
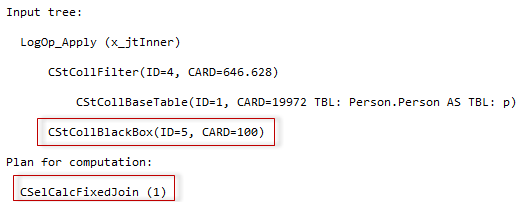
This is a note about multi-statement table valued functions (MTVF) and how their cardinality is estimated in the new CE framework.
In the old CE framework the MTVF had fixed estimate of one row, in the new one the estimate is still fixed, however, now it is 100 rows. That’s the whole story. =)
For the optimizer, the MTVF (as long as the scalar UDF) is a black box, from the estimation perspective. Its often considered that inline-TVF is better, because it’s text is embedded into the query and optimized as a whole. However, I saw the examples where MTVF performed better than inline – it depends, as it used to say. In general and most of the cases inline functions are really a better choice.
If you turn on the diagnostic output TF 2363 you will see that the optimizer uses the term “black-box” literally. You may also notice, that a fixed join calculator is used to estimate the join selectivity with the fixed 100 row estimate.
Now let’s move to the short example, this is an artificial example, just to demonstrate the possible positive effect of estimating more than 1 row.
At first, let’s create a Numbers table and a simple MTVF.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
use AdventureWorks2012; go ------------------------------------------------ if object_id ('dbo.mtvfGetNums') is not null drop function dbo.mtvfGetNums; if object_id('dbo.Numbers') is not null drop table dbo.Numbers; create table dbo.Numbers(n int primary key) insert dbo.Numbers(n) select top(1000000) rn = row_number() over(order by (select null)) from sys.columns c1,sys.columns c2,sys.columns c3; go ------------------------------------------------ create function dbo.mtvfGetNums(@max int) returns @res table(id int identity primary key, n int) with schemabinding as begin insert @res(n) select n from dbo.Numbers where n <= @max; return; end; go |
Now, let’s run two identical synthetic queries, to demonstrate the difference (don’t look for the sense in them), the first one uses the old CE, the second one the new CE:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
-- Old set statistics time, xml on declare @a int, @b int, @c int; select @a = p.BusinessEntityID, @b = be.BusinessEntityID, @c = f.n from Person.Person p cross apply dbo.mtvfGetNums((BusinessEntityID+1)%1000) f left join Person.BusinessEntity be on f.id = be.BusinessEntityID where p.BusinessEntityID <= 1000 option(querytraceon 9481) set statistics time, xml off go --New: set statistics time, xml on declare @a int, @b int, @c int; select @a = p.BusinessEntityID, @b = be.BusinessEntityID, @c = f.n from Person.Person p cross apply dbo.mtvfGetNums((BusinessEntityID+1)%1000) f left join Person.BusinessEntity be on f.id = be.BusinessEntityID where p.BusinessEntityID <= 1000 set statistics time, xml off go |
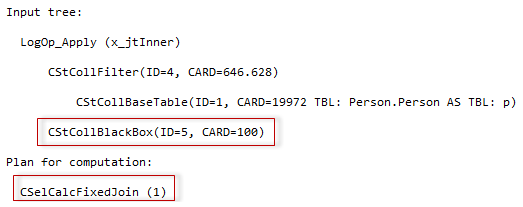
On average the first query runs 50% slower (1950 ms old vs. 1250 ms new). Let’s look at the plans.
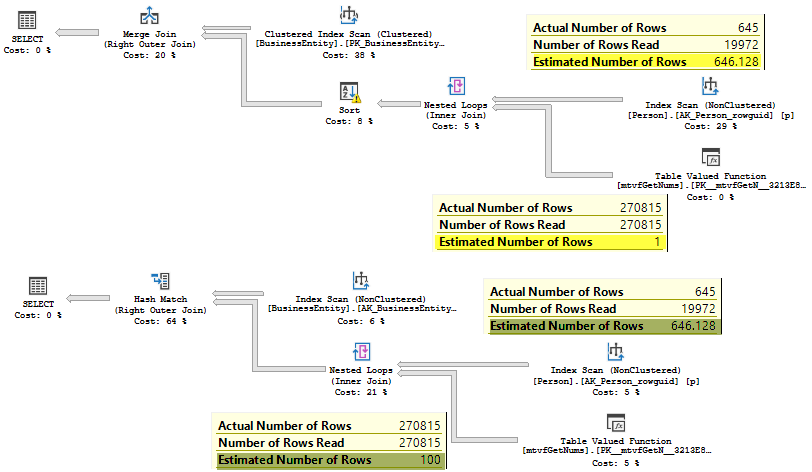
In the first case, the MTVF was estimated as one row, multiplied by the number of executions 646. The actual number of rows is much higher, about 270 000. That lower estimate, lead to selecting a merge join that demands sorted inputs, and so the sort is present. The Sort demands some memory amount, this amount is based on the cardinality also, that was underestimated and so the spill at the level two occurred.
The new CE estimated in a correct way and is closer to the reality of 270 000 rows, however, not very close, but this was enough, to choose another join type and avoid sorting and spilling.
You may invent the opposite situation when 1 row estimate wins, or you may invent the example where there is no difference. That is possible because 100 rows estimate is still a guess and you may vary the data to make the guess closer or farther to the reality.
The Model Variation
You may use the new CE, but turn off this particular estimate of 100 rows for MTVF using the model variation, that can be enabled by TF 9488 (it is checked in the function CCardFrameworkSQL12::CardEstimateTVF internally).
If you run the query:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
set statistics time, xml on declare @a int, @b int, @c int; select @a = p.BusinessEntityID, @b = be.BusinessEntityID, @c = f.n from Person.Person p cross apply dbo.mtvfGetNums((BusinessEntityID+1)%1000) f left join Person.BusinessEntity be on f.id = be.BusinessEntityID where p.BusinessEntityID <= 1000 option(querytraceon 9488) set statistics time, xml off go |
You will see that the estimate now is 1 row per execution:
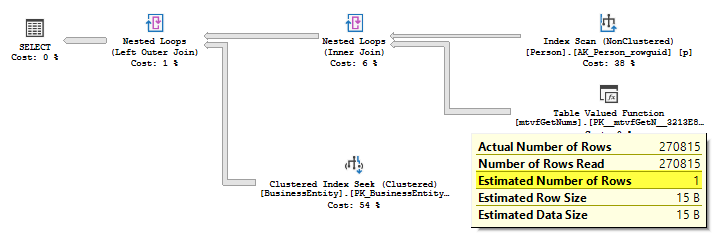
Interesting, that even the MTVF is estimated as in the old CE framework, we have a different plan. That is because the Joins are present in our queries, and the Join estimation was also changed in many ways. However, that is a topic for another blog post.
That’s all for that post, happy estimations! =)
Table of contents
References
- Optimizing Your Query Plans with the SQL Server 2014 Cardinality Estimator
- Query Performance and multi-statement table valued functions
- ALTER DATABASE (Transact-SQL) Compatibility Level

Currently he works as a database developer lead, responsible for the development of production databases in a media research company. He is also an occasional speaker at various community events and tech conferences. His favorite topic to present is about the Query Processor and anything related to it. Dmitry is a Microsoft MVP for Data Platform since 2014.
View all posts by Dmitry Piliugin
- SQL Server 2017: Adaptive Join Internals - April 30, 2018
- SQL Server 2017: How to Get a Parallel Plan - April 28, 2018
- SQL Server 2017: Statistics to Compile a Query Plan - April 28, 2018