In this article, we are going to make a SQL practice exercise that will help to prepare for the final round of technical interviews of the SQL jobs.
Read more »
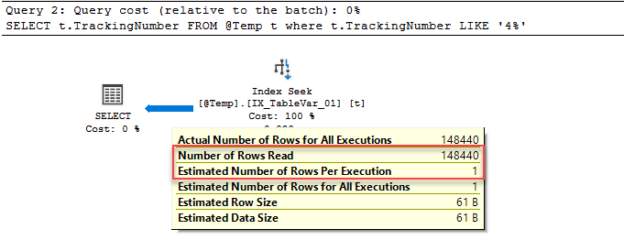
In this article, we are going to make a SQL practice exercise that will help to prepare for the final round of technical interviews of the SQL jobs.
Read more »
In this article, we are going to learn some best practices that help to write more efficient SQL queries.
Queries are used to communicate with the databases and perform the database operations. Such as, we use the queries to update data on a database or retrieve data from the database. Because of these functions of queries, they are used extensively by people who also interact with databases. In addition to performing accurate database operations, a query also needs to be performance, fast and readable. At least knowing some practices when we write a query will help fulfill these criteria and improve the writing of more efficient queries.
Read more »
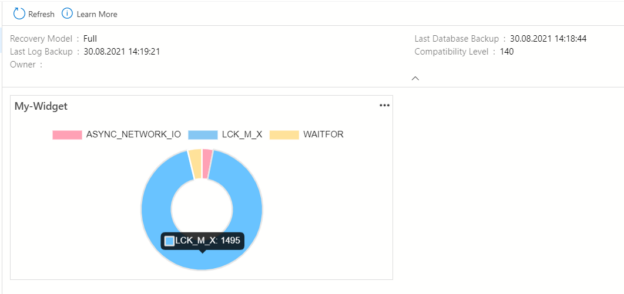
In this article, we will learn how to build a customized widget in Azure Data Studio that helps to monitor the performance metrics.
Read more »
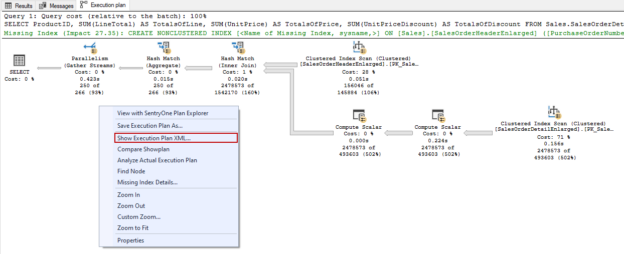
In this article, we will learn various methods of how to get an SQL execution plan of a query.
Read more »
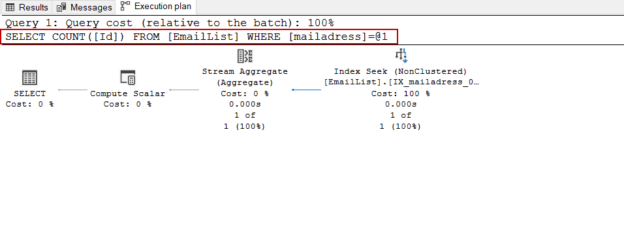
The purpose of this article is to provide insights into how parameter sniffing occurs for an ad-hoc query and how it affects their performance.
Read more »
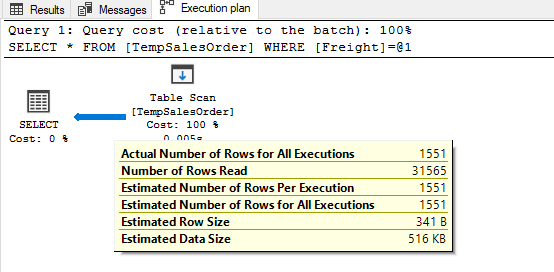
In this article, we will explore some internal working principles of SQL Server statistics.
Read more »
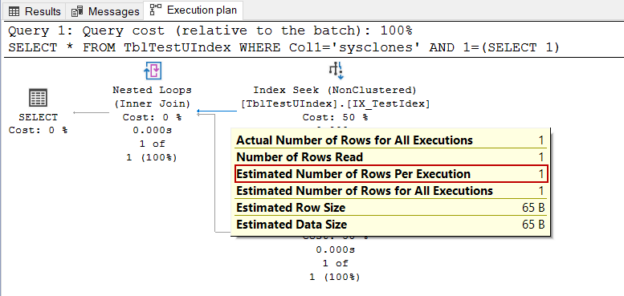
The goal of this article is to throw light on the less-known points about SQL Server statistics.
Read more »
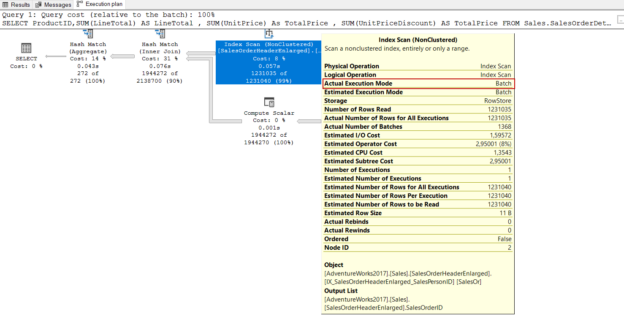
In this article, we will explore Microsoft SQL Server trace flags with all aspects, and we will learn also how to use them.
Read more »
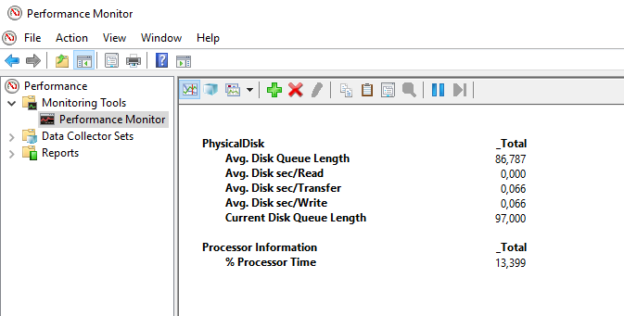
This article gives fundamental insights into which 5 reasons can cause to drop off the query performances in SQL Server.
Read more »
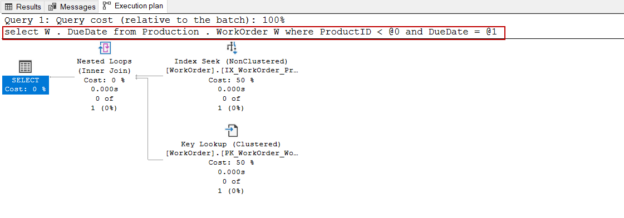
The goal of this article is to give details about the database query parameterization feature and explain its effects on query performance.
Read more »
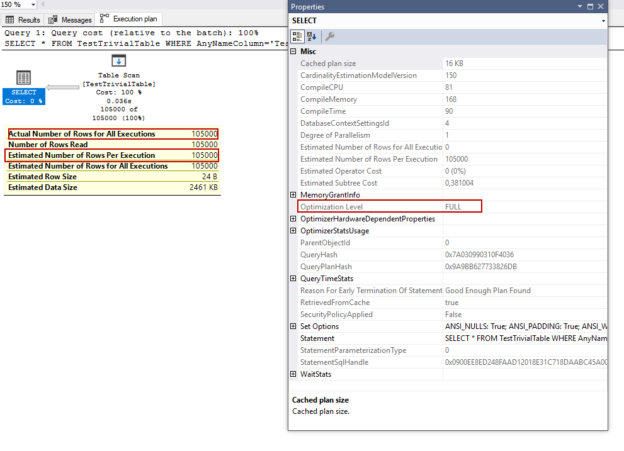
In this article, we will go through the details of the trivial execution plans and we will also tackle some examples about the trivial plans to explore effects on query performance.
Read more »
In this article, we will explore the details of what happens behind the scenes when a SQL delete statement is executed.
Read more »
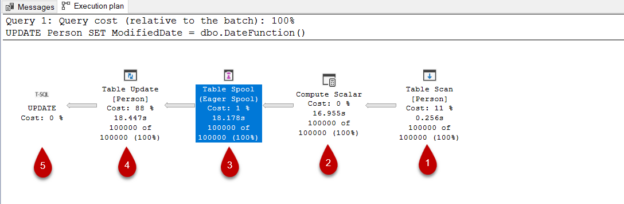
The SQL update statement is used to modify an existing record or records in a table and it is commonly widely used in databases applications. In this article, we will examine the update statement in terms of the performance perspective.
Read more »
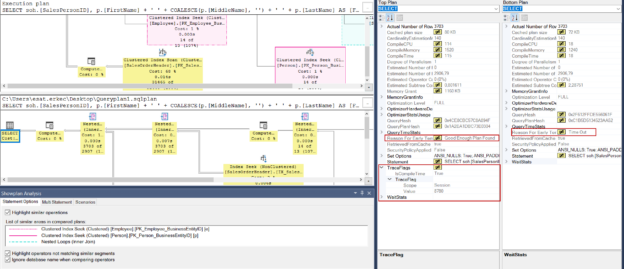
In this article, we will learn some query hints and trace flags that impact the query performance and also influence the SQL Server query optimizer’s default execution plan generation algorithm.
Read more »
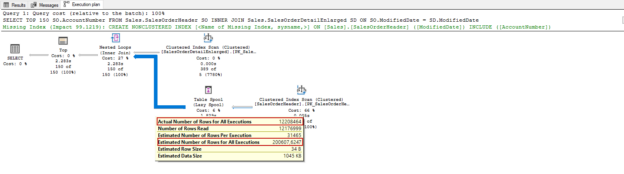
In this article, we will discuss the performance details of the SQL TOP statement, and we will also work on a performance case study.
Read more »
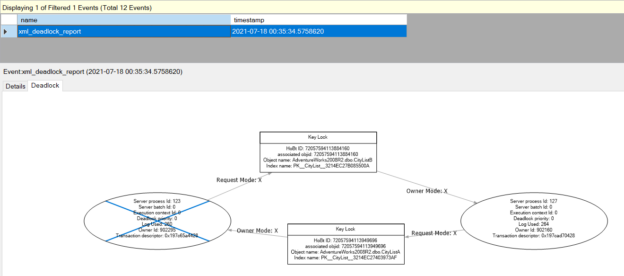
In this article, we will explore how we can use SQL Server extended events to monitor query performance in SQL Server.
Read more »
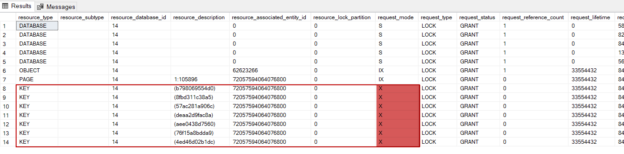
In this article, we will learn how to monitor SQL Server blocking issues with different methods.
Read more »
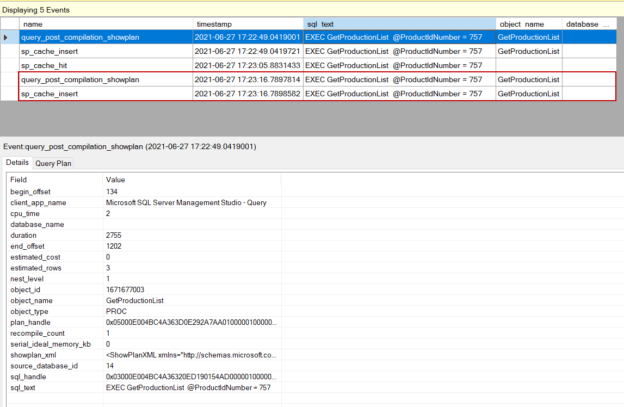
This article intends to give comprehensive details on how we can use the recompilation options of SQL Server stored procedures and how they behave when we use these recompilation options.
Read more »
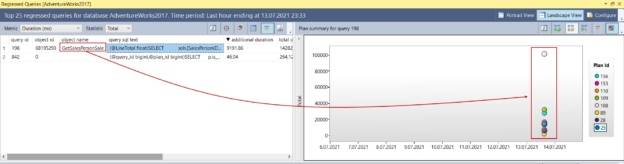
In this article, we will explore in detail the factors that cause SQL Server stored procedures to be recompiled.
Read more »
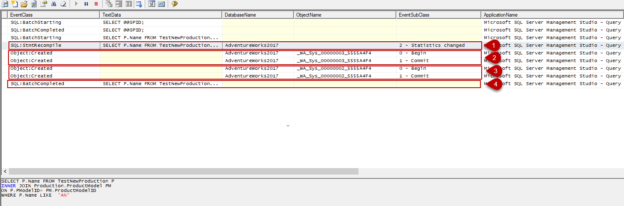
This article will mention in which conditions the query optimizer decides to recompile to queries and how it affects the SQL query performance.
Read more »
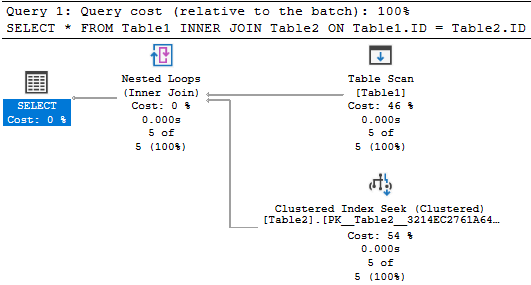
There are three types of physical join operators in SQL Server, namely Nested Loops Join, Hash Match Join, and Merge Join. In this article, we will be discussing how these physical join operators are working and what are the best practices for these different joins.
Read more »
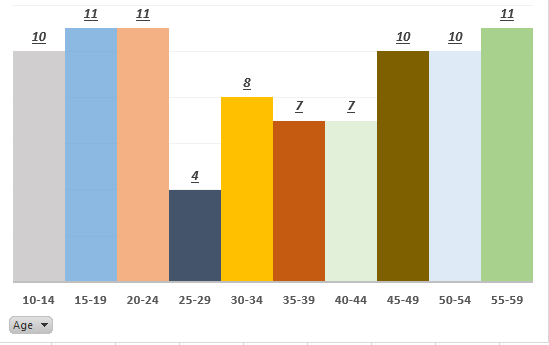
In this article, we will take a glance at the fundamentals of SQL Server statistics and discover their interaction with the query processing steps with simple examples.
Read more »
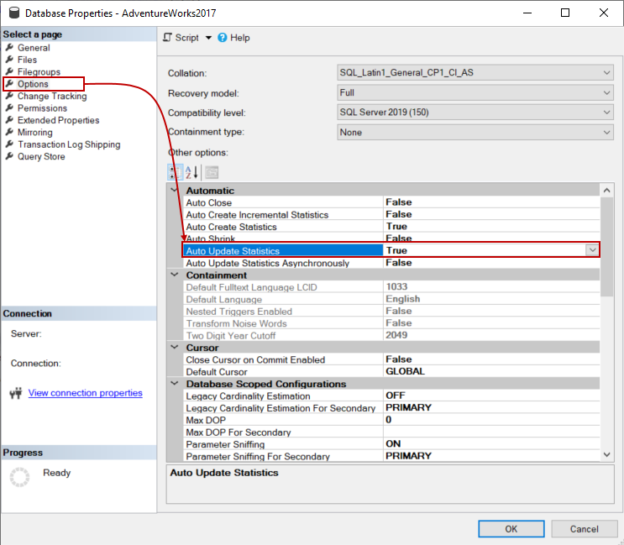
In this article, we will go through some details about SQL Server statistics.
Read more »
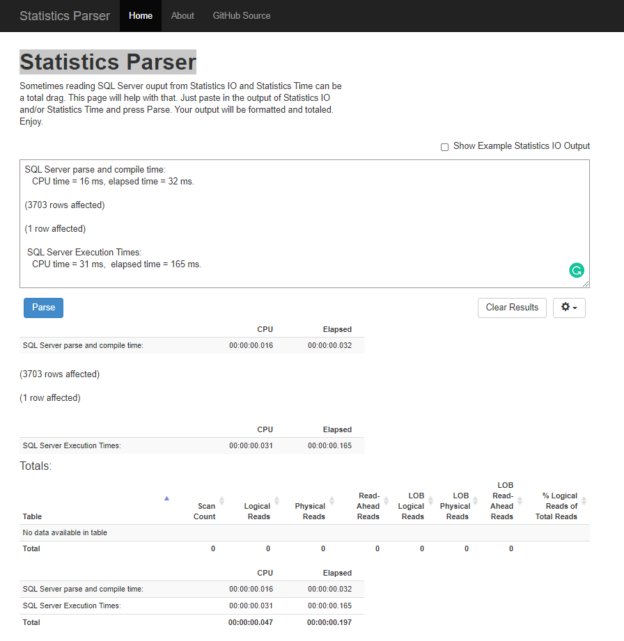
With the help of the SET STATISTICS TIME ON statement, we can easily report the execution time statistics of a query. In this article, we will learn how to report the query execution time statistics through this statement.
Read more »
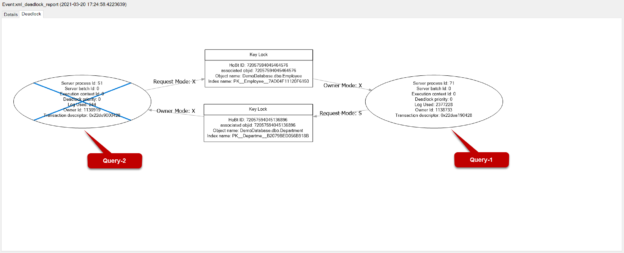
In this article, we will try to find out the answer to the question of “Does a foreign key lead to a deadlock?”
Read more »© Quest Software Inc. ALL RIGHTS RESERVED. | GDPR | Terms of Use | Privacy