
In SQL Server, we normally use user-defined functions to write SQL queries. A UDF accepts parameters and returns the result as an output. We can use these UDFs in programming code and it allows writing up queries fast. We can modify a UDF independently of any other programming code.
In SQL Server, we have the following types of User-Defined Functions.
-
Scalar functions: Scalar user-defined functions return a single value. You will always have a RETURNS clause in it. The return value cannot be text, image or timestamp. Below is an example of Scalar functions.
12345678910Create FUNCTION dbo.ufnGetCustomerData (@CustomerID int)RETURNS varchar (50)ASBEGINDECLARE @CustomerName varchar(50);SELECT @CustomerName = customernameFROM [WideWorldImporters].[Sales].[Customers] CWHERE C.CustomerID=@CustomerIDRETURN @CustomerName;END;
Scalar user-defined functions are traditionally not considered a good option for high performance but SQL Server 2019 provides a way to improve performance on these scalar user-defined functions. We will learn more about it in a later section of the article.
-
Multi-statement table-valued functions (TVFs): Its syntax is similar to the scalar user-defined function and provides multi-values as output. These are also not performance optimized due tocardinality estimate issues.

SQL Server 2012 provides fixed cardinality estimates of one row while SQL Server 2012 provides estimates to 100. SQL Server 2017 improves the cardinality estimates for these MSTVF’s using the feature called interleaved execution.
- You can learn more about this feature in the article, SQL Server 2017: Interleaved Execution for mTVF.
-
Inline table-valued functions: Inline table values functions are performance optimized functions. They do not contain table definitions. The query batch inside this function is a single statement, therefore, it does not provide any performance issues when we use it batches or in loops.
Below is an example of inline table valued function.
1234567891011121314151617181920212223242526272829USE [WideWorldImporters]GOSET ANSI_NULLS ONGOSET QUOTED_IDENTIFIER ONGOCREATE FUNCTION [Application].[DetermineCustomerAccess](@CityID int)RETURNS TABLEWITH SCHEMABINDINGASRETURN (SELECT 1 AS AccessResultWHERE IS_ROLEMEMBER(N'db_owner') <> 0OR IS_ROLEMEMBER((SELECT sp.SalesTerritoryFROM [Application].Cities AS cINNER JOIN [Application].StateProvinces AS spON c.StateProvinceID = sp.StateProvinceIDWHERE c.CityID = @CityID) + N' Sales') <> 0OR (ORIGINAL_LOGIN() = N'Website'AND EXISTS (SELECT 1FROM [Application].Cities AS cINNER JOIN [Application].StateProvinces AS spON c.StateProvinceID = sp.StateProvinceIDWHERE c.CityID = @CityIDAND sp.SalesTerritory = SESSION_CONTEXT(N'SalesTerritory'))));GO
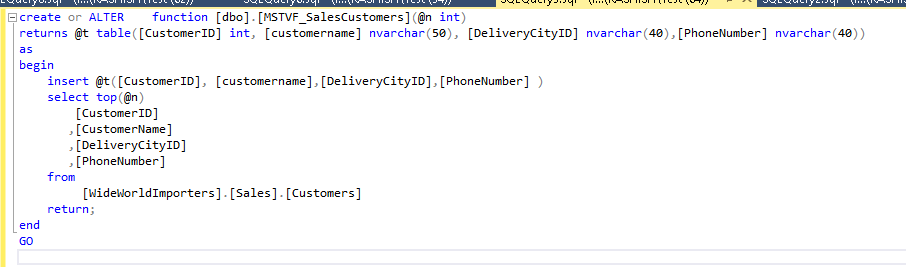
Scalar User Defined functions
As stated above, a Scalar User a defined function does not provide performance benefits in SQL Server. Therefore, in this section, we will first view the performance issues with scalar user-defined function and then use SQL Server 2019 to compare performance.
For this example, I am running SQL Server 2019 2.1 and WideWorldImporters database.
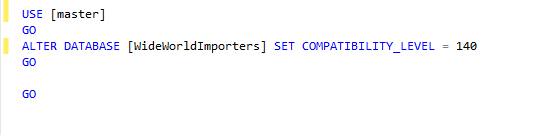
Set the database compatibility level to 140.
|
1 2 3 4 |
USE [master] GO ALTER DATABASE [WideWorldImporters] SET COMPATIBILITY_LEVEL = 140 GO |
Clear the procedural cache using the database scoped configuration option. This will clean our database from any stored execution plan or cache.
|
1 2 |
ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE ; Go |
Now create the scalar User defined function in WideWorldImporters database. This function will return the quantity based on the description. Execute the below script.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
CREATE OR ALTER FUNCTION Sales.SalesQuantity (@Description NVARCHAR(100)) RETURNS SMALLINT AS BEGIN DECLARE @Count SMALLINT SELECT @Count= Quantity FROM Sales.OrderLines WHERE Description=@Description; RETURN(@Count) END; GO |
We can use this function similar to a table column object. Run the below command which uses the UDF function as a normal table column.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
SET STATISTICS IO ON SET STATISTICS TIME ON SELECT Sol.orderid, sol.Description, Sales.SalesQuantity(sol.Description) as quantity, PickedQuantity FROM Sales.Orders as so JOIN Sales.OrderLines as sol on so.OrderId=sol.OrderID WHERE sol.PickingCompletedWhen >'2013-01-01 11:00:00.0000000' ORDER BY UnitPrice DESC GO |
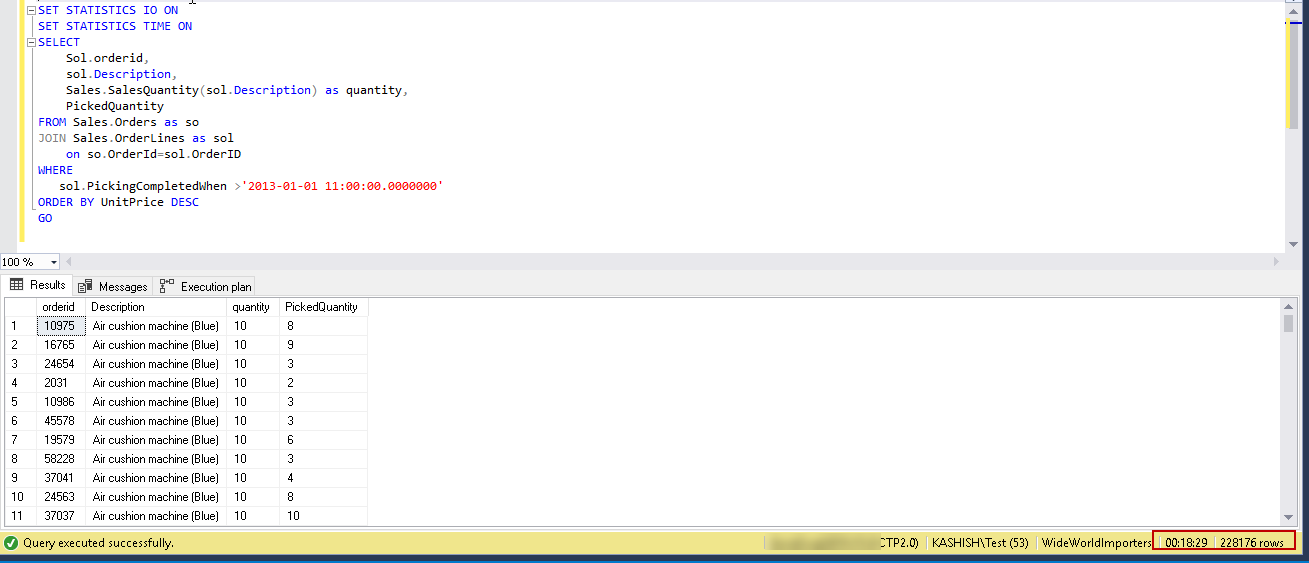
In the above screenshot, you can see that it took approx 18 minutes to process 228,176 records.
Now let us run the same query with the compatibility level 150 (SQL Server 2019).
|
1 2 3 4 5 6 |
USE [master] GO ALTER DATABASE [WideWorldImporters] SET COMPATIBILITY_LEVEL = 150 GO ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE ; Go |
Run the query again with this modified compatibility level.
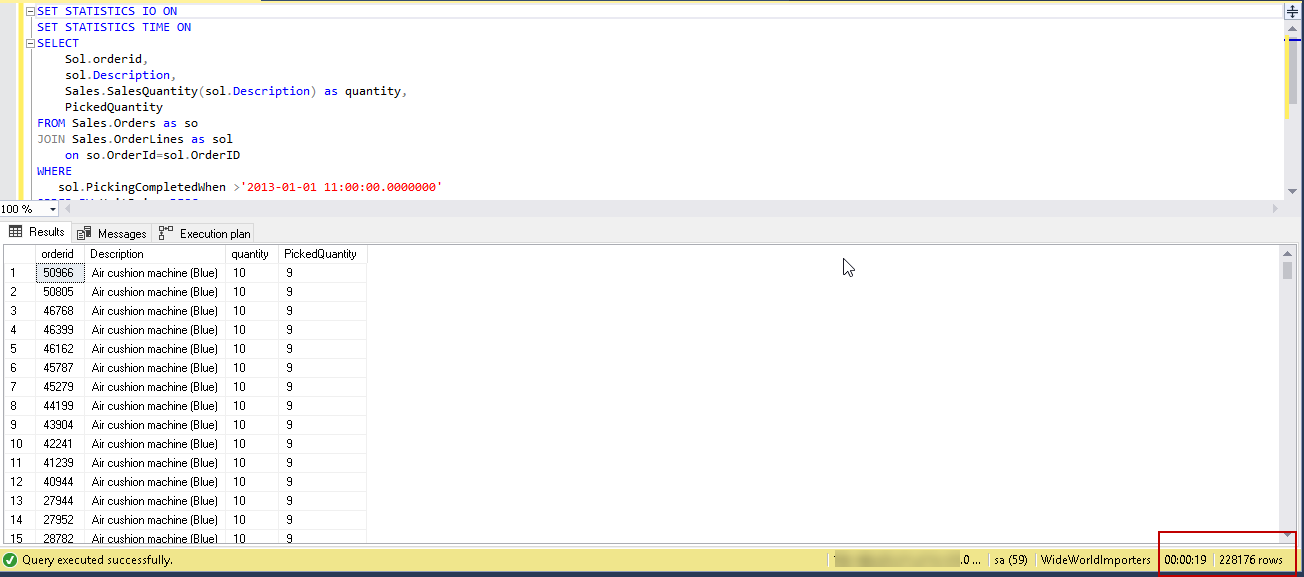
In SQL Server 2019, you can notice the query completed in just 19 seconds to process 228,176 rows compared to 12 minutes in SQL Server 2016. Relatively, it is very fast to process these results.
Now let us run the queries again in both SQL Server 2016 and SQL Server 2019 database compatibility level and capture the statistics IO and statistics time along with the actual execution plan to compare with.
SQL Server 2019 Statistics output
(228176 rows affected)
Table ‘OrderLines’. Scan count 5, logical reads 857, physical reads 0, read-ahead reads 0, lob logical reads 180, lob physical reads 0, lob read-ahead reads 0.
Table ‘OrderLines’. Segment reads 2, segment skipped 0.
Table ‘Worktable’. Scan count 227, logical reads 730037, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table ‘Workfile’. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(1 row affected)
SQL Server Execution Times:
CPU time = 15287 ms, elapsed time = 18782 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.

SQL Server 2016 Statistics output
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
(228176 rows affected)
Table ‘Worktable’. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table ‘OrderLines’. Scan count 1, logical reads 3504, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(1 row affected)
SQL Server Execution Times:
CPU time = 1071719 ms, elapsed time = 1109655 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.

If we compare both the execution with compatibility level 140 (SQL Server 2017) and 150 (SQL Server 2019), we can see a significant improvement over the CPU time and the elapsed time.

In below table, you can see the Scalar user-defined functions performance optimization comparison with SQL Server 2019
SQL Server Compatibility level 140 | SQL Server Compatibility level 150 | Performance Improvement |
CPU – 1,071,719 ms | CPU 15,287 ms | 1,056,432 ms |
Elapse time 1,109,655 ms | Elapse time 18,782 ms | 1,090,873 ms |
Execution plan comparison
In this section, we will compare the execution plan on running the scalar UDF with SQL Server 2019 and before.
Below is the actual execution plan when we run the scalar UDF with compatibility level 140( SQL Server 2017 or before)
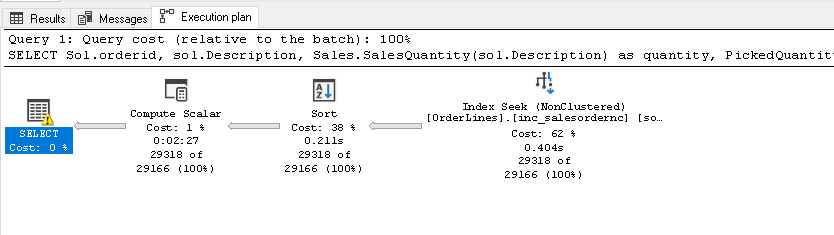
We will get a more clear idea about this in the estimated execution plan. In below plan, it shows the separate execution plan for both the query and the UDF function. Therefore, SQL Server treats Scalar UDF function as a separate identity until SQL Server 2017. SQL Server needs to do an extra work each time this UDF function is called.
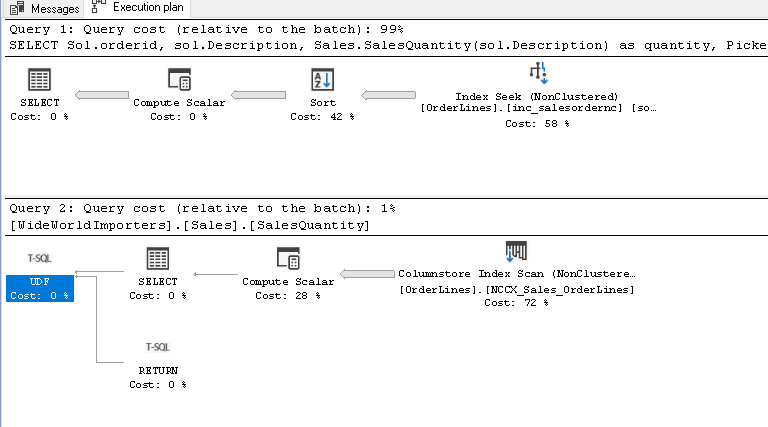
Now, if we look at the actual estimated plan in SQL Server 2019, we get a complex plan compare with the earlier execution plan, as shown in below image. In SQL Server 2019, it is able to combine the UDF operations into a single query plan due to inline functionality.
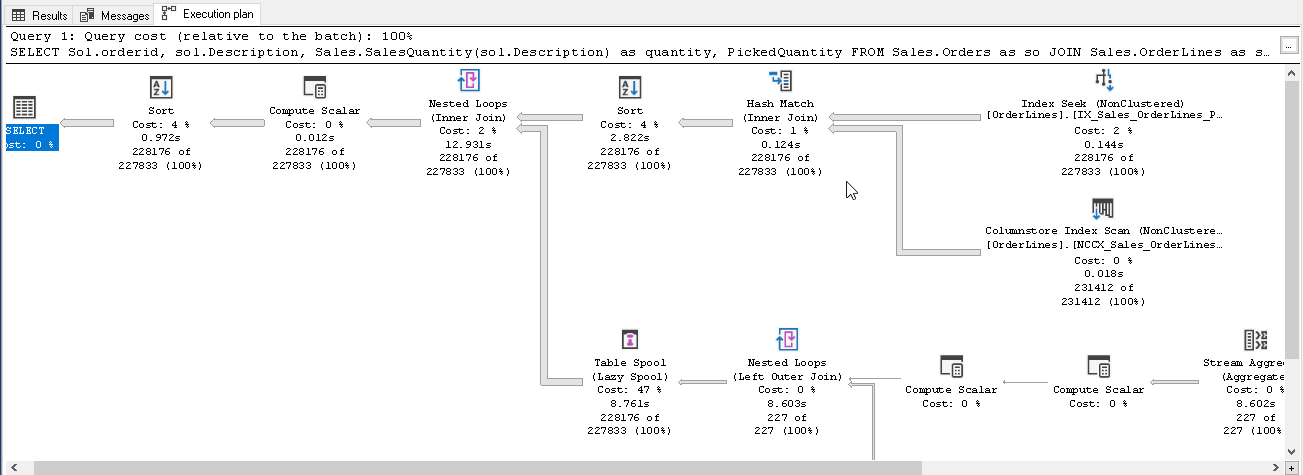
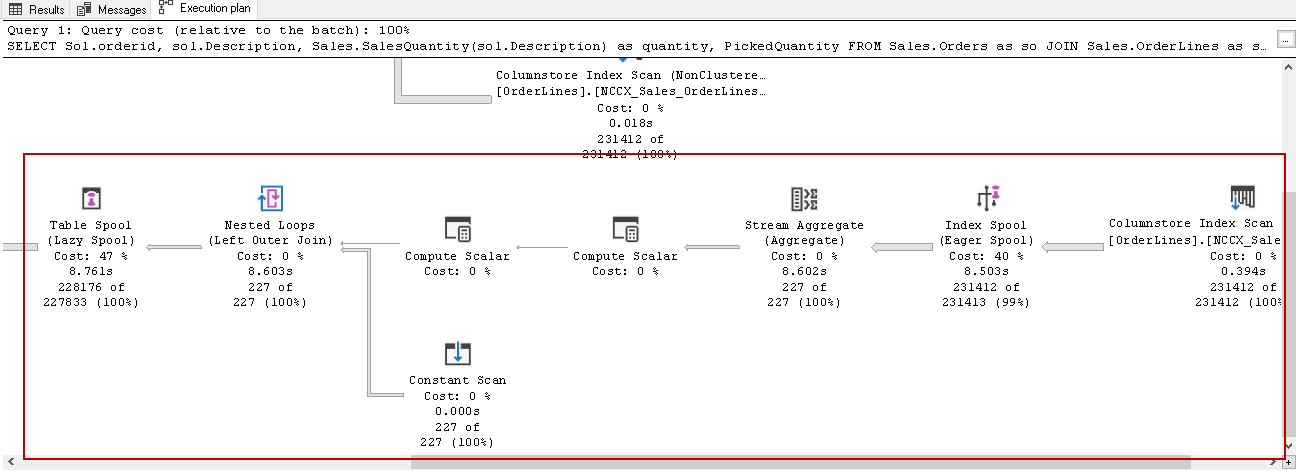
In this execution plan, it shows the UDF in the lower area. You can see multiple operators to execute the query. SQL Server 2019 inlines the scalar UDF to optimize the execution of the query. It does not consider this UDF as a separate identify however runs it similar to a normal select statement. Therefore, we get the performance benefits in terms of CPU, memory, execution time etc.
We can check whether the SQL Server is able to inline a particular scalar UDF or not. SQL Server 2019 introduced new column is_inlineable in sys.sql_modules. Run the below query and pass the scalar function name in it. In the below query, our UDF shows value 1 that means SQL Server 2019 can incline this function.
|
1 2 3 4 |
select o.name, sm.is_inlineable from sys.sql_modules sm join sys.objects o on sm.object_id = o.object_id where o.name = 'SalesQuantity'; |
Conditions to inline the scalar UDF in SQL Server 2019
SQL Server 2019 can inline the scalar function if the below conditions are met.
- UDF should not be a partition function
- It should not reference any table variables
- It should not use any computed column.
- We cannot call UDF in the Group By clause
- We can use below constructs in scalar UDF
- Declare
- Select
- If/ else
- Return
- Exits or IsNull
- UDF should not contain any time-dependent function.
Different ways to use SQL Server 2019 UDF incline functionality.
We can use this UDF inline functionality in SQL Server 2019 in the following ways.
- Set the database compatibility level to 150 (SQL Server 2019)
-
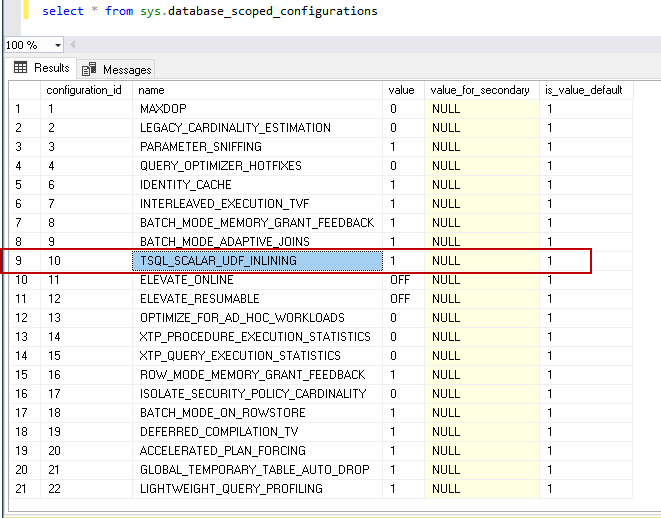
We can control this behavior using the new database coped configuration. You can see below in the database scoped configuration list, we have new option TSQL_SCALAR_UDF_INLINING
12345--Run the below query to turn on Scalar UDF Inlining in a particular databaseALTER DATABASE SCOPED CONFIGURATION SET TSQL_SCALAR_UDF_INLINING = ON;-- Run the below query to turn off Scalar UDF Inlining in a particular databaseALTER DATABASE SCOPED CONFIGURATION SET TSQL_SCALAR_UDF_INLINING = OFF; -
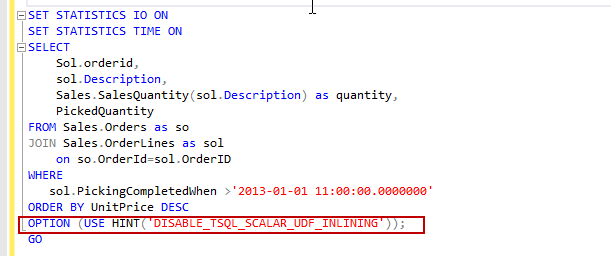
We can also disable scalar UDF inlining for a specific query by specifying the query hint:
1DISABLE_TSQL_SCALAR_UDF_INLINING
In this example, we have disabled UDF inlining with below parameter
1'OPTION(USE HINT ('DISABLE_TSQL_SCALAR_UDF_INLINING'))'
Note: If we have enabled the database scope configuration for scalar UDF inlining and use the query hint to disable this functionality at the query level, SQL Server will precedence to hint over the database scoped configuration or compatibility level setting.
-
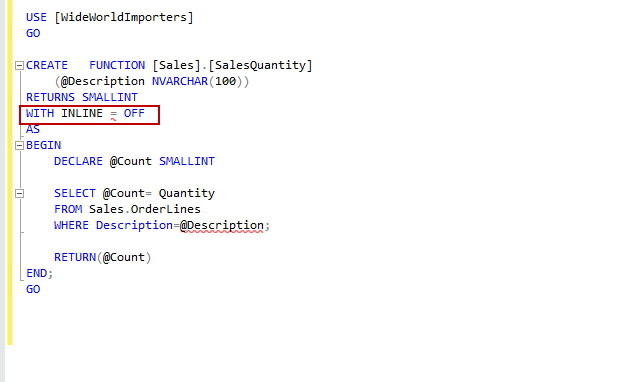
While creating the Scalar UDF, we can specify to turn off this functionality also. We need to specify WITH INLINE=OFF as in the following example
By default, Scalar UDF Inlining is enabled in SQL Server 2019, therefore, we do not need to specify the parameter WITH INLINE=ON. You can specify it if required.
Conclusion:
In this article, we explored the significant performance improvement of Scalar UDFs due to inlining. These enhancements will bring a smile of the face of the developers and the administrators as well. Explore this feature in your environment and you should see performance improvements.

I am the author of the book "DP-300 Administering Relational Database on Microsoft Azure". I published more than 650 technical articles on MSSQLTips, SQLShack, Quest, CodingSight, and SeveralNines.
I am the creator of one of the biggest free online collections of articles on a single topic, with his 50-part series on SQL Server Always On Availability Groups.
Based on my contribution to the SQL Server community, I have been recognized as the prestigious Best Author of the Year continuously in 2019, 2020, and 2021 (2nd Rank) at SQLShack and the MSSQLTIPS champions award in 2020.
Personal Blog: https://www.dbblogger.com
I am always interested in new challenges so if you need consulting help, reach me at rajendra.gupta16@gmail.com
View all posts by Rajendra Gupta
- Understanding PostgreSQL SUBSTRING function - September 21, 2024
- How to install PostgreSQL on Ubuntu - July 13, 2023
- How to use the CROSSTAB function in PostgreSQL - February 17, 2023