
Summary
There are few topics so widely misunderstood and that generates such frequent bad advice as that of the decision of how to index a table. Specifically, the decision to use a heap over a clustered index is one where misinformation spreads quite frequently.
This article is a dive into SQL Server internals, performance testing, temporary objects, and all topics that relate to the choice of heap vs. clustered index.
The Common Misconceptions
Have you ever heard any of these statements?
- A heap is faster than a clustered index because there is less overhead to write data to it
- Clustered indexes take resources to create and maintain and may not be worth it
- Heaps allow for faster access to random data
- Heaps are smaller and take up less storage and memory resources
The internet is full of these and many other statements that are either false or that address edge-cases so extremely that they should not be introduced without that predicate. Many of these ideas seep into our development teams and become a topic of debate or conversation, ultimately influencing how we design database objects and access them.
What is a Heap? What is a Clustered Index?
When we discuss these terms, we are referring to the underlying logical structure of a table. This has little impact on our ability to query a table and return results. Ignoring the impact of latency, we can access data in a table successfully, regardless of how we index it. The focus of this article will be on query performance and how these choices will make our queries faster or slower, as this will often be the key metric of success when reviewing application speed.
Heaps
A heap is a table that is stored without any underlying order. When rows are inserted into a heap, there is no way to ensure where the pages will be written nor are those pages guaranteed to remain in the same order as the table is written to or when maintenance is performed against it.
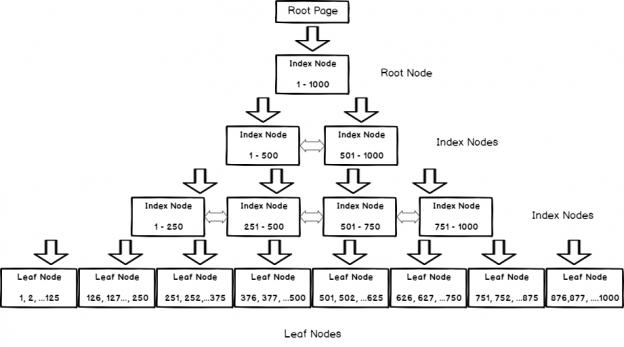
Logically, the heap is comprised of an Index Allocation Map (IAM) that points to all pages within the heap. Each page will contain as many rows of data as will fit, as they are written. Within the heap, there is no linking or organization between the pages. All reads and writes must consult the IAM first to read all pages within a heap. The following illustration shows a simplified model of a heap:
While there are many other considerations about how a heap is stored and how its data is managed, the most important aspect of it is lack of order. The primary reason why heaps behave as they do will be that the rows are stored without any specified order. This fact will have generally negative implications on read and write operations.
Clustered Index
The alternative to an unordered heap is to define a table with a clustered index. This index provides an innate ordering for the table it is defined on and follows whatever column order the index is defined on. In a clustered index, when rows are inserted, updated, or deleted, the underlying order of data is retained.
A clustered index is stored as a binary tree (B-tree for short). This structure starts with a root node and branches out in pairs to additional nodes until enough exists to cover the entire table’s worth of values for the index. In addition to providing an ordering of data, the nodes of the B-tree provide pointers to the next and previous rows in the data set. We can visualize a clustered index as follows:
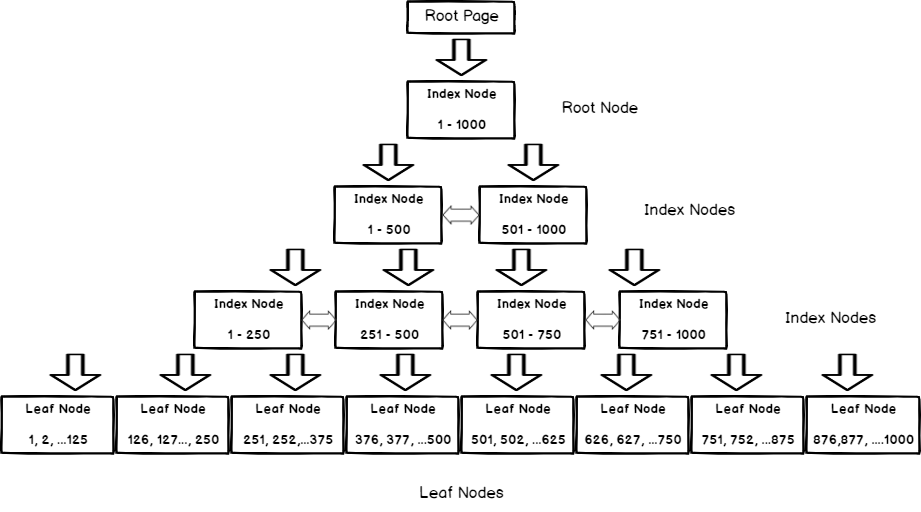
The rows of data are only stored in the leaf nodes at the lowest level of the index. These are the data pages that contain all the columns in the table, ordered by the clustered index columns. The remaining index nodes are used to organize data based on the values for the column(s) being indexed. In the diagram above, we are indexing numbers from 1-1000. With each level of index nodes, the range is broken down into smaller and smaller ranges. If we wanted to return all rows with the value of 698, we would traverse the tree as follows:
- Start at the root node
- Move to the index node 501-100
- Move to the index node 501-750
- Move to the leaf node and locate the pages that contain rows with a value of 698, if any exist
Mathematically, this is a significantly faster way to return rows as we can locate them in far fewer steps, rather than being forced to read every row in the table prior to returning results. Note that all pages in the index contain pointers to and from the previous and next nodes. This structure also guarantees a default sort based on the columns of the clustered index, which can help satisfy sorting operations in queries when they are needed.
Logical vs. Physical Storage
It is important to note that a clustered index does not describe a physical structure on disk. Pages are 8kb chunks of storage that are allocated to store index and row data. While pages reference each other via linked list pointers within the index, those pages do not have to be stored in any particular order on disk. How data is stored will be affected by the type of storage used, SQL Server configuration settings, and how often data is written.
As data is updated, inserted, and deleted, the amount of data in each page will shift, growing or shrinking. If a page fills up in the middle of an operation, then it will be split into two new pages in order to accommodate the new data. These page splits are what lead to fragmentation and are a phenomenon that can affect both heaps and clustered indexes. Due to their unordered nature, though, heaps will tend to take on fragmentation faster in most common use cases.
Notes on Temporary and In-Memory Objects
All demos in this article will be based on permanent, physical tables. In general, these results will mirror the performance you see on temporary tables or table variables when considering solely the impact of using a heap.
Memory-optimized objects are a different implementation altogether and should not be designed in the same fashion as standard tables. In-memory objects to not require a clustered index, though they must have a non-clustered index defined against it that acts similarly to how a clustered index would behave normally. Additional hash indexes may be added as needed to account for another filtering/sorting/aggregation needs. Since data is not stored on pages, fragmentation is not the concern it is with disk-based tables.
To summarize: This article is not a discussion of memory-optimized tables and the advice and ideas here should not be applied to any in-memory objects.
Performance Comparison
The remainder of our work will be to compare tables with clustered indexes to heaps and draw some conclusions about their behavior and performance. This process will inspect INSERT, UPDATE, DELETE, and MERGE operations, using data from Adventureworks to feed these tables quickly. The end result will be a comparison of reads, writes, table size, and query performance against each table with and without indexes.
Let’s begin by creating two identical tables, except that one has a clustered index and the other does not:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
CREATE TABLE dbo.heap_test (heap_test_id INT NOT NULL IDENTITY(1,1), person_first_name VARCHAR(100) NOT NULL, person_last_name VARCHAR(100) NOT NULL, person_location_id INT NOT NULL, person_birth_date DATE NULL, last_activity_time DATETIMEOFFSET NOT NULL, created_time DATETIMEOFFSET NOT NULL); CREATE TABLE dbo.clustered_index_test (heap_test_id INT NOT NULL IDENTITY(1,1), person_first_name VARCHAR(100) NOT NULL, person_last_name VARCHAR(100) NOT NULL, person_location_id INT NOT NULL, person_birth_date DATE NULL, last_activity_time DATETIMEOFFSET NOT NULL, created_time DATETIMEOFFSET NOT NULL); CREATE CLUSTERED INDEX CI_clustered_index_test ON dbo.clustered_index_test (heap_test_id); |
INSERT Operations
Let’s insert some data into these tables from Person.Person:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
INSERT INTO dbo.heap_test (person_first_name, person_last_name, person_location_id, person_birth_date, last_activity_time, created_time) SELECT Person.FirstName, Person.LastName, 1, Person.ModifiedDate, Person.ModifiedDate, GETUTCDATE() FROM Person.Person; INSERT INTO dbo.clustered_index_test (person_first_name, person_last_name, person_location_id, person_birth_date, last_activity_time, created_time) SELECT Person.FirstName, Person.LastName, 1, Person.ModifiedDate, Person.ModifiedDate, GETUTCDATE() FROM Person.Person; |
At first glance, these statements seem identical, and reviewing the execution plans confirms their similarities:
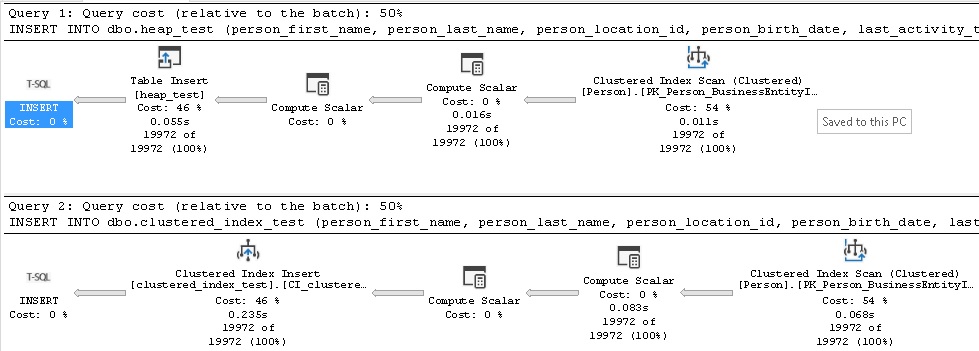
Aside from the nature of the insert, we can see that row counts and query costs are identical. Now, let’s look at the IO statistics for these operations:

On our first insert, the heap required 20 times more reads than the clustered index. But, if we insert more rows, the reads needed to write to the heap remain about the same, while the reads on the clustered index table increase:

If we continue to insert, we’ll find reads settle around this level. Still more efficient than inserting into a heap, but not as much so as when the table was first created. In terms of query duration, the clustered index in this scenario performs about as well as the heap. If we were to add a nonclustered index to the heap, then we’d see reads go up even further
Running tests repeatedly return similar results, which helps us see that in this scenario a heap is not more efficient by any metric, and is a clear loser with regards to logical IO.
Disk Space Usage
After inserting many rows and adding a nonclustered index to the heap, let’s review disk usage:
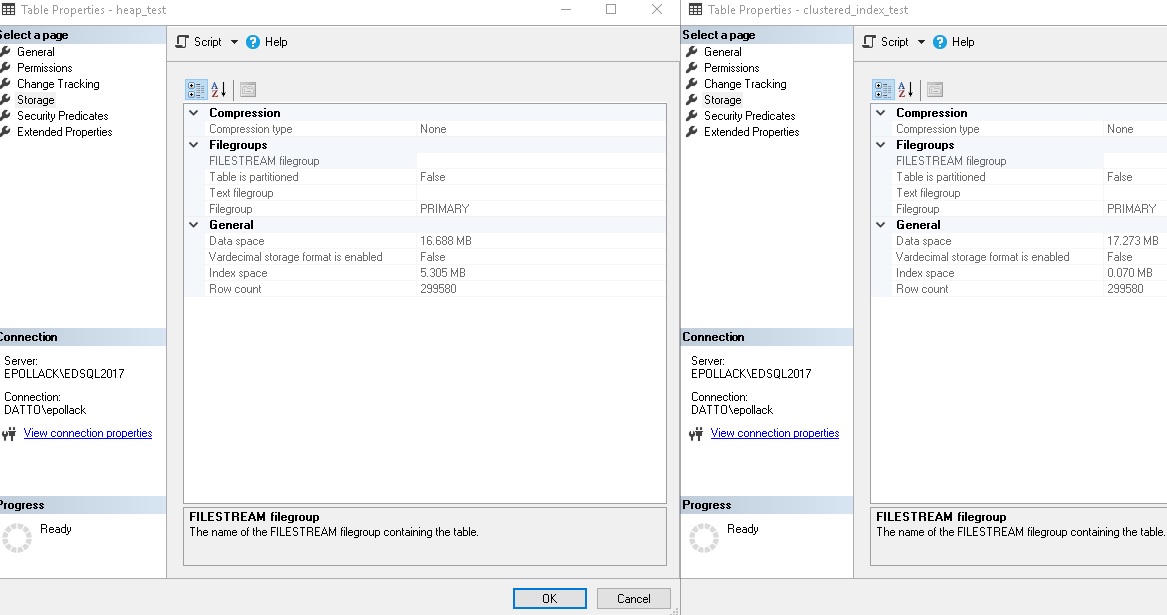
We can see that the data space is similar, with the clustered index using slightly more space than the heap. On the other hand, the clustered index is practically free for the non-heap, whereas the nonclustered index on the heap costs about a 30% penalty on space to maintain. If an index is needed for subsequent queries and that index can be the clustered index, then having a clustered index is vastly preferable than a nonclustered index on a heap, from the perspective of disk utilization.
Otherwise, the tables are identical, with about 300k rows a piece from the many times I ran the insert queries above.
UPDATE Operations
|
1 2 3 4 5 6 7 8 |
UPDATE dbo.heap_test SET person_location_id = 2 WHERE person_first_name = 'Terri' AND person_last_name = 'Duffy'; UPDATE dbo.clustered_index_test SET person_location_id = 2 WHERE person_first_name = 'Terri' AND person_last_name = 'Duffy'; |
When we execute the update statements above, we can review the execution plan and IO operations:
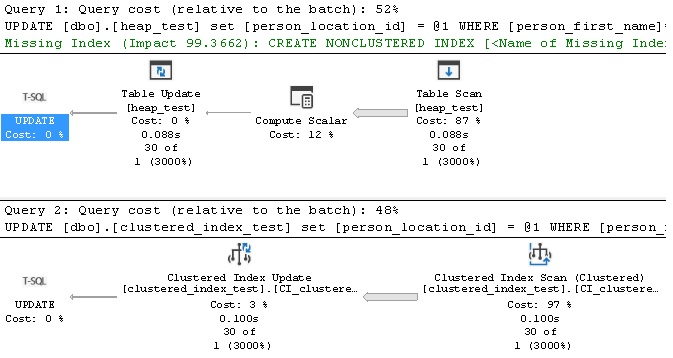

We can see that overall query performance is similar, with minor differences in the query cost (52% to 48%) and IO (2136 reads vs. 2220 reads). Let’s now test the update of a row based on searching via an indexed column:
|
1 2 3 4 5 6 |
UPDATE dbo.heap_test SET person_location_id = 2 WHERE heap_test_id = 2; UPDATE dbo.clustered_index_test SET person_location_id = 2 WHERE heap_test_id = 2; |
The resulting performance is as follows:


The execution plans are basically identical. Different operations, but a similar cost. The heap requires more effort to seek a nonclustered index to update a single value than the clustered index table. This will generally be true, regardless of how much data is in the table or how much we want to update. Searching for data via an index on a heap
SELECT Operations
Let’s start by a table scan based on a filter on an unindexed column:
|
1 2 3 4 5 6 |
SELECT * FROM dbo.heap_test WHERE person_location_id = 2; SELECT * FROM dbo.clustered_index_test WHERE person_location_id = 2; |
The results are as follows:
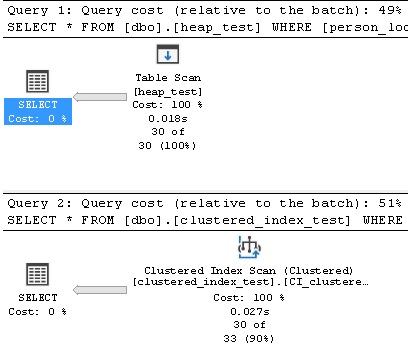

What we see is that the heap had a similar execution plan and reads to the clustered index table, though reads were slightly lower. Reading an entire table is not an uncommon use case, but will be an undesired test for most large data sets. A more common scenario that we would care about would be seeking based on an indexed value, such as in this example:
|
1 2 3 4 5 6 |
SELECT * FROM dbo.heap_test WHERE heap_test_id = 2; SELECT * FROM dbo.clustered_index_test WHERE heap_test_id = 2; |
Here are the execution plans and IO stats for these queries:
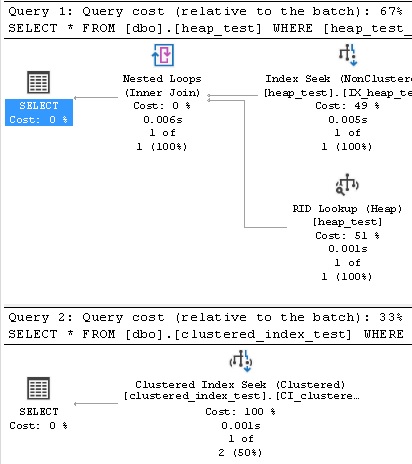

In this case, a seek on the indexed heap requires a key lookup in order to retrieve the additional columns requested by the query, making this a significantly more expensive option. While an important index on a heap could be converted into a covering index, that would incur additional storage and maintenance overhead on top of what we already have allocated. Reads are also slightly higher, and generally will be higher for most seek operations when compared to using a clustered index.
DELETE Operations
The effort to delete rows will be similar to that of a SELECT operation, but we will find that deletion against a heap requires more IO than in a clustered index. Consider the following example where we remove the rows we were just returning:
|
1 2 3 4 5 6 7 |
DELETE FROM dbo.heap_test WHERE heap_test_id = 2; DELETE FROM dbo.clustered_index_test WHERE heap_test_id = 2; |
Here are the performance results:
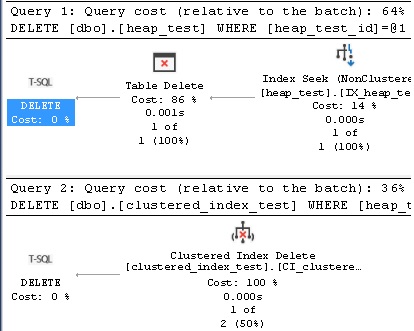

The cost to delete rows from a heap is significantly higher than from a clustered index, both in terms of query cost and reads. These costs will vary based on indexing on the table, where more indexes will typically increase the write costs, but overall the cost to update an index and delete from a table will be higher when the table is a heap, rather than having a clustered index.
Notes on Statistics and Execution Plan Quality
The query optimizer has the challenging task of having to come up with a good execution plan in a short time given statistics and other query metrics. Lacking any organized indexes, queries against heaps will occasionally incur poor execution plans. This is not common, but is most often realized when joins exist between a heap and other tables.
If you run into a query that is producing a poor plan and involves a heap, consider testing the addition of a clustered index to the table. Even if the table is being scanned, an ordered data set will perform significantly better under some circumstances than others, either by removing an additional sort operation or by increasing the metadata available to the optimizer to make a better plan decision. This is especially true when working with temporary objects, where we often neglect indexing needs. This leads us to an additional topic that is worth introducing…
Temporary Objects
We often create temporary tables or table variables in SQL Server to facilitate the collection or transformation of data via intermediary steps, prior to moving that data into a permanent data store or reporting target. Due to their transient nature, temporary objects rarely get the same level of architecture scrutiny that standard tables receive. As a result, indexes, statistics, and constraints are ignored in favor of expediency.
All of the performance considerations and experiments discussed thus far apply to temporary objects as well. If you are troubleshooting a poorly-performing query against an unindexed temporary table or table variable, experiment adding indexes to it that support your queries. As always, these indexes incur maintenance and creation costs, so they should be added in scenarios where query performance is poor enough to warrant incurring those costs.
For temporary objects that are being repeatedly written to prior to their final consumption, indexes can benefit each of those operations greatly. In general, if you are unsure whether a temporary object should be indexed, then err on the side of caution and add at least a clustered index if there will be any filters or joins against it.
For scenarios in which temporary table performance is critical, an even better solution is to use a memory-optimized table variable, which allows temporary data to be stored in memory, rather than in TempDB.
The Exceptions
In general, heaps will perform worse than tables with clustered indexes. There is a very limited set of scenarios in which a heap will offer superior performance. These scenarios are typically those in which table scans are desired and there are few joins being made against the object. For example, our UPDATE operations above showed a heap as performing marginally better, with the reason primarily being that a scan was required to locate the data needed for the update.
Our job as technology experts is to be able to identify common use cases and code for them and relegate exceptions as one-offs that we handle on an as-needed basis. As a result, creating heaps without a well-thought-out and documented purpose is likely going to create more problems than it is worth. We should use heaps when we truly know what we are doing, have tested, and have proven out that they will indeed perform better than a table with a clustered index.
This methodology should be used throughout our work in general, which will help ensure that we do not fixate on an exception, turn it into a rule, and make poor decisions based on it.
Conclusion
The only true test of performance will be our own tests that we perform using our data and schema. Only with rigorous testing should we even consider using heaps when designing database schema. Heaps will typically perform worse than clustered indexed tables and sometimes those performance problems won’t become readily apparent until a future time when data has grown or app/code complexity has increased.
This generalization applies to temporary objects as well. We should give table variables and temporary tables the same level of architectural vigor that we apply to our permanent objects. Heaps should be used sparingly and only in scenarios where we have a high level of certainty that they will not hinder performance.
This is a topic that receives a wide array of disinformation across the internet. Words such as “always” and “never” are thrown around with little thought as to their meaning. Use heaps with caution and consider how an application will grow over time. The project to migrate billions of rows from a heap into a clustered index will be a hassle for anyone tasked with it, so thinking ahead and including the clustered index up-front will save your future self the headache of managing that project.
Further Reading

In his free time, Ed enjoys video games, sci-fi & fantasy, traveling, and being as big of a geek as his friends will tolerate.
View all posts by Ed Pollack
- SQL Server Database Metrics - October 2, 2019
- Using SQL Server Database Metrics to Predict Application Problems - September 27, 2019
- SQL Injection: Detection and prevention - August 30, 2019