
One of the main DBA responsibilities is to ensure databases to perform optimally. The most efficient way to do this is through indexes. SQL indexes are one of the greatest resources when it comes to performance gain. However, the thing about indexes is that they degrade over time.
I’ve written quite a few articles about SQL indexing and most of them cover stuff like what SQL Server indexes are, how to create and alter them, how to speed up a single query, etc. But it got me into thinking, optimization is a complex subject. It’s easy to optimize a single query, but in the real world, we got thousands of different queries hitting our databases. It’s close to impossible to analyze and optimize each of those individually. There must be a better solution to maintain those SQL indexes. Right?
The answer is yes. This requires having an optimal maintenance strategy to ensure that all our indexes are performing well. This article is about maintaining indexes, and I’d assume that the reader is familiar with SQL indexing. Otherwise, it would be kind of going backward reading this because this write-up is targeting someone who has basic knowledge, has created indexes before and it has been a while, they started to degrade, what do you do to get them back in the tip-top shape.
For those who don’t have the basic knowledge, don’t leave, just read the following article before getting back to this: How to create and optimize SQL Server indexes for better performance
Without further ado, let’s start with this subject which is solely on maintaining indexes. We’re going to start with what the index maintenance consists of.
SQL index maintenance overview
The big deal about index maintenance and performance is index fragmentation. You’re most likely familiar with the term fragmentation from the operating system and hard disk. Fragmentation is what plague our indexes and of course hard disks in the OS world (not so much since the solid-state drives come out). As the data comes in and out, gets modified, etc. things have to move around. This means a lot of reads/writes activity on our disks.
Fragmentation is basically storing data non-contiguously on disk. So, the main idea here is that we want to keep it contiguous (in sequence) because if data is stored contiguously, it a lot less work for our operating system and I/O subsystem to do because it just needs to handle things sequentially. On the contrary, when the data is out of order then the OS must jump all over the place. I always like to explain things using a real-world analogy and for indexes, I always go for a regular book or phone book to explain retrieving data because it’s so easy to understand. But for defragmentation, I think a better example would be a bookshelf.

There are two types of fragmentations:
- Internal – this type of fragmentation happens when new data comes in and there is no space for it. If we look at the figure above, let’s say a librarian got a new book that should be placed within the bookshelf but there’s simply no place left for it. This means that we need another bookcase to maybe move one-third of the books over there, leave two-thirds over here, etc. The problem with this is that we now have two data pages, both not full instead of just one full data page. This will result in poor performance and caching because SQL Server caches at the page level. In this example, SQL Server would have to cache two full pages instead of one because that empty space is allocated.
- External – with this type of fragmentation, we’re dealing with the bookcases themselves. Adding up to previous analogy, let’s say the librarian must move all bottom books and move them to the new case to free up some space. The problem here is that we can’t just put the new case next door because there was already a case there full of books. So, we basically end up with a bookshelf out of order and if we try to find a book by its letters we might find out that it’s not there. We must look for it at another bookcase, go over there, etc. This results in poor performance and waste in I/O.
To sum things up, the internal fragmentation is the data itself within the pages usually caused by page splitting and the external fragmentation is new shelves placed out of order. It all comes down to just contiguousness and sequential. We want all our data to be contiguous. Contiguous data across contiguous pages is our goal also with indexes. This is what we’re aiming for when building and rebuilding them. If we do things right, as a result, we will have better caching (only load what we need into the buffer) and less I/O work for our subsystems to do.
Let’s take a quick look at how this works on a SQL Server level. The figure below shows when everything is in order. We have two sequential pages, rows are also sequential across both pages. This is the ideal image that we can see when we first create an SQL index and after we rebuild/reorganize the index. In other words, zero percentage fragmentation:

On the other side, we could have something like figure below. As it can be noticed, we have pages out of order but also rows out of order.

As the matter of fact, they’re actually in order for now but let’s say that we need to insert a new record into this table. The SQL Server would look for an empty spot and the updated pages would look like this:

This is what a fragmented table looks like. Furthermore, if we insert another record, SQL Server would have to insert another page AKA page splitting, move half rows from the previous page, insert new ones, etc. By doing this, this table can become very fragmented rather fast. Bear in mind that page splitting occurs not only on inserts but also on updates. This happens when want to update a record and it becomes too big to fit the page. The same process as within inserts happens all over again.
So, that’s both internal and external fragmentation in a nutshell. Bear in mind that big performance problems come from poor design, lack of SQL indexing, and fragmented indexes.
SQL index maintenance guidelines
Now that we have a general idea of what the problem with fragmentation is, let’s focus on how to solve it. We can fix this in two ways. There are pros and cons for both of these ways, and which one we choose will depend on the environment, situation, database size, etc. Both have the same goal and that is achieving the sequential everything:
- Rebuild – this creates a brand-new SQL index. Rebuilding is cleaner, easier and usually much quicker (this is noticeably quicker on a large database). We do lose a little bit of concurrency when doing an online rebuilt because it creates an SCH-M lock and on top of that if you run this during a busy day and it’s sucking up too many resources, you will probably have to cancel the whole operation. This means that it will actually roll-back everything like it was a transaction.
- Reorganize – this fixes physical order and compact pages. Reorganizing is better for concurrency and furthermore, if the operation is canceled like in the example before, it will simply just stop, and we will not lose the work it did right until the moment when it was canceled.
The general guideline here is, rebuild SQL indexes when/if possible and reorganize when fragmentation is low. We will see some recommendations from Microsoft later in the article. In addition to what’s been already said, here are additional guidelines and a brief explanation of what to look after:
- Identify and remove index fragmentation – this is obviously what we have been talking until now and the biggest part of the SQL index maintenance.
- Find and remove unused indexes – everything that is unused doesn’t do anything good. All they do is waste space and resources. It’s advisable to remove those often.
- Detect and create missing indexes – this is an obvious one.
- Rebuild/Reorganize indexes weekly – As it was mentioned previously, this will depend on the environment, situation, database size, etc.
- Categorize fragmentation percentage – Microsoft suggests that we rebuild indexes when we have greater than 30% fragmentation and reorganize when they are in between 5% and 30% fragmentation. Those are general guidelines to follow but bear in mind that this will cover a good percentage of databases in the real world but again this might not apply for each situation.
- Create jobs to automate maintenance – create a SQL Server Agent job that will automate SQL index maintenance. Then monitor and tweak jobs in a way that is appropriate to the particular environment because the state of data fluctuate depending on many things.
Now, creating these jobs can be a double-edged sword. We should always keep an eye on how long it takes for the job to finish maintenance plan. I’d recommend using maintenance plans only on small databases and using custom scripts everywhere else or even all the time. Scripts are flexible and overall better solution while the plans are quick and a simpler solution.
Let’s talk about what can be done to prevent SQL index fragmentation. There are a couple of tips on this subject and here’s what to aim for:
- Decrease page splitting and low page density – the main goal here is to avoid having a log of pages with a minimal amount of data on them. The best practice and general guideline is fewer pages full of data is better. However, on a table that has a huge number of inserts and we’re talking about thousands per minute, we need some free space on pages to bring down page splitting by SQL Server filling those empty pages.
- Choose sequential SQL index keys – this is one way to achieve the above advice. More about this later in the article when we jump over to SSMS and create both sequential and non-sequential table to see how the fragmentation occurs.
- Choose static SQL index keys – index keys that don’t change are exactly what eliminates fragmentation.
Enough talk, let’s see an example. Open up SSMS and the first thing we’re going to take a closer look is sequential vs. non-sequential SQL indexes. As always, I’m using the sample AdventureWorks database, but you can create a brand new if you’d like. Ensure that an appropriate database is selected and run the code from below:
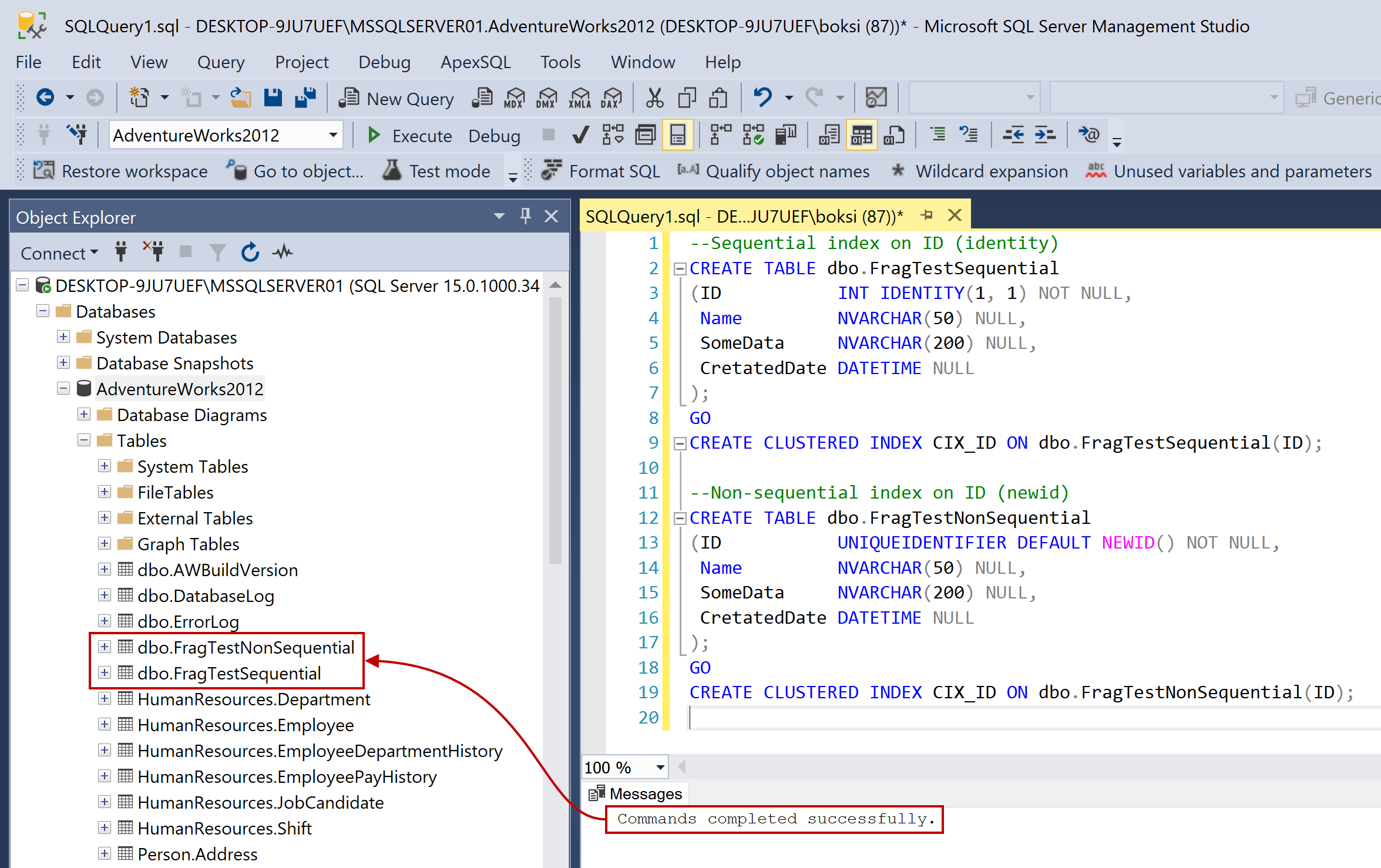
--Sequential index on ID (identity) CREATE TABLE dbo.FragTestSequential (ID INT IDENTITY(1, 1) NOT NULL, Name NVARCHAR(50) NULL, SomeData NVARCHAR(200) NULL, CretatedDate DATETIME NULL ); GO CREATE CLUSTERED INDEX CIX_ID ON dbo.FragTestSequential(ID); --Non-sequential index on ID (newid) CREATE TABLE dbo.FragTestNonSequential (ID UNIQUEIDENTIFIER DEFAULT NEWID() NOT NULL, Name NVARCHAR(50) NULL, SomeData NVARCHAR(200) NULL, CretatedDate DATETIME NULL ); GO CREATE CLUSTERED INDEX CIX_ID ON dbo.FragTestNonSequential(ID);
After this is completed successfully, if we navigate to Object Explorer, select our sample database, and expand/refresh tables, we should see newly created tables:
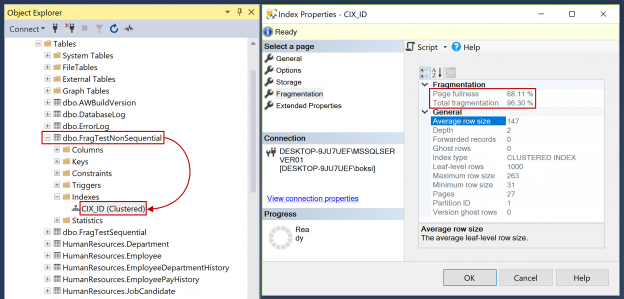
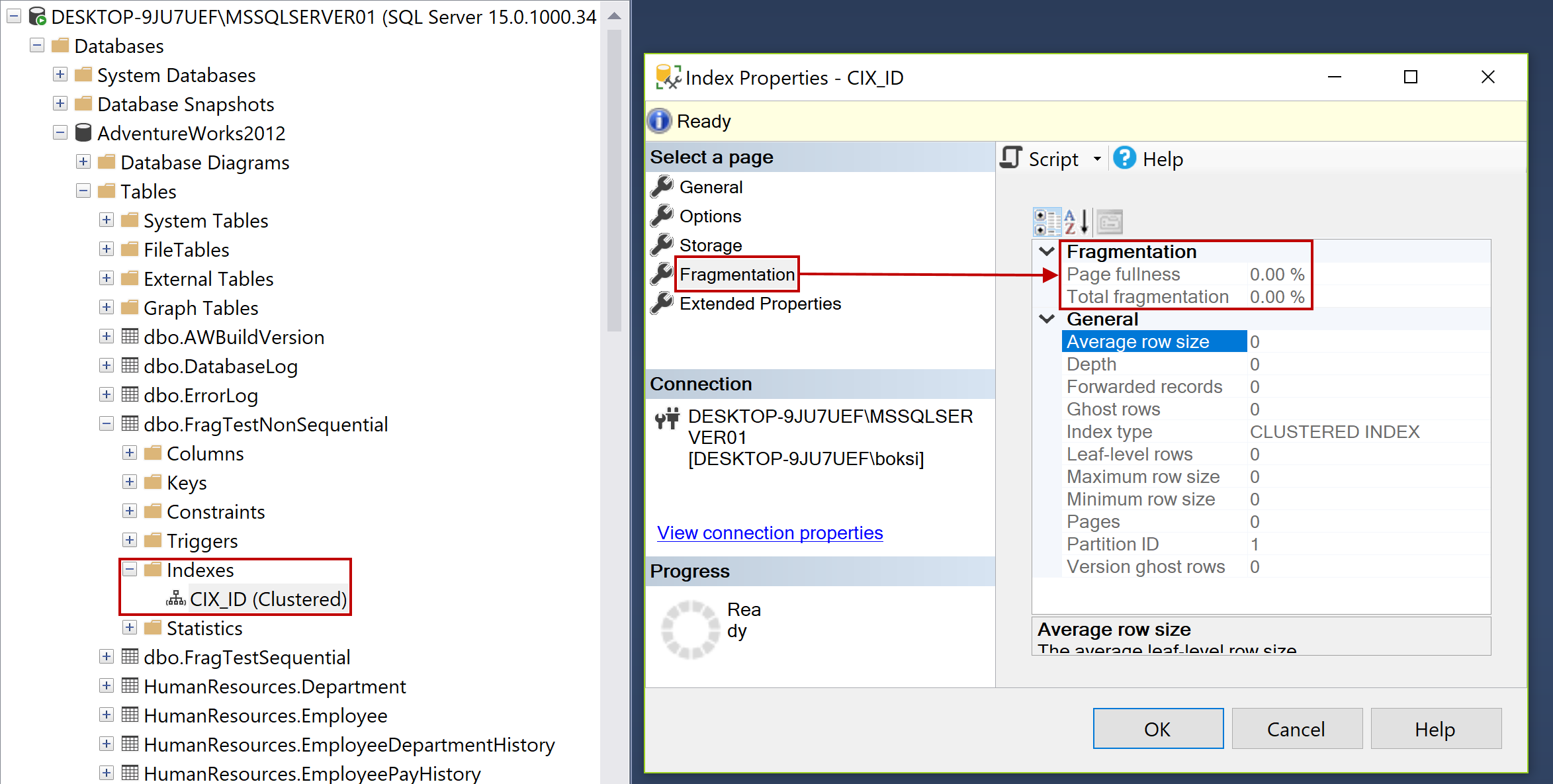
Those two tables are identical, the only difference is name, and one was created with the sequential SQL index on the ID column (1, 2, 3, etc.) and the other is created with the non-sequential index on the same column name using the uniqueidentifier with the newid that will randomly generates GUIDs. Both have a clustered index on the same column. So next, we can also check indexes by expanding the tables, then Indexes folder and we should see the CIX_ID (Clustered) index. Furthermore, if we right-click on it, hit Properties and select Fragmentation, since this is a brand new index, we should see both Page fullness (the average percent full of pages) and Total fragmentation (logical fragmentation percentage taking into account multiple files) values to be 0.00 %:
Since both tables are empty, we cannot really use them unless we have some data in them. So, let’s insert some random data in them. We can do this by executing the code from below:
--Insert (generate sequential)
INSERT INTO dbo.FragTestSequential
(dbo.FragTestSequential.Name,
dbo.FragTestSequential.SomeData,
dbo.FragTestSequential.CretatedDate
)
SELECT REPLICATE('name', ABS(CHECKSUM(NEWID()) % 10)),
REPLICATE('data', ABS(CHECKSUM(NEWID()) % 20)),
GETDATE();
GO 1000
--Insert (generate non-sequential)
INSERT INTO dbo.FragTestNonSequential
(dbo.FragTestSequential.Name,
dbo.FragTestSequential.SomeData,
dbo.FragTestSequential.CretatedDate
)
SELECT REPLICATE('name', ABS(CHECKSUM(NEWID()) % 10)),
REPLICATE('data', ABS(CHECKSUM(NEWID()) % 20)),
GETDATE();
GO 1000
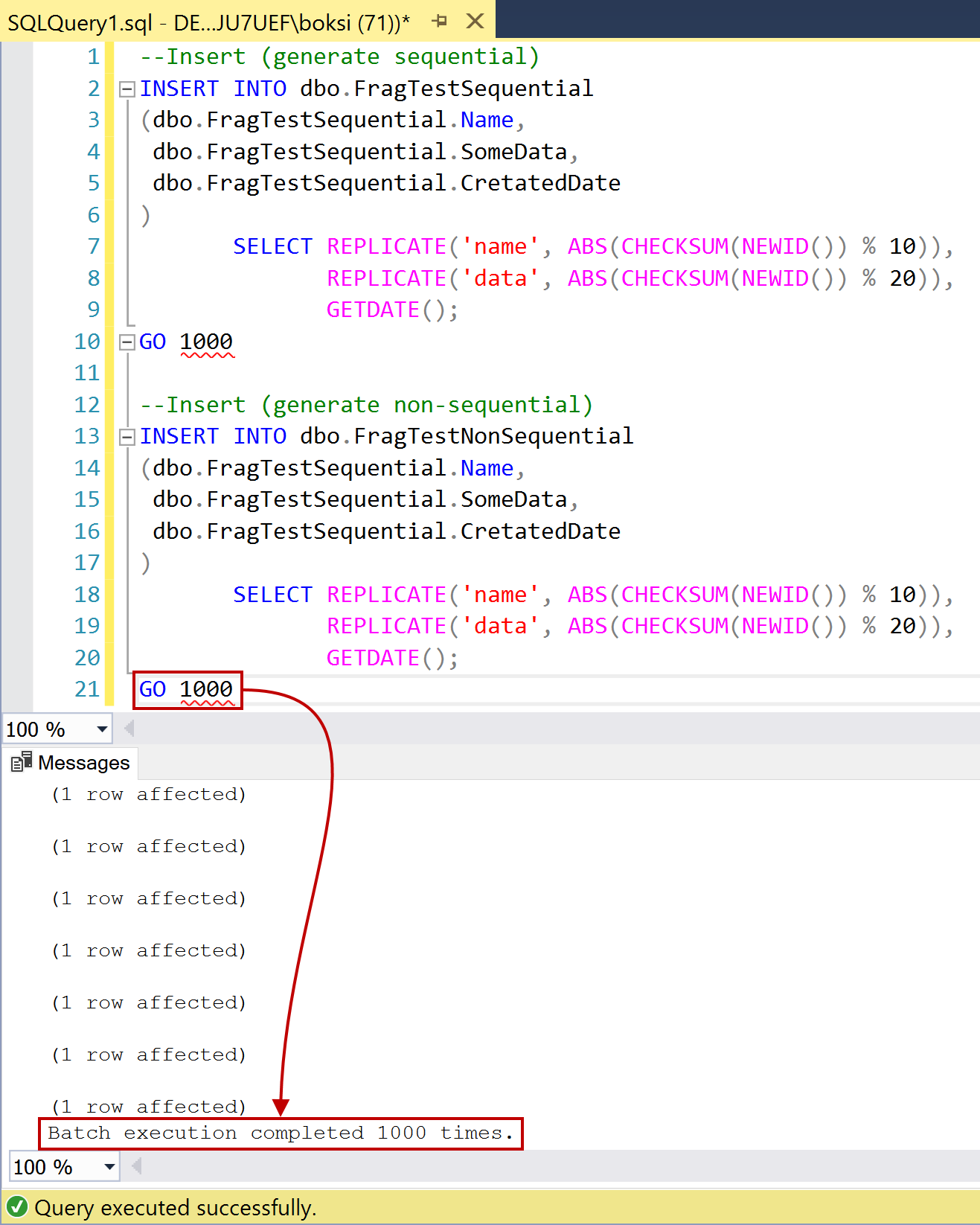
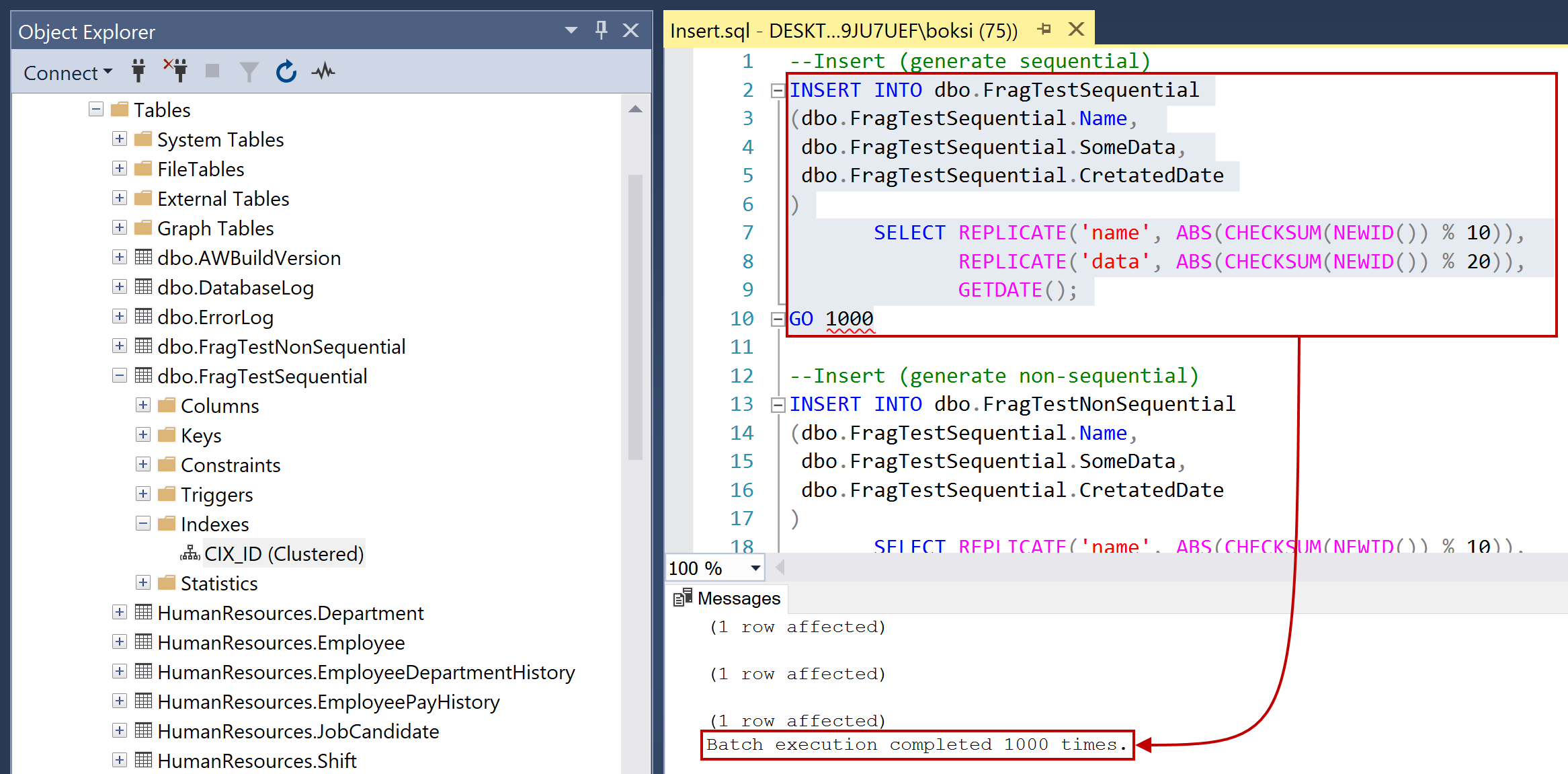
The above code inserts a thousand records into both tables. You’ll notice that there’s no loop, we just ran the statement a thousand times by specifying the value after a GO as it can be seen in the figure below:
Both batches did the exact same thing. The only difference here is that we have our ID sequential on one table and non-sequential on the other. Now, let’s first look at the sequential SQL index. Just locate it in Object Explorer, right-click on it and hit Properties. If we now check the fragmentation, notice that the fragmentation is at 5.56 %:
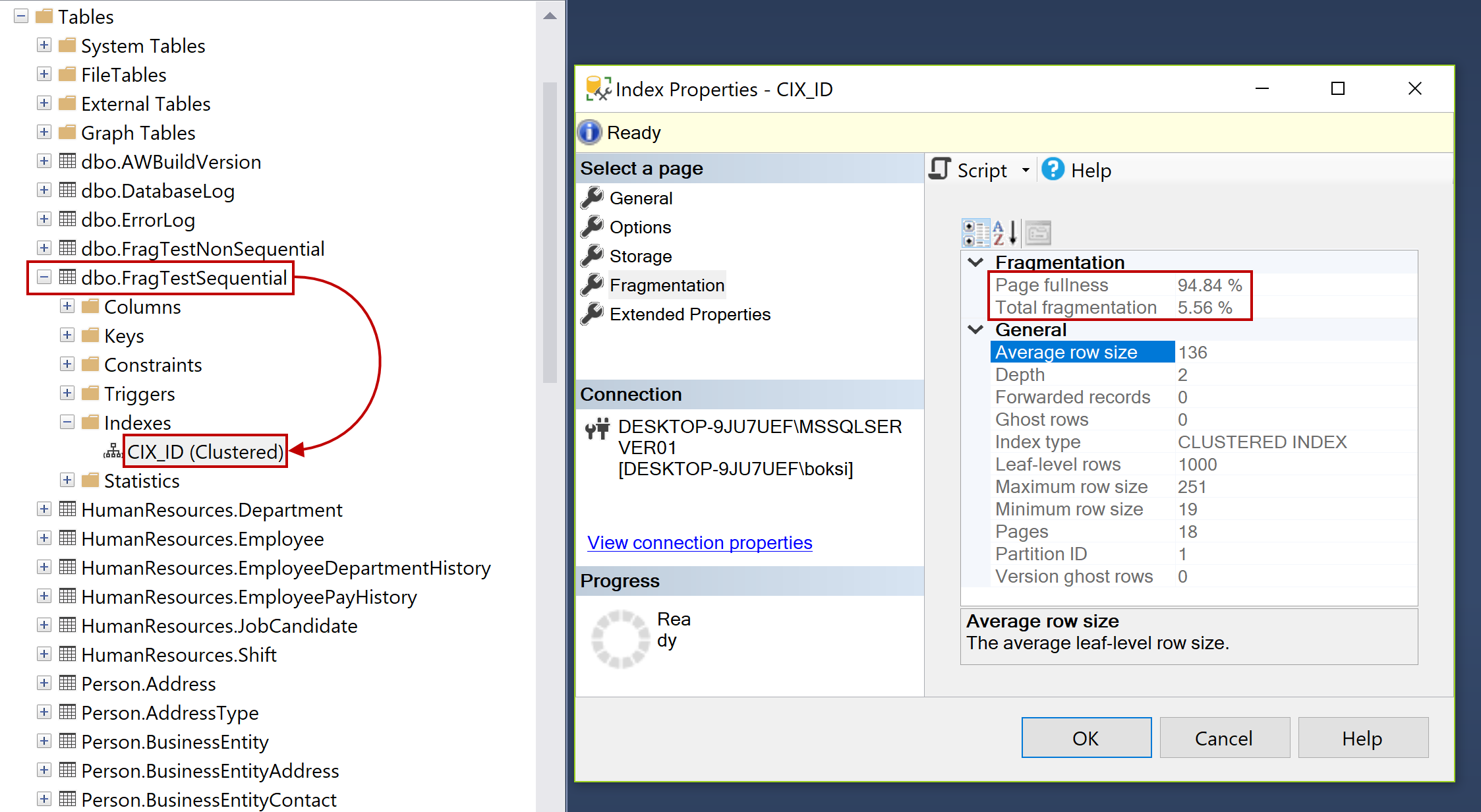
What do you think will happen if we insert another thousands record into this table? Will it get worse or better? Let’s find out by executing only the generate sequential script one more time and insert a thousands more records:
Head over to the index properties again, and notice the total fragmentation went down to 2.78 %:
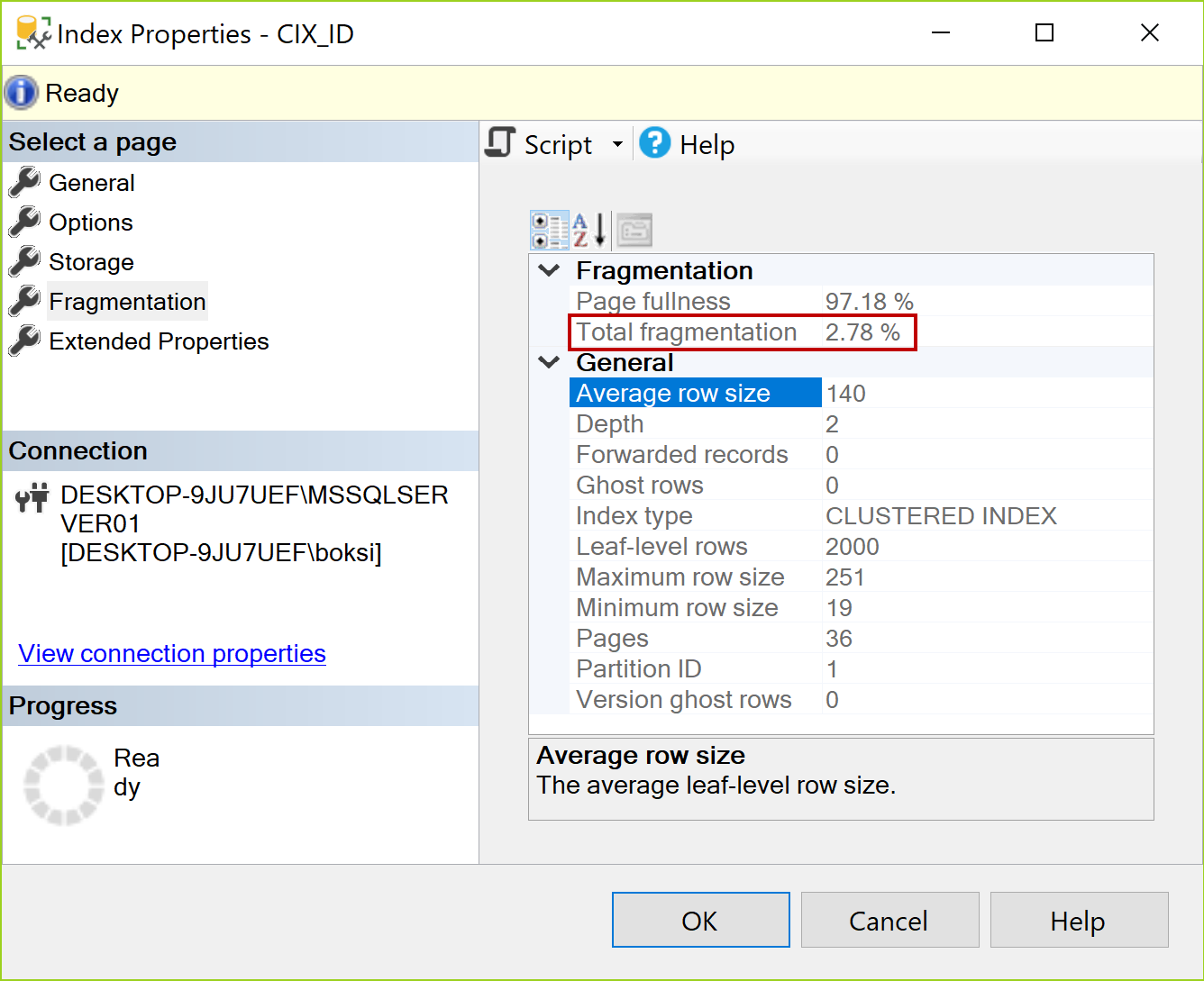
Sure thing. It gets better because with the sequential SQL Indexes it just keeps filling out the pages. When it needs another page, it will just create it, fill it in, and so on without reorganizing or moving anything.
Now, if we head over to non-sequential and check the fragmentation we can see a significantly higher value of 96.30 % fragmentation. I guarantee if we run the Insert statement one more time this number will go up even more:
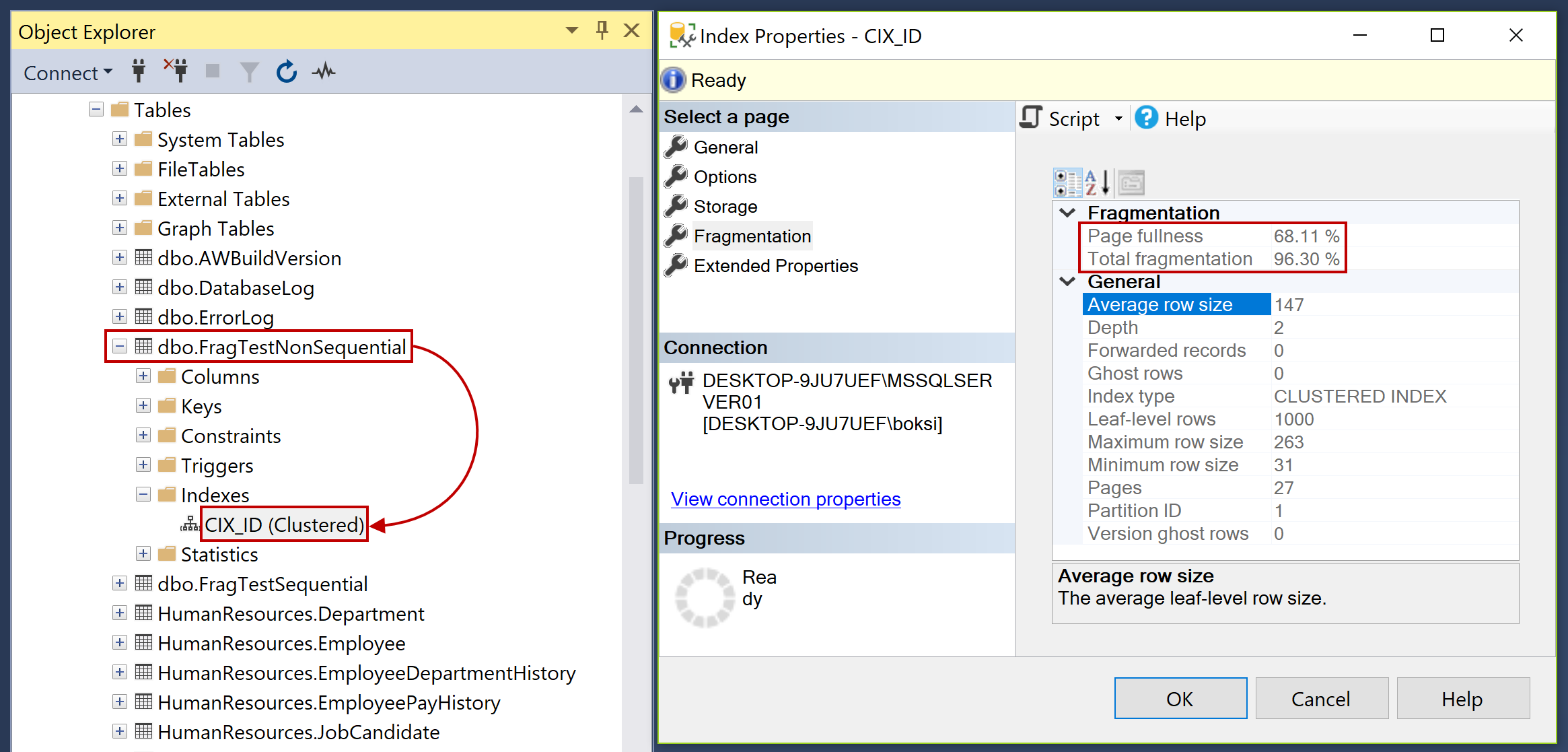
Hopefully, this example gives you an idea of how something as simple as putting an index in a field that is not sequential is essential to an SQL index.
The question here is what do we do when performance starts to drop down or we get complains from other people that there is some performance degradation. We can’t just go through each and every index in our database, right-click on our index and check the fragmentation information. As you’d imagine this could be very time consuming and not very practical. So, here’s how to identify SQL index fragmentation more efficiently.
In addition to this checking index fragmentation properties in SSMS, we can also use DMVs. The first one is sys.dm_db_index_physical_stats that is used to returns size and fragmentation information for the data and SQL indexes of the specified table or view in SQL Server. It’s basically the same information that we can get from GUI just through a DMV. Ensure that you’re connected to an appropriate database and paste the query from below:
--Fragmentation
SELECT OBJECT_NAME(ix.object_ID) AS TableName,
ix.name AS IndexName,
ixs.index_type_desc AS IndexType,
ixs.avg_fragmentation_in_percent
FROM sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, NULL) ixs
INNER JOIN sys.indexes ix ON ix.object_id = ixs.object_id
AND ixs.index_id = ixs.index_id
WHERE ixs.avg_fragmentation_in_percent > 30
ORDER BY ixs.avg_fragmentation_in_percent DESC;
If we quickly analyze the code, we can see that we are passing the database ID and we take the DMV and then join the sys.index to retrieve the index name, and a Where clause to get only the indexes that have greater than 30 percent fragmentation. The result of this query is a list of SQL indexes that we’d want to rebuild. So, let’s run the query and analyze the sample database:
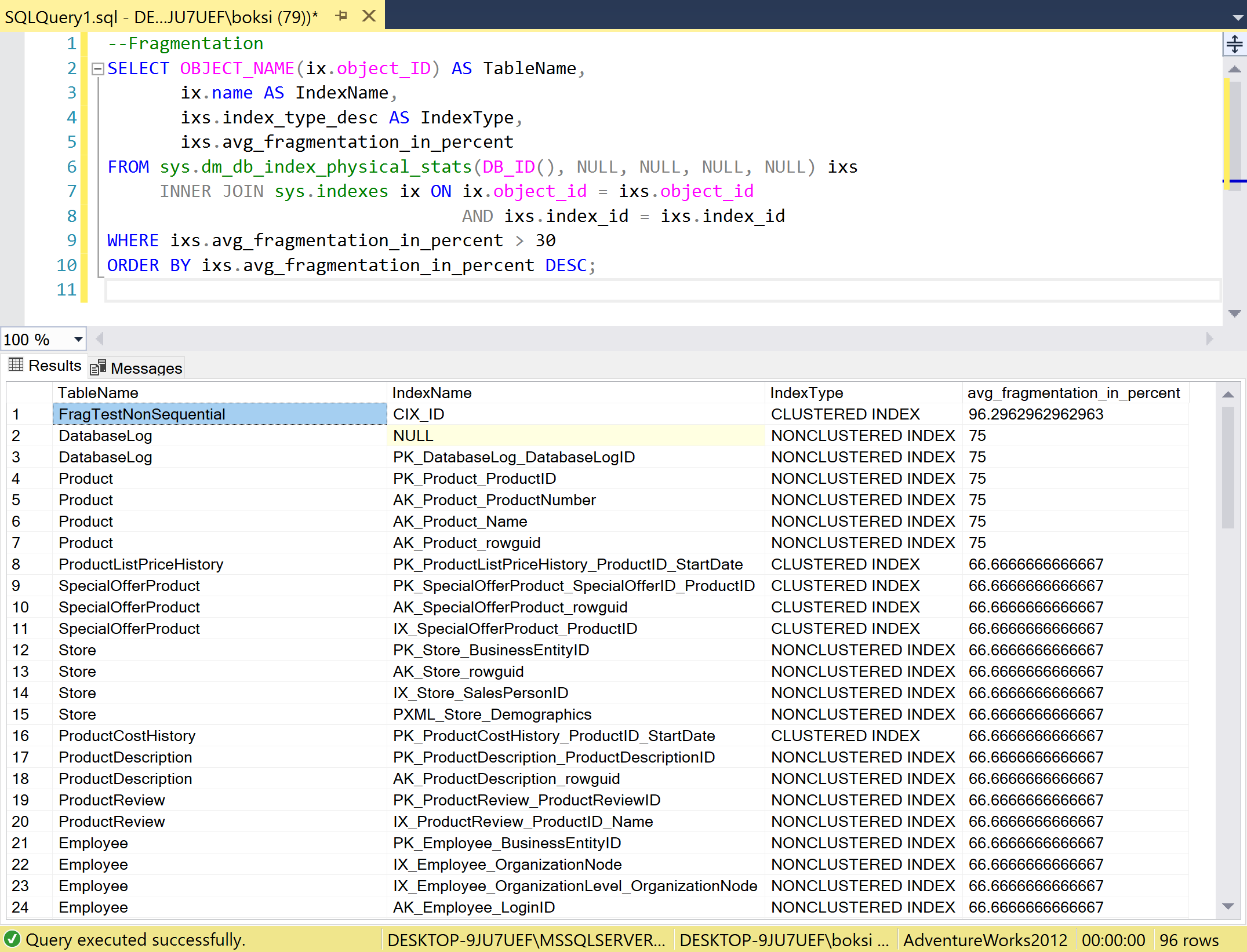
The query returned 96 indexes and on the top of the list is our test non-sequential SQL index but we also got some pretty high numbers below. Those are also havy fragmented indexes and they should be rebuild.
The second DMV is sys.dm_db_index_usage_stats that is used to return counts of different types of SQL index operations and the time each type of operation was last performed. As before, use the code from below and run it against a targeted database. I got nothing on my sample database, so I ran it against another one with actual traffic:
--Unused indexes (Index usage)
SELECT OBJECT_NAME(ix.object_ID) AS TableName,
ix.name AS IndexName,
ixs.user_seeks,
ixs.user_scans,
ixs.user_lookups,
ixs.user_updates
FROM sys.dm_db_index_usage_stats ixs
INNER JOIN sys.indexes ix ON ix.object_id = ixs.object_id
AND ixs.index_id = ixs.index_id
WHERE OBJECTPROPERTY(ixs.object_id, 'IsUserTable') = 1
AND ixs.database_id = DB_ID();
What this query will essentially do, is help us analyze unused SQL indexes same as before, just a minor change in Where clause to only grab user tables. Furthermore, this will find seeks, scans, lookups, and updates of an index:
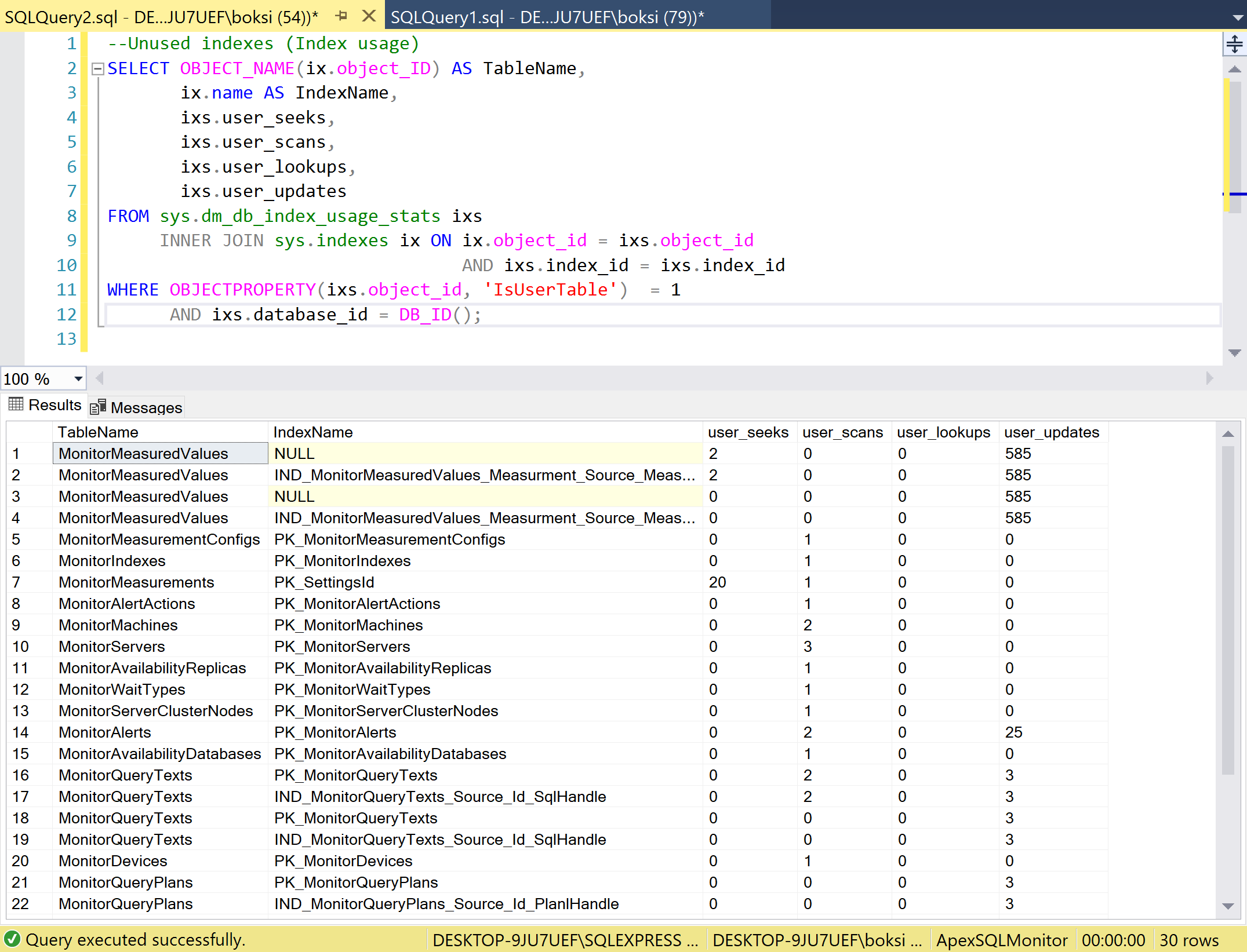
The major part here is seeks and scans. The rule of thumb is that the scans are bad, seeks are good. Whenever you see seeks, it basically means that the SQL index is being used. It also means that it makes effective use of an index. On the other side, when scans are present is also means that indexes are being used just not as effective as within seeks because it had to go through the entire index to find what it needed.
The bottom line here is that if you find SQL indexes with a low number of seeks and scans, it means that they are not being used except for cases when they just have been created. As can be seen in the figure above, we have quite a few indexes with a low number of seeks and scans, even zeros. Those are candidates to be removed or closely examined if it’s going to do anything good to improve performance rather than just take space and resources.
I want to wrap thing up with another solution that could really help you in the real world. There are useful reports that we can get from Object Explorer if we right-click on a database, had over to Reports, Standard Reports, you’ll find Index Usage Statistics and Index Physical Statistics that are both great and you can drill into details, and get some useful information about SQL index fragmentation and usage.
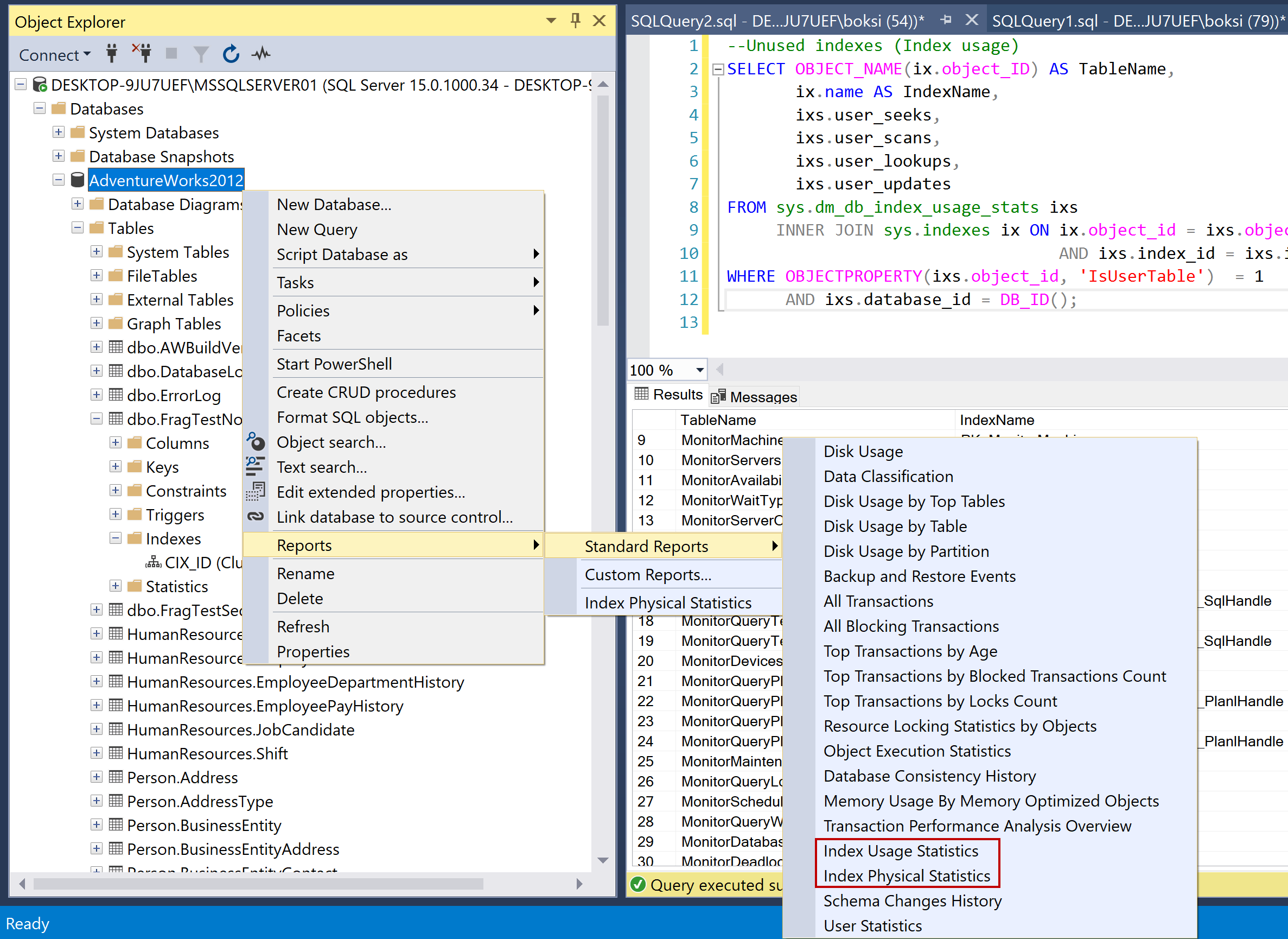
I hope this article on SQL index maintenance has been informative and I thank you for reading.

He has written extensively on both the SQL Shack and the ApexSQL Solution Center, on topics ranging from client technologies like 4K resolution and theming, error handling to index strategies, and performance monitoring.
Bojan works at ApexSQL in Nis, Serbia as an integral part of the team focusing on designing, developing, and testing the next generation of database tools including MySQL and SQL Server, and both stand-alone tools and integrations into Visual Studio, SSMS, and VSCode.
See more about Bojan at LinkedIn
View all posts by Bojan Petrovic
- Visual Studio Code for MySQL and MariaDB development - August 13, 2020
- SQL UPDATE syntax explained - July 10, 2020
- CREATE VIEW SQL: Working with indexed views in SQL Server - March 24, 2020