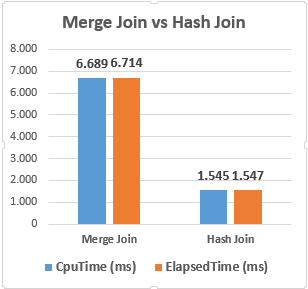
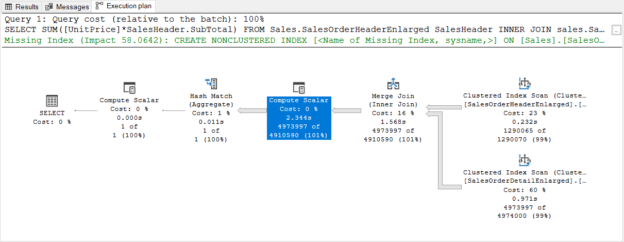
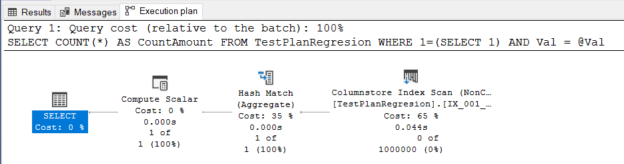
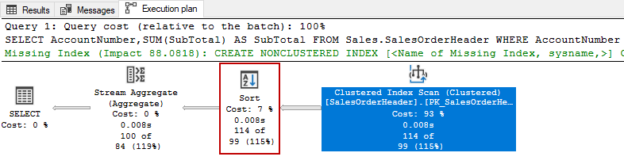
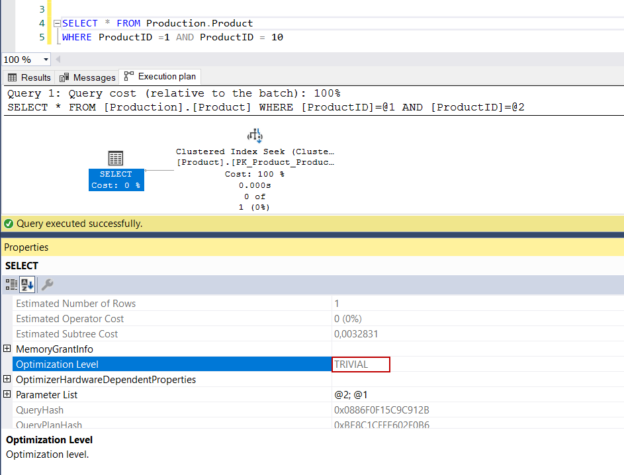
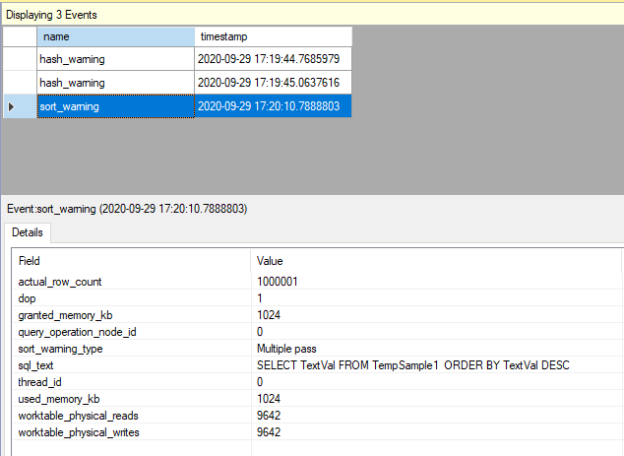
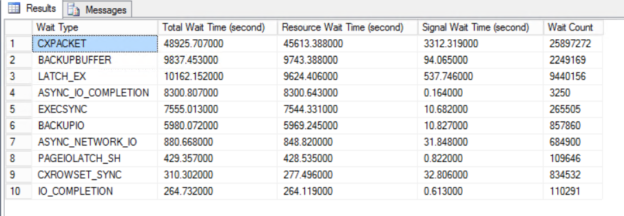
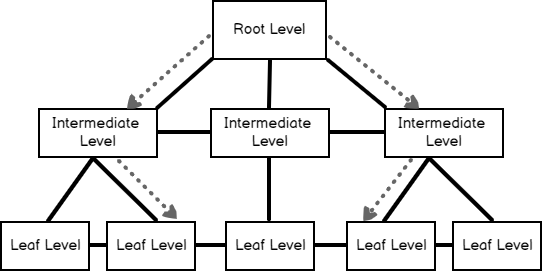
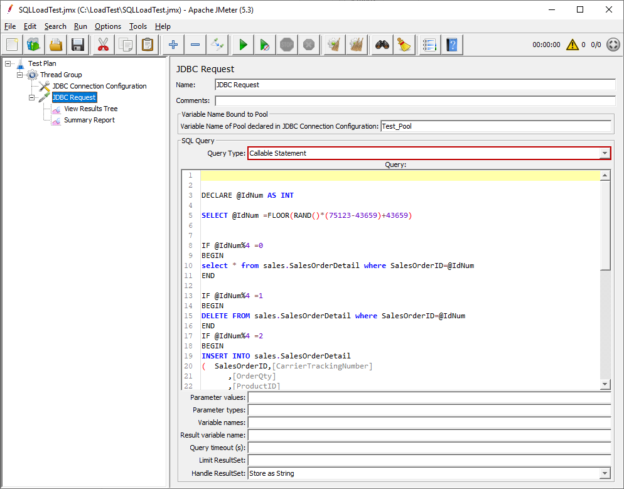
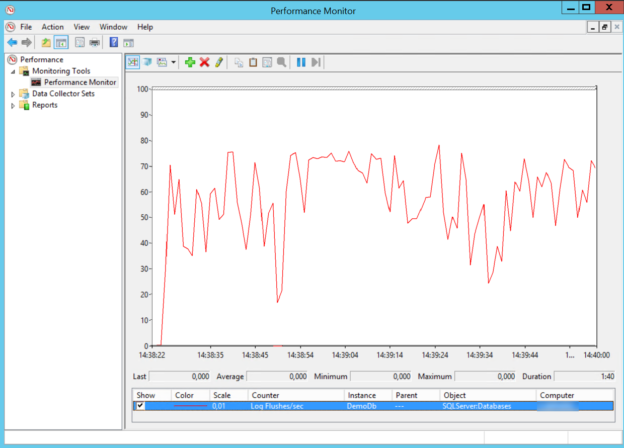
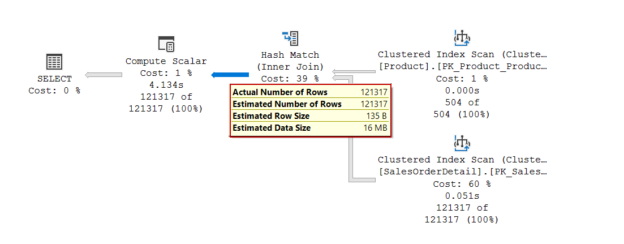
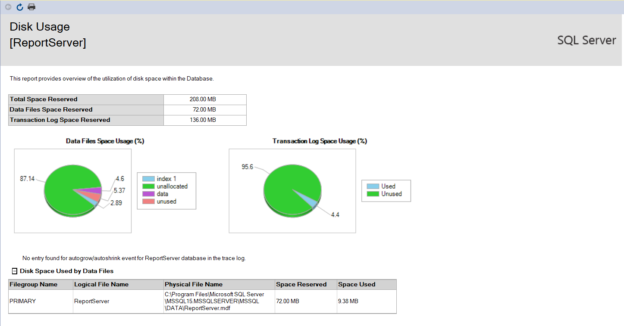
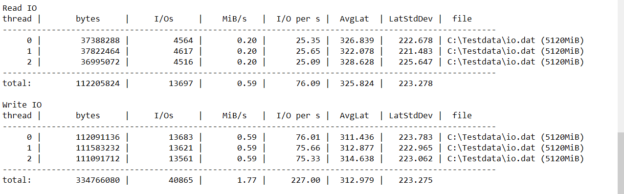
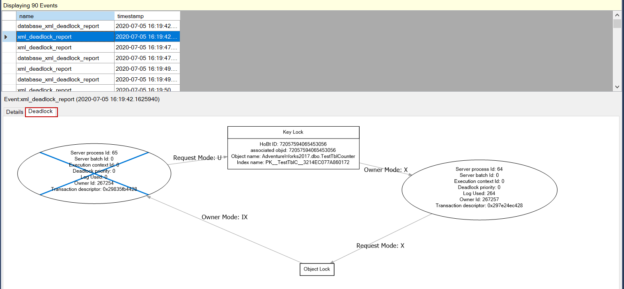
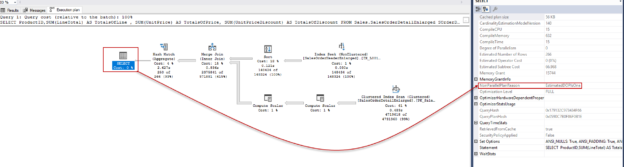
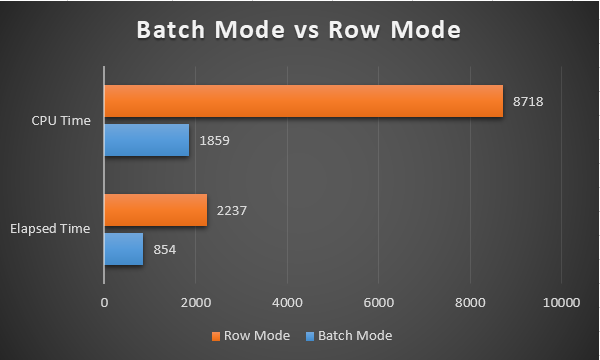
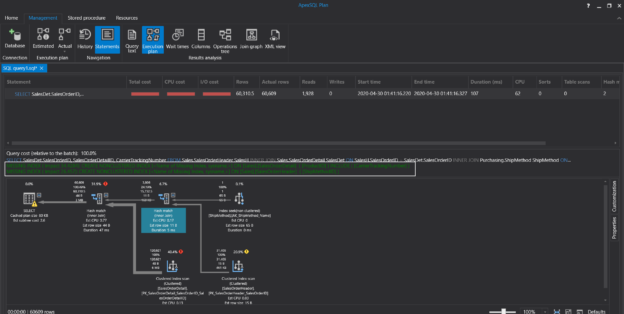
In this article, we will learn how to test our storage subsystems performance using Diskspd. The storage subsystem is one of the key performance factors for SQL Server because SQL Server storage engine stores database objects, tables, and indexes on the physical files. Therefore, the storage engine always interacts with the disk subsystem because of data processing. In this context, when a bottleneck occurs on the storage subsystems, it causes a
negative impact on SQL Server performance. It would be the right approach to measure the performance of the disks to be used before the SQL Server installation based on their usage purposes. For example, OLTP databases have to complete delete, insert, and update processes in a short time but OLAP databases handle a huge amount of batch data. In this case, the storage requirement of these two database systems should differ from each other. In short, it is a best practice to test and analyze the performance of the storage subsystems according to their usage purposes so that we can eliminate the I/O problems in advance.
Read more »