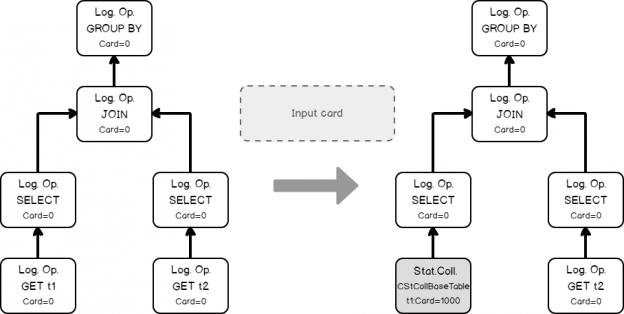
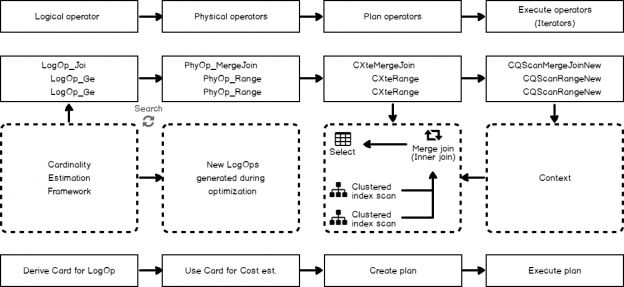
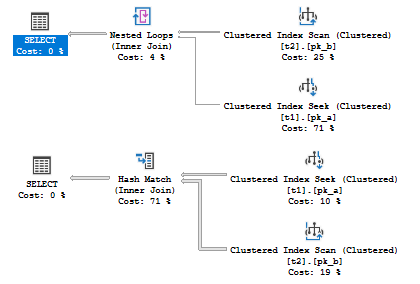
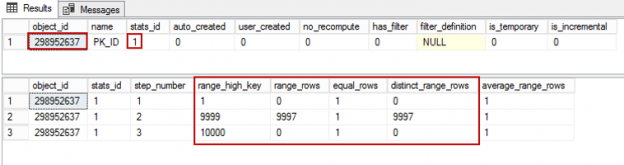
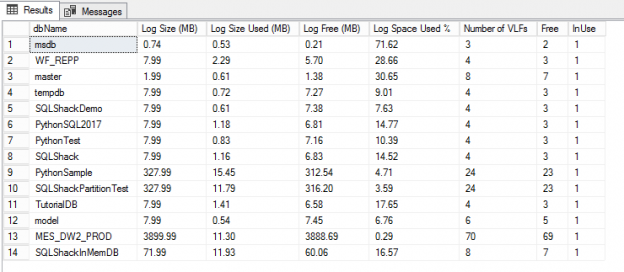
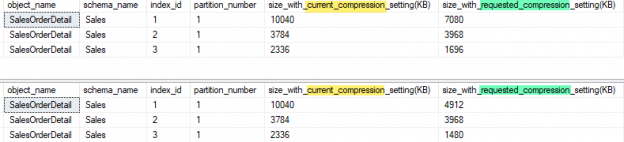
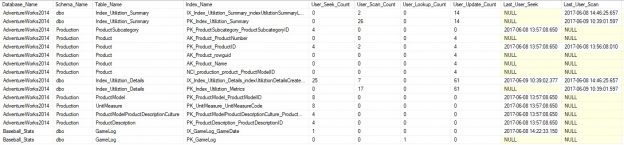
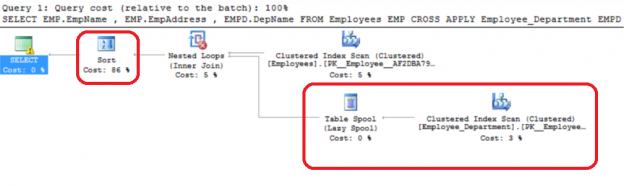
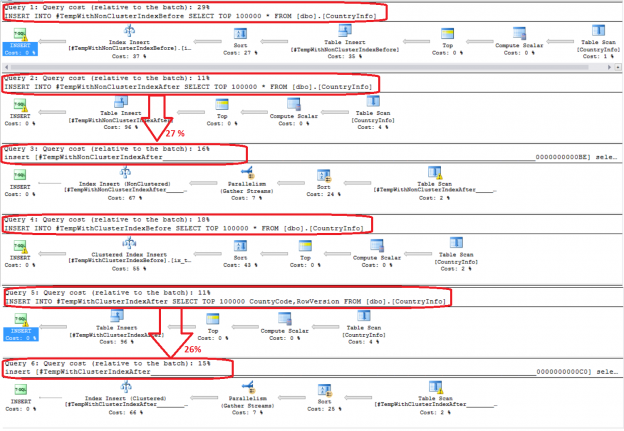
This is a small post about how you may control the cardinality estimator version and determine which version was used to build a plan.
The version of the cardinality framework is determined by the query database context, where the database has a specific compatibility level.
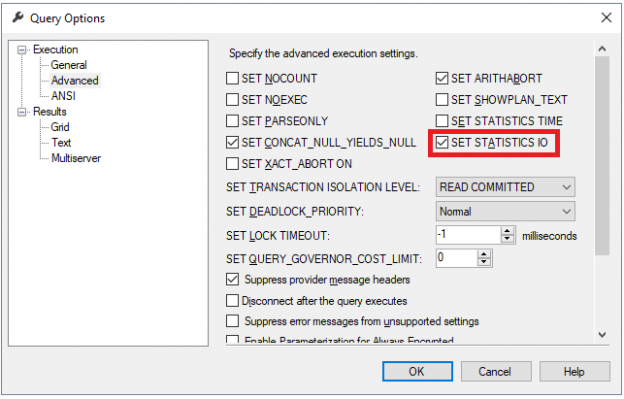
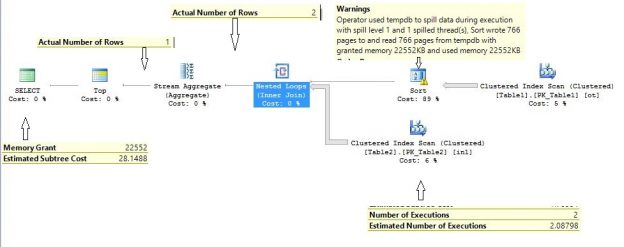
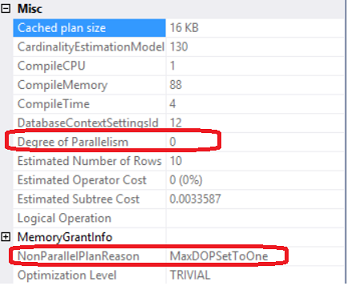
When you create a database in SQL Server 2014 it has the latest compatibility level equals 120 by default. If you issue a query in that database context, the new cardinality version will be used. You may verify this by inspecting the plan property “CardinalityEstimationModelVersion” of the root language element (the one with the green icon), SELECT, for example.
Read more »