
Description
Of the many ways in which query performance can go awry, few are as misunderstood as parameter sniffing. Search the internet for solutions to a plan reuse problem, and many suggestions will be misleading, incomplete, or just plain wrong.
This is an area where design, architecture, and understanding one’s own code are extremely important, and quick fixes should be saved as emergency last resorts.
Understanding parameter sniffing requires comfort with plan reuse, the query plan cache, and parameterization. This topic is so important and has influenced me so much that I am devoting an entire article to it, in which we will define, discuss, and provide solutions to parameter sniffing challenges.
Review of Execution Plan Reuse
SQL query optimization is both a resource and time intensive process. An execution plan provides SQL Server with instructions on how to efficiently execute a query and must be available prior to execution and is the product of the query optimization process whenever a query is executed.
Because it takes significant resources to generate an execution plan, SQL Server caches plans in memory in the query plan cache for later use. If the same query is executed multiple times, then the cached plan can be reused over and over, without the need to generate a new plan. This saves time and resources, especially for common queries that are executed frequently.
Execution plans are cached based on the exact text of the query. Any differences, even those as minor as a comment or capital letter, will result in a separate plan being generated and cached. Consider the following two queries:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
SELECT SalesOrderHeader.SalesOrderID, SalesOrderHeader.DueDate, SalesOrderHeader.ShipDate FROM Sales.SalesOrderHeader WHERE SalesOrderHeader.OrderDate = '2011-05-30 00:00:00.000'; SELECT SalesOrderHeader.SalesOrderID, SalesOrderHeader.DueDate, SalesOrderHeader.ShipDate FROM Sales.SalesOrderHeader WHERE SalesOrderHeader.OrderDate = '2011-05-31 00:00:00.000'; |
While the queries are very similar and will likely require the same execution plan, SQL Server will create a separate plan for each. This is because the filter is different, with the OrderDate being May 30th in the first query and May 31st in the second query. As a result, hard-coded literals in queries will result in different execution plans for each different value that is used in the query. If I ran the query above once for every day in the year 2011, then the result would be 365 queries and 365 different cached execution plans.
If the queries above are executed very often, then SQL Server will be forced to generate new plans frequently for all possible values of OrderDate. If OrderDate is a DATETIME and can (and will) have lots of distinct values, then we’ll see a very large number of execution plans getting created at a rapid pace.
The plan cache is stored in memory and its size is limited by available memory. Therefore, if excessive numbers of plans are generated over a short period of time, the plan cache could fill up. When this occurs, older plans are removed from cache in favor of newer ones. If memory pressure becomes significant, then the older plans being removed may end up being useful ones that we will need soon.
Parameterization
The solution to memory pressure in the plan cache is parameterization. For our query above, the DATETIME literal can be replaced with a parameter:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
CREATE PROCEDURE dbo.get_order_date_metrics @order_date DATETIME AS BEGIN SET NOCOUNT ON; SELECT SalesOrderHeader.SalesOrderID, SalesOrderHeader.DueDate, SalesOrderHeader.ShipDate FROM Sales.SalesOrderHeader WHERE SalesOrderHeader.OrderDate = @order_date; END |
When executed for the first time, an execution plan will be generated for this stored procedure that uses the parameter @order_date. All subsequent executions will use the same execution plan, resulting in the need for only a single plan, even if the proc is executed millions of times per day.
Parameterization greatly reduces churn in the plan cache and speeds up query execution as we can often skip the expensive optimization process that is needed to generate an execution plan.
What is Parameter Sniffing
Plan reuse is an important part of how execution plans are managed. The process of optimizing a query and assigning a plan to it is one of the most CPU-intensive processes in SQL Server. Since it is also a time-sensitive process, slowing down is not an option.
This is a good feature and one that saves immense server resources. A query that executes a million times a day can now be optimized once and the plan reused 999,999 times for free. While this feature is almost always good, there are times it can cause unexpected performance problems. This primarily occurs when the set of parameters that the execution plan was optimized for ends up being drastically different than the parameters that are being passed in right now. Maybe the initial optimization called for an index seek, but the current parameters suggest a scan is better. Maybe a MERGE join made sense the first time, but NESTED LOOPS is the right way to go now.
The following is an example of parameter sniffing:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
CREATE PROCEDURE dbo.get_order_metrics_by_sales_person @sales_person_id INT AS BEGIN SET NOCOUNT ON; SELECT SalesOrderHeader.SalesOrderID, SalesOrderHeader.DueDate, SalesOrderHeader.ShipDate FROM Sales.SalesOrderHeader WHERE ISNULL(SalesOrderHeader.SalesPersonID, 0) = @sales_person_id; END |
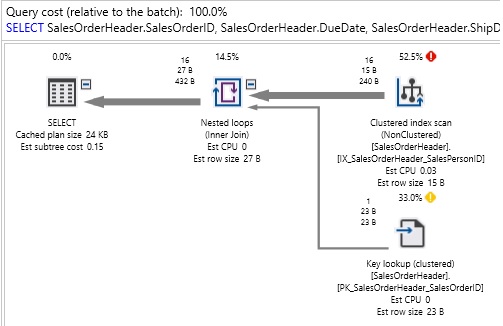
This stored procedure searches SalesOrderHeader based on the ID of the sales person, including a catch-all for NULL IDs. When we execute it for a specific sales person (285), we get the following IO and execution plan:
Table ‘SalesOrderHeader’. Scan count 1, logical reads 105, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
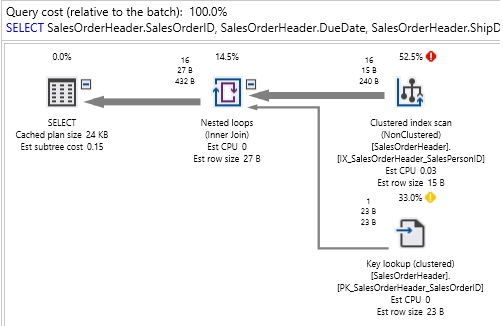
We can see that SQL Server used a scan on a nonclustered index, as well as a key lookup to return the data we were looking for. If we were to clear the execution plan cache and rerun this for a parameter value of 0, then we would get a different plan:
Table ‘SalesOrderHeader’. Scan count 1, logical reads 698, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
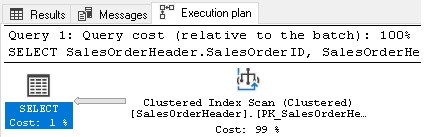
Because so many rows were being returned by the query, SQL Server found it more efficient to scan the table and return everything, rather than methodically seek through an index to return 95% of the table. In each of these examples, the execution plan chosen was the best plan for the parameter value passed in.
How will performance look if we were to execute the stored procedure for a parameter value of 285 and not clear the plan cache?
Table ‘SalesOrderHeader’. Scan count 1, logical reads 698, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
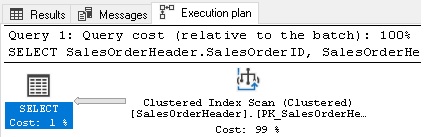
The correct execution plan involved a scan of a nonclustered index with a key lookup, but since we reused our most recently generated execution plan, we got a clustered index scan instead. This plan cost us six times more reads, pulling significantly more data from storage than was needed to process the query and return our results.
The behavior above is a side-effect of plan reuse and is the poster-child for what this article is all about. For our purposes, parameter sniffing will be defined as undesired execution plan reuse.
Finding and Resolving Parameter Sniffing
How do we diagnose parameter sniffing? Once we know that performance is suboptimal, there are a handful of giveaways that help us understand when this is occurring:
- A stored procedure executes efficiently sometimes, but inefficiently at other times.
- A good query begins performing poorly when no changes are made to database schema.
- A stored procedure has many parameters and/or complex business logic enumerated within it.
- A stored procedure uses extensive branching logic.
- Playing around with the TSQL appears to fix it temporarily.
- Hacks fix it temporarily
Of the many areas of SQL Server where performance problems rear their head, few are handled as poorly as parameter sniffing. There often is not an obvious or clear fix, and as a result we implement hacks or poor choices to resolve the latency and allow us to move on with life as quickly as possible. An immense percentage of the content available online, in publications, and in presentations on this topic is misleading, and encourages the administrator to take shortcuts that do not truly fix a problem. There are definitive ways to resolve parameter sniffing, so let’s look at many of the possible solutions (and how effective they are).
I am not going to go into excruciating detail here. MSDN documents the use of different hints/mechanics well. Links are included at the end of the article to help with this, if needed.
Redeclaring Parameters Locally
Rating: It’s a trap!
This is a complete cop-out, plain and simple. Call it a cheat, a poor hack, or a bandage as that is all it is. Because the value of local variables is not known until runtime, the query optimizer needs to make a very rough estimate of row counts prior to execution. This estimate is all we get, and statistics on the index will not be effectively used to determine the best execution plan. This estimate will sometimes be good enough to resolve a parameter sniffing issue and give the illusion of a job well done.
The effect of using local variables is to hide the value from SQL Server. It’s essentially applying the hint “OPTIMIZE FOR UNKNOWN” to any query component that references them. The rough estimate that SQL Server uses to optimize the query and generate an execution plan will be right sometimes, and wrong other times. Typically the way this is implemented is as follows:
- Performance problem is identified.
- Parameter sniffing is determined to be the cause.
- Redeclaring parameters locally is a solution found on the internet.
- Try redeclaring parameters locally and the performance problem resolves itself.
- Implement the fix permanently.
- 3 months later, the problem resurfaces and the cause is less obvious.
What we are really doing is fixing a problem temporarily and leaving behind a time bomb that will create problems in the future. The estimate by the optimizer may work adequately for now, but eventually will not be adequate and we’ll have resumed performance problems. This solution works because oftentimes a poor estimate performs better than badly times parameter sniffing, but only at that time. This is a game of chance in which a low probability event (parameter sniffing) is crossed with a high probability event (a poor estimate happening to be good enough) to generate a reasonable illusion of a fix.
To demo this behavior, we’ll redeclare a parameter locally in our stored procedure from earlier:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
IF EXISTS (SELECT * FROM sys.procedures WHERE procedures.name = 'get_order_metrics_by_sales_person') BEGIN DROP PROCEDURE dbo.get_order_metrics_by_sales_person; END GO CREATE PROCEDURE dbo.get_order_metrics_by_sales_person @sales_person_id INT AS BEGIN SET NOCOUNT ON; DECLARE @sales_person_id_local INT = @sales_person_id; SELECT SalesOrderHeader.SalesOrderID, SalesOrderHeader.DueDate, SalesOrderHeader.ShipDate FROM Sales.SalesOrderHeader WHERE SalesOrderHeader.SalesPersonID = @sales_person_id_local; END |
When we execute this for different values, we get the same plan each time. Clearing the proc cache has no effect either:
|
1 2 3 4 5 6 7 |
EXEC dbo.get_order_metrics_by_sales_person @sales_person_id = 285; DBCC FREEPROCCACHE EXEC dbo.get_order_metrics_by_sales_person @sales_person_id = 0; EXEC dbo.get_order_metrics_by_sales_person @sales_person_id = 285; DBCC FREEPROCCACHE EXEC dbo.get_order_metrics_by_sales_person @sales_person_id = 285; EXEC dbo.get_order_metrics_by_sales_person @sales_person_id = 0; |
For each execution, the result is:
Table ‘SalesOrderHeader’. Scan count 1, logical reads 698, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
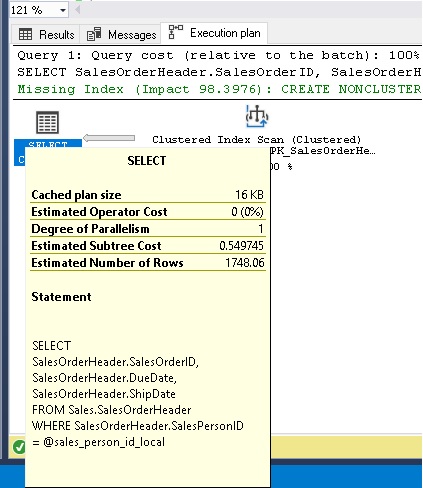
When we hover over the results, we can see that the estimated number of rows was 1748, but the actual rows returned by the query was 16. Seeing a huge disparity between actual and estimated rows is an immediate indication that something is wrong. While that could be indicative of stale statistics, seeing local variables in the query should be a warning sign that they are related. In this example, the local variable forced the same mediocre execution plan for all runs of the query, regardless of details. This may sometimes give an illusion of adequate performance, but will rarely do so for long.
To summarize: declaring local variables, assigning parameter values to them, and using the local variables in subsequent queries is a very bad idea and we should never, ever do this! If a short-term hack is needed, there are far better ones to use than this 🙂
OPTION (RECOMPILE)
Rating: Potentially useful
When this query hint is applied, a new execution plan will be generated for the current parameter values supplied. This automatically curtails parameter sniffing as there will be no plan reuse when this hint is used. The cost of this hint are the resources required to generate a new execution plan. By creating a new plan with each execution, we will pay the price of the optimization process with each and every execution.
This option is also an easy way out and should not be blindly used. This hint is only useful on queries or stored procedures that execute infrequently as the cost to generate a new execution plan will not be incurred often. For important OLTP queries that are being executed all day long, this is a harmful option and would be best avoided as we would sacrifice valuable resources on an ongoing basis to avoid parameter sniffing.
OPTION RECOMPILE works best on reporting queries, infrequent or edge-case queries, and in scenarios where all other optimization techniques have failed. For highly unpredictable workloads, it can be a reliable way to ensure that a good plan is generated with each execution, regardless of parameter values. Here is a quick example of OPTION (RECOMPILE) from above:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
IF EXISTS (SELECT * FROM sys.procedures WHERE procedures.name = 'get_order_metrics_by_sales_person') BEGIN DROP PROCEDURE dbo.get_order_metrics_by_sales_person; END GO CREATE PROCEDURE dbo.get_order_metrics_by_sales_person @sales_person_id INT AS BEGIN SET NOCOUNT ON; SELECT SalesOrderHeader.SalesOrderID, SalesOrderHeader.DueDate, SalesOrderHeader.ShipDate FROM Sales.SalesOrderHeader WHERE SalesOrderHeader.SalesPersonID = @sales_person_id OPTION (RECOMPILE); END GO |
The results of this change are that the stored procedure runs with an excellent execution plan each time:
Table ‘SalesOrderHeader’. Scan count 1, logical reads 50, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
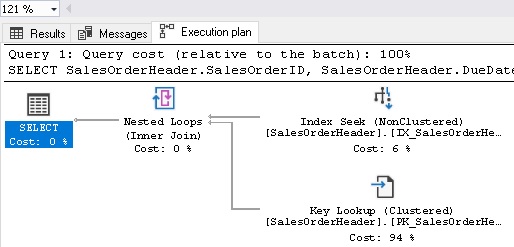
It is important to note that if this query hint is utilized and the query later begins to be used more often, you will want to consider removing the hint to prevent excessive resource consumption by the query optimizer as it constantly generates new plans. OPTION RECOMPILE is useful in a specific set of circumstances and should be applied carefully, only when needed, and only when the query is not executed often. To review, OPTION (RECOMPILE) is best used when:
- A query is executed infrequently.
- Unpredictable parameter values result in optimal execution plans that vary greatly with each execution.
- Other optimization solutions were unavailable or unsuccessful.
As with all hints, use it with caution, and only when absolutely needed.
Dynamic SQL
Rating: Potentially useful
While dynamic SQL can be an extremely useful tool, this is a somewhat awkward place to use it. By wrapping a troublesome TSQL statement in dynamic SQL, we remove it from the scope of the stored procedure and another execution plan will be generated exclusively for the dynamic SQL. Since execution plans are generated for specific TSQL text, a dynamic SQL statement with any variations in text will generate a new plan.
For all intents and purposes, using dynamic SQL to resolve parameter sniffing is very similar to using a RECOMPILE hint. We are going to generate more execution plans with greater granularity in an effort to sidestep the effects of parameter sniffing. All of the caveats of recompilation apply here as well. We do not want to generate excessive quantities of execution plans as the resource cost to do so will be high.
One benefit of this solution is that we will not create a new plan with each execution, but only when the parameter values change. If the parameter values don’t change often, then we will be able to reuse plans frequently and avoid the heavy repeated costs of optimization.
A downside to this solution is that it is confusing. To a developer, it is not immediately obvious why dynamic SQL was used, so additional documentation would be needed to explain its purpose. While using dynamic SQL can sometimes be a good solution, it is the sort that should be implemented very carefully and only when we are certain we have a complete grasp of the code and business logic involved. As with RECOMPILE, if the newly created dynamic SQL suddenly begins to be executed often, then the cost to generate new execution plans may become a burden on resource consumption. Lastly, remember to cleanse inputs and ensure that string values cannot be broken or modified by apostrophes, percent signs, brackets, or other special characters.
Here is an example of this usage:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
IF EXISTS (SELECT * FROM sys.procedures WHERE procedures.name = 'get_order_metrics_by_sales_person') BEGIN DROP PROCEDURE dbo.get_order_metrics_by_sales_person; END GO CREATE PROCEDURE dbo.get_order_metrics_by_sales_person @sales_person_id INT AS BEGIN SET NOCOUNT ON; DECLARE @sql_command NVARCHAR(MAX); SELECT @sql_command = ' SELECT SalesOrderHeader.SalesOrderID, SalesOrderHeader.DueDate, SalesOrderHeader.ShipDate FROM Sales.SalesOrderHeader WHERE SalesOrderHeader.SalesPersonID = ' + CAST(@sales_person_id AS VARCHAR(MAX)) + '; '; EXEC sp_executesql @sql_command; END GO |
Our results here are similar to using OPTION (RECOMPILE), as we will get good IO and execution plans generated each time. To review wrapping a TSQL statement in dynamic SQL and hard-coding parameters into that statement can be useful when:
- A query is executed infrequently OR parameter values are not very diverse.
- Different parameter values result in wildly different execution plans.
- Other optimization solutions were unavailable or unsuccessful.
- OPTION (RECOMPILE) resulted in too many recompilations.
OPTIMIZE FOR
Rating: Potentially useful, if you really know your code!
When we utilize this hint, we explicitly tell the query optimizer what parameter value to optimize for. This should be used like a scalpel, and only when we have complete knowledge of and control over the code in question. To tell SQL Server that we should optimize a query for any specific value requires that we know that all values used will be similar to the one we choose.
This requires knowledge of both the business logic behind the poorly performing query and any of the TSQL in and around the query. It also requires that we can see the future with a high level of accuracy and know that parameter values will not shift in the future, resulting in our estimates being wrong.
One excellent use of this query hint is to assign optimization values for local variables. This can allow you to curtail the rough estimates that would otherwise be used. As with parameters, you need to know what you are doing for this to be effective, but there is at least a higher probability of improvement when our starting point is “blind guess”.
Note that OPTIMIZE FOR UNKNOWN has the same effect as using a local variable. The result will typically behave as if a rough statistical estimate were used and will not always be adequate for efficient execution. Here’s how its usage looks:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
IF EXISTS (SELECT * FROM sys.procedures WHERE procedures.name = 'get_order_metrics_by_sales_person') BEGIN DROP PROCEDURE dbo.get_order_metrics_by_sales_person; END GO CREATE PROCEDURE dbo.get_order_metrics_by_sales_person @sales_person_id INT AS BEGIN SET NOCOUNT ON; SELECT SalesOrderHeader.SalesOrderID, SalesOrderHeader.DueDate, SalesOrderHeader.ShipDate FROM Sales.SalesOrderHeader WHERE SalesOrderHeader.SalesPersonID = @sales_person_id OPTION (OPTIMIZE FOR (@sales_person_id = 285)); END |
With this hint in place, all executions will utilize the same execution plan based on the parameter @sales_person_id having a value of 285. OPTIMIZE FOR is most useful in these scenarios:
- A query executes very similarly all the time.
- We know our code very well and understand the performance of it thoroughly.
- Row counts processed and returned are consistently similar.
- We have a high level of confidence that these facts will not change in the future.
OPTIMIZE FOR can be a useful way to control variables and parameters to ensure optimal performance, but it requires knowledge and confidence in how a query or stored procedure operates so that we do not introduce a future performance problem when things change. As with all hints, use it with caution, and only when absolutely needed.
Create a Temporary Stored Procedure
Rating: Potentially useful, in very specific scenarios
One creative approach towards parameter sniffing is to create a temporary stored procedure that encapsulates the unstable database logic. The temporary proc can be executed as needed and dropped when complete. This isolates execution patterns and limits the lifespan of its execution plan in the cache.
A temporary stored procedure can be created and dropped similarly to a standard stored procedure, though it will persist throughout a session, even if a batch or scope is ended:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
CREATE PROCEDURE #get_order_metrics_by_sales_person @sales_person_id INT AS BEGIN SET NOCOUNT ON; SELECT SalesOrderHeader.SalesOrderID, SalesOrderHeader.DueDate, SalesOrderHeader.ShipDate FROM Sales.SalesOrderHeader WHERE SalesOrderHeader.SalesPersonID = @sales_person_id OPTION (OPTIMIZE FOR (@sales_person_id = 285)); END GO EXEC #get_order_metrics_by_sales_person @sales_person_id = 285; EXEC #get_order_metrics_by_sales_person @sales_person_id = 0; GO DROP PROCEDURE #get_order_metrics_by_sales_person; GO |
When executed, the performance will mirror a newly created stored procedure, with no extraneous history to draw on for an execution plan. This is great for short-term tasks, temporary needs, releases, or scenarios in which data patterns change on a mid-term basis and can be controlled. Temporary stored procs can be declared as global as well by using “##” in front of the name, instead of “#”. This is ill-advised for the same reason that global temporary tables are discouraged, as they possess no security, and maintainability becomes a hassle across many databases or the entire server.
The benefits of temporary stored procedures are:
- Can control stored proc and plan existence easily.
- Facilitates accurate execution plans for data that is consistent in the short term, but varies long-term.
- Documents the need/existence for temporary business logic.
This is a little-known feature and few take advantage of it, but it can provide a useful way to guarantee good execution plans without the need to hack apart code too much in doing so.
Disable Parameter Sniffing (Trace Flag 4136)
Rating: Occasionally useful, but typically a bad idea!
This trace flag disables plan reuse, and therefore stops parameter sniffing. It may be implemented on a server-wide basis or as a query hint option. The result is similar to adding OPTIMIZE FOR UNKNOWN to any query affected. Specific query hints override this, though, such as OPTIN (RECOMPILE) or OPTIMIZE FOR.
Like query hints, trace flags should be applied with extreme caution. Adjusting the optimizer’s behavior is rarely a good thing and will typically cause more harm than good. OPTIMIZE FOR UNKNOWN, like using local variables, will result in generic execution plans that do not use accurate statistics to make their decisions.
Making rough estimates with limited data is already dangerous. Applying that tactic to an entire server or set of queries is likely to be more dangerous. This trace flag can be useful when:
- Your SQL Server has a unique use-case that you fully understand.
- Plan reuse is undesired server-wide.
- Usage patterns will not change in the foreseeable future.
While there are a few legitimate uses of this trace flag in SQL Server, parameter sniffing is not the problem we want to try and solve with it. It is highly unlikely that this will provide a quality, long-term solution to a parameter-related optimization problem.
Improve Business Logic
Rating: Very, very good!
Suboptimal parameter sniffing is often seen as an anomaly. The optimizer makes bad choices or solar flares somehow intersect with your query’s execution or some other bad thing happens that warrants quick & reckless actions on our part. More often than not, though, parameter sniffing is the result of how we wrote a stored procedure, and not bad luck. Here are a few common query patterns that can increase the chances of performance problems caused by parameter sniffing:
Too Many Code Paths
When we add code branching logic to procedural TSQL, such as by using IF…THEN…ELSE, GOTO, or CASE statements, we create code paths that are not always followed, except when specific conditions are met.
Since an execution plan is generated ahead of time, prior to knowing which code path will be chosen, it needs to guess as to what the most probable and optimal execution plan will be, regardless of how conditionals are met.
Code paths are sometimes implemented using “switch” parameters that indicate a specific type of report or request to be made. Switch parameters may indicate if a report should return detailed data or summary data. They may determine which type of entity to process. They may decide what style of data to return at the end. Regardless of form, these parameters contribute heavily to poor parameter sniffing as the execution plan will not change when parameters do change. Use switch parameters cautiously, knowing that if many different values are passed in frequently, the execution plan will not change.
This is in no way to suggest that conditional code is bad, but that a stored procedure with too many code paths will be more susceptible to suboptimal parameter sniffing, especially if those code paths are vastly different in content and purpose. Here are a few suggestions for reducing the impact of this problem:
- Consider breaking out large conditional sections of TSQL into new stored procedures. A large block of important code may very well be more appropriate as its own stored procedure, especially if it can be reused elsewhere.
- Move business branching logic into code. Instead of making a stored procedure decide what data to return or how to return it, have the application decide and let SQL Server manage what it does best: reading and writing of data! The purpose of a database is to store and retrieve data, not to make important business decisions or beautify the data.
- Avoid unnecessary conditionals, especially GOTO. This causes execution to jump around and is not only confusing for developers to understand, but makes optimization challenging for SQL Server.
Too Many Parameters
Each parameter adds another level of complexity to the job of the query optimizer. Similar to how a query becomes more complex with each table added, a stored procedure will become more challenging to optimize a plan for with each parameter that is added.
An execution plan will be created for the first set of parameters and reused for all subsequent sets, even if the values change significantly. Like when too many code paths exist in a stored procedure, it becomes challenging to pick a good execution plan will also happen to be good for all possible future executions.
A stored procedure with ten or twenty or thirty parameters may be trying to accomplish too many things at once. Consider splitting the proc into smaller, more portable ones. Also, consider removing parameters that are not necessary. Sometimes a parameter will always have the same value, not get used, or have its value overridden later in the proc. Sometimes the logic imposed by a specific parameter is no longer needed and it can be removed with no negative impact.
Reducing the number of parameters in a stored procedure will automatically reduce the potential for parameter sniffing to become problematic. It may not always be an easy solution, but it’s the simplest way to solve this problem without having to resort to hacks or trickery.
Overly Large Stored Procedure. AKA: Too Much Business Logic in the Database
Even if the parameter list is short, a very long stored procedure will have more decisions to make and more potential for an execution plan to not be the one-size-fits-all solution. If you’re running into a performance problem on line 16,359, you may want to consider dividing up the stored procedure into smaller ones. Alternatively, a rewrite that reduces the amount of necessary code can also help.
Oftentimes new features in SQL Server allow for code to be written more succinctly. For example, MERGE, OUTPUT, or common-table expressions can take long and complex TSQL statements and make them shorter and simpler.
If a stored proc is not long due to having many code paths or too many parameters, it may be due to using the database as a presentation tool. SQL Server, like all RDBMS, is optimized for the quick storage and retrieval of data. Formatting, layout, and other presentation considerations can be made in SQL Server, but it simply isn’t what it is best at. While the query optimizer generally has no trouble managing queries that adjust formatting, color, and layout as they are relatively simple in nature, we still incrementally add more complexity to a stored proc when we let it manage these aspects of data presentation.
Another reason why a stored procedure can become too long is because it contains too much business logic. Decision-making, presentation, and branching all are costly and difficult to optimize a universal execution plan for. Reporting applications are excellent at managing parameters and decision-making processes. Application code is built for branching, looping, and making complex decisions. Pushing business logic from stored procedures, functions, views, and triggers into applications will greatly simplify database schema and improve performance.
Reducing the size of a stored procedure will improve the chances that the execution plan generated for it is more likely to be good for all possible parameter values. Removing code paths and parameters helps with this, as does removing presentation-layer decisions that are made within the proc.
Conclusion
To wrap up our discussion of parameter sniffing, it is important to be reminded that this is a feature and not a bug. We should not be automatically seeking workarounds, hacks, or cheats to make the problem go away. Many quick fixes exist that will resolve a problem for now and allow us to move on to other priorities. Before adding query hints, trace flags, or otherwise hobbling the query optimizer, consider every alternate way to improve performance. Local variables, dynamic SQL, RECOMPILE, and OPTIMIZE for are too often cited as the best solutions, when in fact they are typically misused.
When a performance problem due to parameter sniffing occurs frequently, it is more likely the result of design and architecture decisions than a query optimizer quirk. When implementing hints, trace flags, or other targeted solutions, be sure they are durable enough to withstand the test of time. A good fix now that breaks performance in 6 months is not a very good fix. If special cases for parameters exist, consider handling them separately by breaking a large stored procedure into smaller ones, removing parameters, or reducing the implementation of business logic in the database.
By taking the time to more fully analyze a parameter sniffing problem, we can improve overall database performance and the scalability of an application. Instead of creating hacks to solve problems quickly, we can make code more durable at little additional cost to developers. The result will be saved time and resources in the long run, and an application that performs more consistently.
Table of contents
| Query optimization techniques in SQL Server: the basics |
| Query optimization techniques in SQL Server: tips and tricks |
| Query optimization techniques in SQL Server: Database Design and Architecture |
| Query Optimization Techniques in SQL Server: Parameter Sniffing |

In his free time, Ed enjoys video games, sci-fi & fantasy, traveling, and being as big of a geek as his friends will tolerate.
View all posts by Ed Pollack
- SQL Server Database Metrics - October 2, 2019
- Using SQL Server Database Metrics to Predict Application Problems - September 27, 2019
- SQL Injection: Detection and prevention - August 30, 2019