testing after an application has been deployed (such as automated penetration tests) can provide us with a tool that identifies security risks. As we’ve seen recently, there’s been a growth of many companies experiencing information being compromised and with the development culture of “move fast and break things”, I expect this trend of successful attacks will continue. Before we look at our options for automating this testing, we want to be aware of its limits, evaluate the requirements, and consider common designs that are useful.
Read more »
Getting Started with Subdocuments in Azure Cosmos DB
February 22, 2019As we’ve worked with Azure Cosmos DB, we’ve seen that we can store data within fields and the fields of each document don’t always have to match – though we still want some organization for querying. The fields and values storage becomes useful when working with object-oriented languages as these fields can be keys that we use with values that we extract as properties. For an example, the below PowerShell line creates a JSON document in an object and we can see that we can extract the values of these keys in the JSON object.
Read more »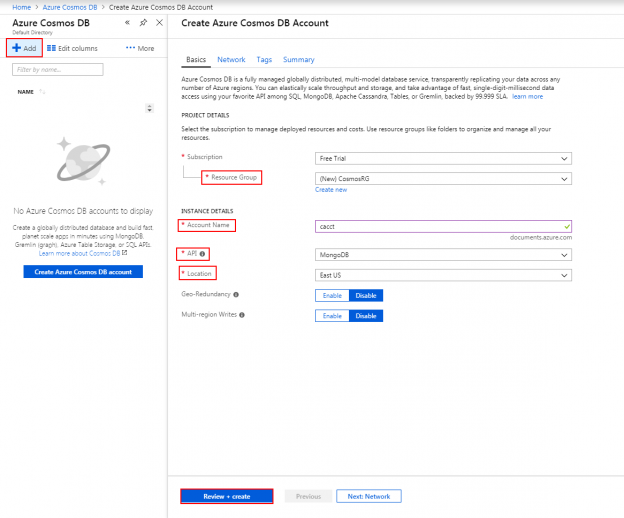
Applying Field Operators and Objects in Azure Cosmos DB
February 15, 2019Since we will sometimes require removing documents in Azure Cosmos DB, we’ll want to be able to specify the documents for removal. In some cases, this will be as simple as specifying a field for removal, such as removing one type of workout in our temporary database we’ve created. In other delete situations, we’ll want to remove if the value of the field isn’t what we expect – such as greater than what we want. This applies to updates as well – we may want to drill into a specific value range for an update. In this tip, we’ll look at using operators with strings, numeric types and dates.
Read more »