
In the previous articles of this series, SQL Server Execution Plans overview , SQL Server Execution Plans types and How to Analyze SQL Execution Plan Graphical Components, we discussed the steps that are performed by the SQL Server Relational Engine to generate the Execution Plan of a submitted query and the steps performed by the SQL Server Storage Engine to retrieve the requested data or perform the requested modification operation.
In addition, we clarified the different types and formats of the SQL Server Query Execution Plans that can be used for queries performance troubleshooting purposes. Finally, we discussed the graphical query plan components and how we can analyze it. In this article, we will go through the first set of SQL Query Plans operators.
Before starting with the Query Execution Plan operators, we will create a new simple table and fill it with testing data, using the T-SQL script below:
|
1 2 3 4 5 6 7 8 9 10 11 |
CREATE TABLE ExPlanOperator ( ID INT IDENTITY (1,1), First_Name VARCHAR(50), Last_name VARCHAR(50), Address VARCHAR(MAX) ) GO INSERT INTO ExPlanOperator VALUES ('AA','BB','CC') GO 1000 INSERT INTO ExPlanOperator VALUES ('DD','EE','FF') GO 1000 |
SQL Server Table Scan Operator
The previously created ExPlanOperator the table is a heap table, a table in which the data rows are not stored in any particular order within each data page, due to the fact that there is no Clustered index created over that table.
See the article SQL Server table structure overview for more details about the structure of the SQL Server tables.
So that, in order to return the result of any query on that table, the SQL Server Engine will scan all the entire table row by row using the Table Scan operator.
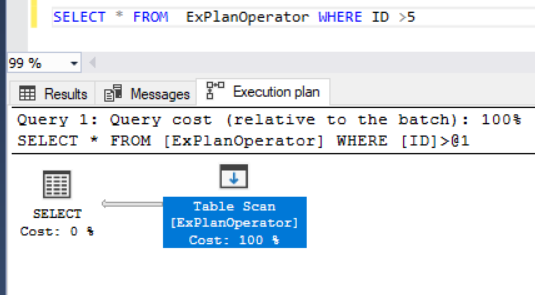
Assume that we run the below T-SQL statement that retrieves all the records from the ExPlanOperator test table after including the Actual Execution Plan of the query to see how it will behave. You will see from the generated SQL Query Execution plan that the SQL Server Engine will scan all the entire table rows, using the Table Scan operator, in order to retrieve the requested data, as shown below:
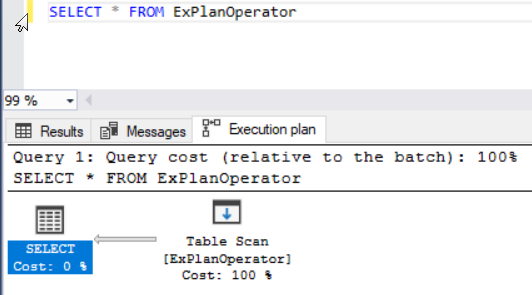
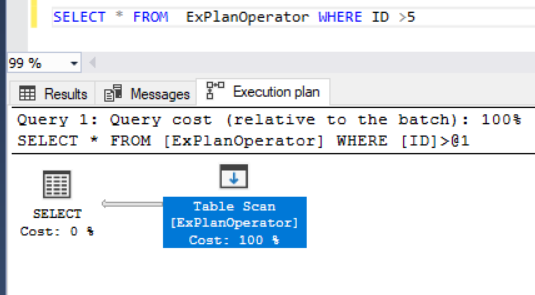
The SQL Server Engine will behave in the same way when we try to get a specific set of records by adding the WHERE clause. Where it will scan all the entire table rows using the Table Scan operator again, as there is no index created on that table to assist with the data retrieval, as shown below:
If we create a Non-Clustered index on the ID column on the testing table, using the CREATE INDEX T-SQL statement below:
|
1 |
CREATE INDEX IX_ExPlanOperator_ID ON ExPlanOperator (ID) |
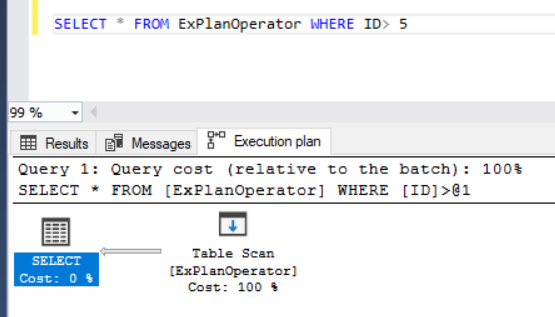
Then run the same SELECT statement to retrieve a specific set of IDs. You will see that the SQL Server Engine prefers to scan the entire table, row by row rather than using the created index. There are many reasons for such behavior. For example, the index is not useful, the table contains small number of rows or the query will return most of the table rows, as shown below:
SQL Server Clustered Index Scan Operator
When you create a Clustered index on the table, the table will be converted from a Heap table to a Clustered table. A clustered table is a table that has a predefined clustered index on one column or multiple columns of the table that defines the storing order of the rows within the data pages and the order of the pages within the table, based on the clustered index key.
For more information about the Clustered table structure, see SQL Server table structure overview. And for more information about the Clustered index, see Designing effective SQL Server clustered indexes.
Let us drop the Non-Clustered index that we created previously on the ExPlanOperator table and replace it with a Clustered index on the ID column on the ExPlanOperator table, using the T-SQL script below:
|
1 2 |
DROP INDEX IX_ExPlanOperator_ID on ExPlanOperator CREATE CLUSTERED INDEX IX_ExPlanOperator_ID ON ExPlanOperator (ID) |
If we run the same SELECT query that retrieves all rows from our testing table, and include the Actual SQL Query Execution plan of the query, you will see that the Table Scan operator will be replaced by the Clustered Index Scan operator, with the same arrow thickness as the one in the case of the Table Scan, as shown below:
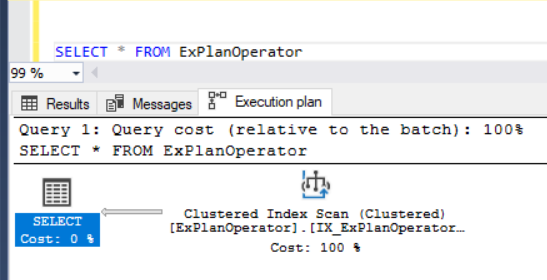
From the previous SQL Query Execution plan, the SQL Server Engine decides to use the Clustered Index Scan operator, although it will traverse all the index rows similar to how the Table Scan operator behaves. This is due to the fact that, the Clustered Index can be considered as a sorted replacement for the underlying table that stores all the table data at the lowest level of the index, also known as the leaf, in addition to the index key. If there is no useful Non-Clustered index due to out of date statistics, or the query will return all or most of the table rows, the SQL Server Engine will decide that using the Clustered Index Scan operator to scan all the Clustered index rows is faster than using the keys provided by the index.
SQL Server Clustered Index Seek Operator
If the previous SELECT query is modified to be more efficient by adding a data filtration statement in the WHERE clause, that limits the number of rows returned from the table, the SQL Server Query Optimizer decides to use a very fast way to retrieve the data using the Clustered Index Seek operator, as shown below:
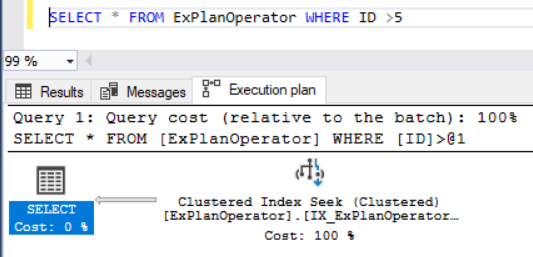
Rather than traversing all the table rows, the SQL Server Query Optimizer will locate the appropriate Clustered index and navigate it to retrieve the required rows by providing the SQL Server Storage Engine with the instructions to identify the required rows based on the key values of the selected index. In addition to processing the data quickly to retrieve the needed rows using the Clustered Index Seek operator, no extra steps required to retrieve the rest of the columns, as a full sorted copy of the table is stored in the leaf level nodes of the Clustered index.
SQL Server Non-clustered Index Seek Operator
When the SQL Server Query Optimizer finds that all the data that is requested by the query can be provided by an available index, it will perform a seek against that Non-Clustered index, using the Index Seek operator.
For more information about the Non-Clustered index, see Designing effective SQL Server clustered indexes.
Assume that we have created a Non-Clustered index on the First_Name column of the ExPlanOperator testing table, using the CREATE INDEX T-SQL Command below:
|
1 |
CREATE INDEX IX_ExPlanOperator_FirstName on ExPlanOperator(First_Name) |
Then run the below SELECT statement that retrieves the First_Name column, after including the Actual Execution Plan of the query, as below:
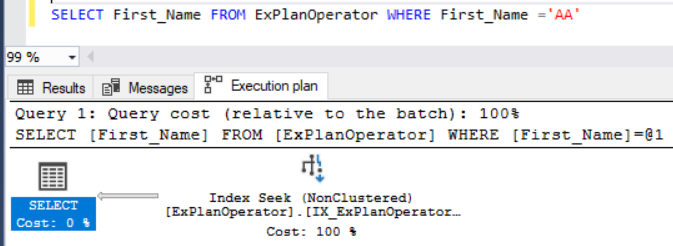
You will see from the SQL Query Execution plan that, the SQL Server Query Optimizer found that the created index contains all the data that is requested by the submitted query and that the fastest way to retrieve this data is seeking that Non-Clustered index. Recall that the Non-clustered index stores only the index key values and pointers to the rest of columns. If the SQL Server Query Optimizer is not able to find all the requested data in that index, it will look up for the additional data in the Clustered index, in the case of Clustered table, or in the underlying table, in the case of the Heap tables, affecting the query performance due to the additional I/O operations performed during the look up process, as we will see later in this series.
In the next article of this series, we will discuss the second set of the SQL Server Query Execution Plan operators. Stay tuned!
Table of contents

He is a Microsoft Certified Solution Expert in Data Management and Analytics, Microsoft Certified Solution Associate in SQL Database Administration and Development, Azure Developer Associate and Microsoft Certified Trainer.
Also, he is contributing with his SQL tips in many blogs.
View all posts by Ahmad Yaseen
- Azure Data Factory Interview Questions and Answers - February 11, 2021
- How to monitor Azure Data Factory - January 15, 2021
- Using Source Control in Azure Data Factory - January 12, 2021