
In this blog post, we are going to talk about another cardinality estimation model enhancement in SQL Server 2014 – Overpopulated Primary Key (OPK).
Consider a fact table that contains information about some sales, for example, and a date dimension table. Usually, a fact table contains the data about the current year and past years, but a dimension table usually contains the data for the next few years also.
If we are joining two tables fact and dimension and filtering on dimension table we usually demand the rows that do exist in a fact table, for example, we ask for the last month sales, but not for the next year sales. We also remember that a filter influences a join estimation, the join column statistics information should be modified according to the filter selectivity and cardinality. I don’t know the precise formula that is used for that in SQL Server, however, the algorithm is called Selection Without Replacement and is taken from the probability theory (the exact method doing maths in SQL Server is sqllang!CCardUtilSQL12::ProbSampleWithoutReplacement). You may read some details about the similar algorithm in Oracle further in useful links.
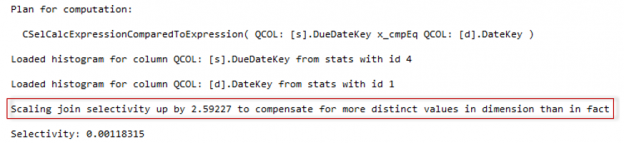
What is important for that post, that the number of distinct values in the join columns is used to calculate the join selectivity after filtering by another column. As we said before, a dimension table usually contains more distinct values than a fact table, because it is filled with the data for the next few years also, but we usually select only the relevant data, that is present in a fact table, i.e. those overpopulated distinct values should be somehow compensated and not concerned when we estimating the join over filtered dimension. That is what Overpopulated Primary Key model assumption about.
Let’s see this in action. We will use AdventureWorksDW2012 database and issue two identical queries, the first one – uses the new CE framework (I also add TF 2363, to view some diagnostic output), the second query uses the old framework (because we run it with TF 9481 – that forces the old CE behavior).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
alter database AdventureWorksDW2012 set compatibility_level = 120; go set statistics xml on select sum(s.SalesAmount) from dbo.FactInternetSales s join dbo.DimDate d on d.DateKey = s.DueDateKey where d.CalendarYear = 2008 option(querytraceon 3604, querytraceon 2363) go select sum(s.SalesAmount) from dbo.FactInternetSales s join dbo.DimDate d on d.DateKey = s.DueDateKey where d.CalendarYear = 2008 option(querytraceon 9481) set statistics xml off go |
The actual number of rows for both of the queries equals 34 229, let’s look at the estimates.
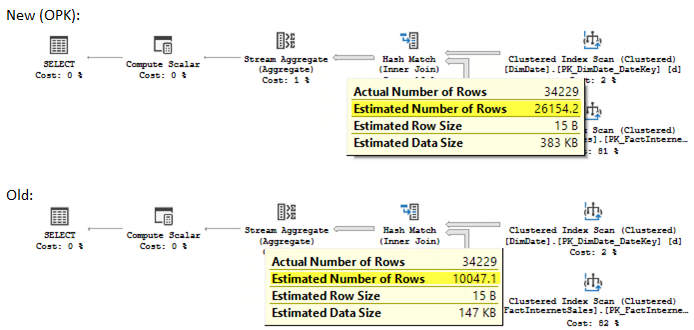
The estimation with the new CE framework is much closer to the reality (26 154 new vs. 10 047 old vs. 34 229 actual). This is because the join selectivity was scaled to compensate the key overpopulation. If you look at the diagnostic output, you’ll see the message that tells you, that this action was taken.
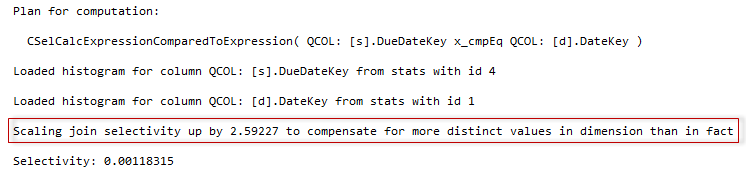
The Model Variation
As you may suppose in this case the model variation would be not to use the OPK assumption and do not adjust the selectivity. To do it, you should run the query with TF 9482.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
set statistics xml on --New - OPK disabled select sum(s.SalesAmount) from dbo.FactInternetSales s join dbo.DimDate d on d.DateKey = s.DueDateKey where d.CalendarYear = 2008 option(querytraceon 9482) go -- Old select sum(s.SalesAmount) from dbo.FactInternetSales s join dbo.DimDate d on d.DateKey = s.DueDateKey where d.CalendarYear = 2008 option(querytraceon 9481) set statistics xml off go |
If we now examine the estimates we will see that they are very close, you also won’t see the “Scaling join selectivity…” output in the diagnostic console messages.
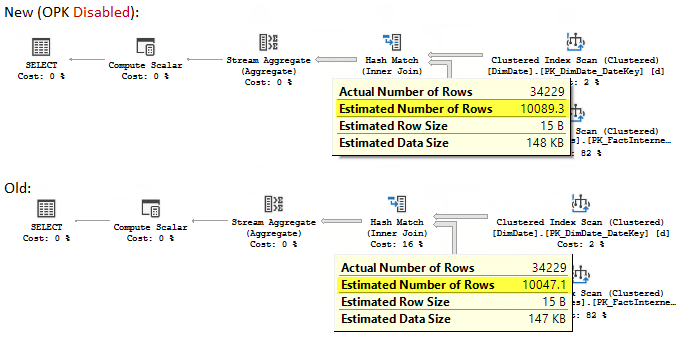
Again, I should warn everybody. This is undocumented and should not be used in production.
The final thing to mention, that there is nothing special about a fact and a dimension table for the OPK to be used. The decision to adjust the selectivity is made based on the difference between the distinct value counts. That means that you may observe this behavior, not only in DW databases, but in OLTP also, depending on your data distribution.
That’s all for this post. Next, we will talk about one of my favorite and really helpful changes in the new CE – the Ascending Key situation.
Table of contents
References
- Optimizing Your Query Plans with the SQL Server 2014 Cardinality Estimator
- Testing cardinality estimation models in SQL server
- Cost Based Oracle: Fundamentals Chapter 10: Join Cardinality

Currently he works as a database developer lead, responsible for the development of production databases in a media research company. He is also an occasional speaker at various community events and tech conferences. His favorite topic to present is about the Query Processor and anything related to it. Dmitry is a Microsoft MVP for Data Platform since 2014.
View all posts by Dmitry Piliugin
- SQL Server 2017: Adaptive Join Internals - April 30, 2018
- SQL Server 2017: How to Get a Parallel Plan - April 28, 2018
- SQL Server 2017: Statistics to Compile a Query Plan - April 28, 2018