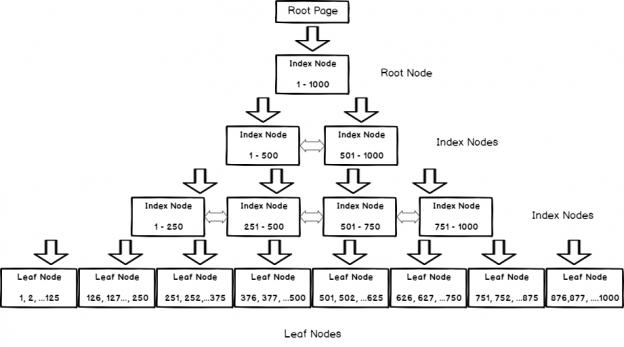
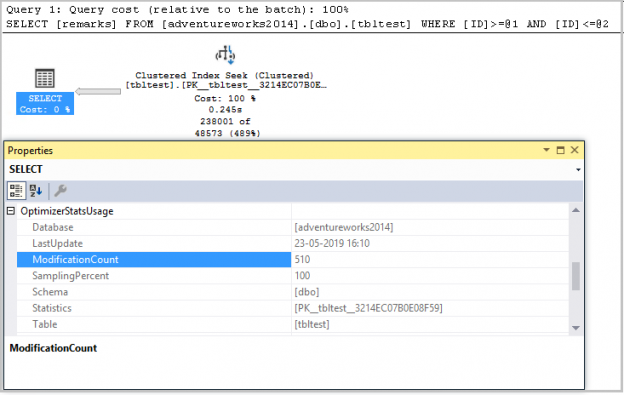
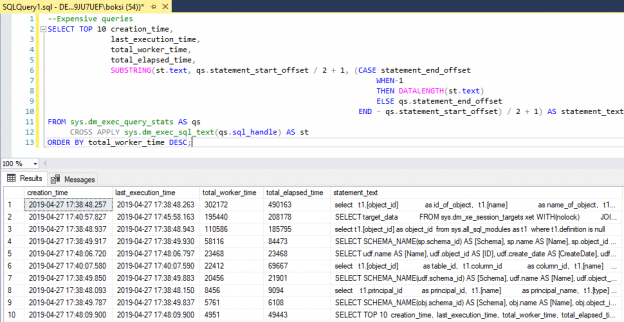
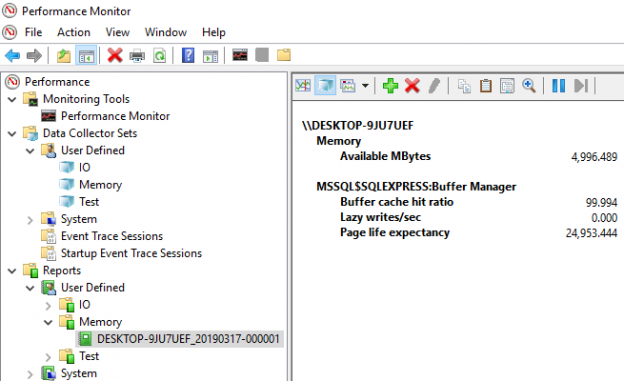
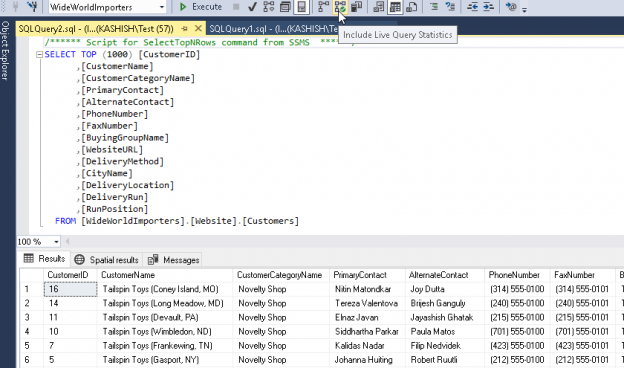
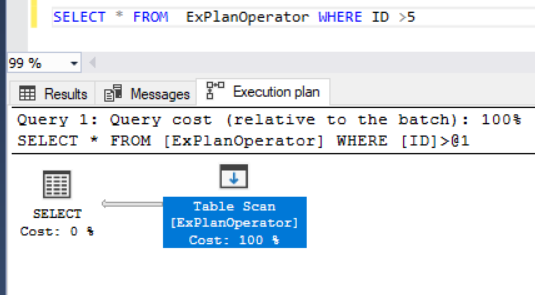
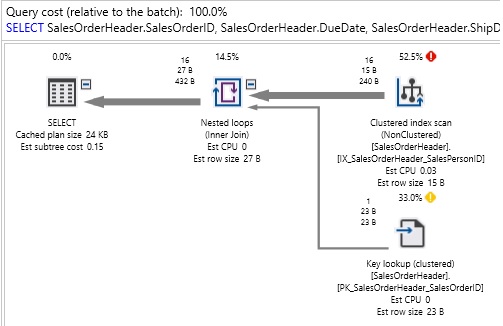
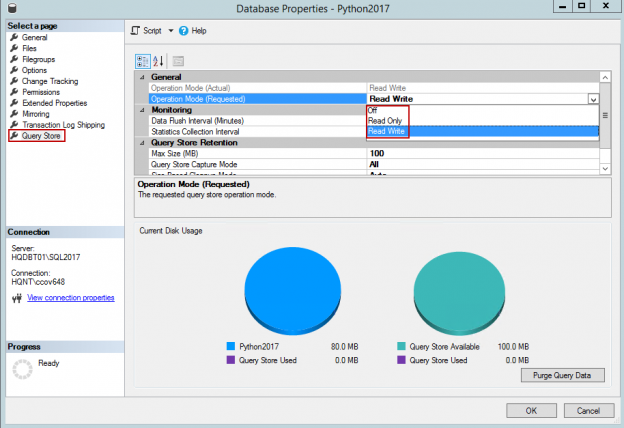
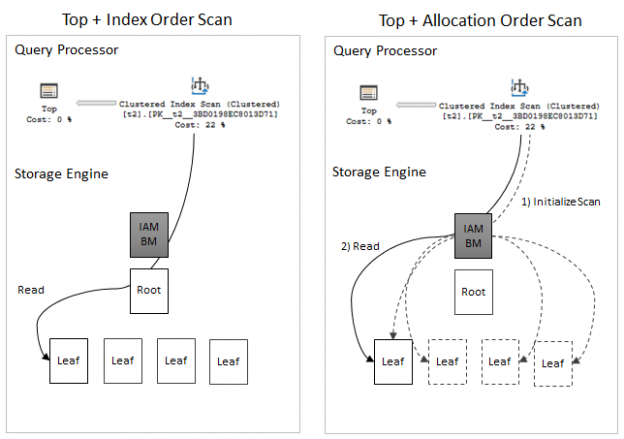
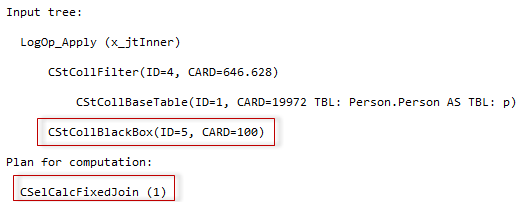
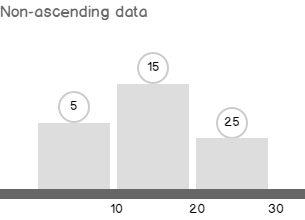
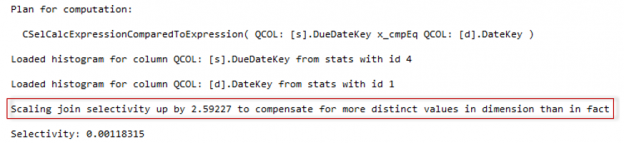
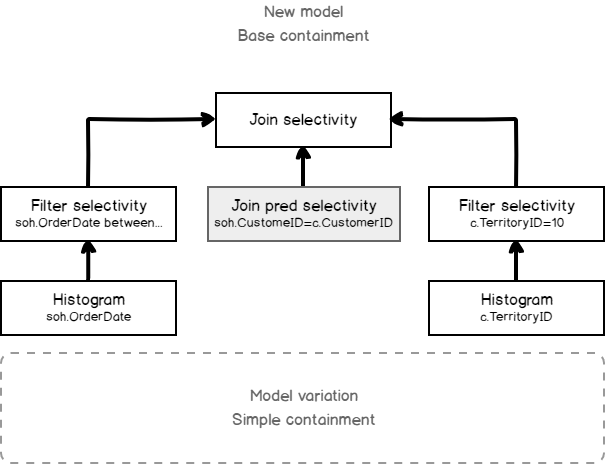
In this blog post, we are going to view some interesting model variation, that I’ve found while exploring the new CE.
A model variation is a new concept in the cardinality estimation framework 2014, that allows easily turn on and off some model assumptions and cardinality estimation algorithms. Model variations are based on a mechanism of pluggable heuristics and may be used in special cases. I think they are left for Microsoft support to be able to address some client’s CE issues pointwise.
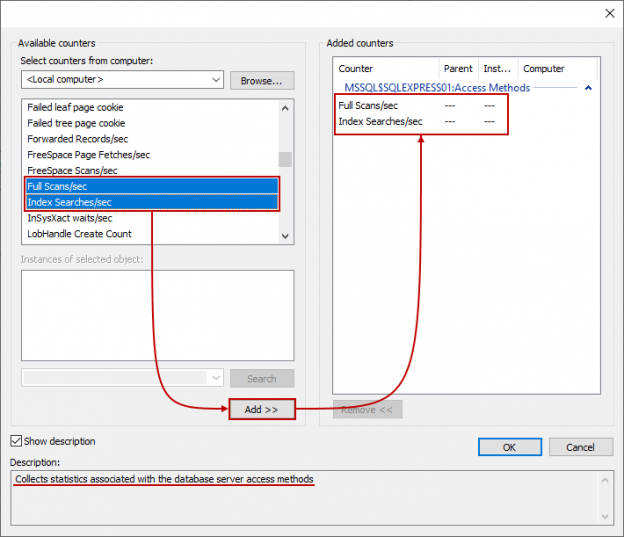
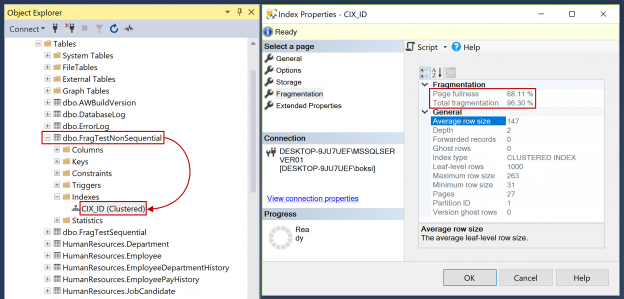
Today we are going to view some interesting model variation, that creates filtered statistics on-the-fly. I should give a disclaimer here.
Read more »