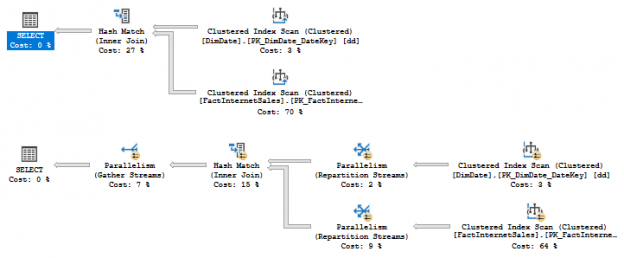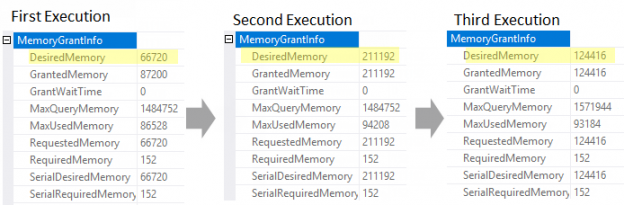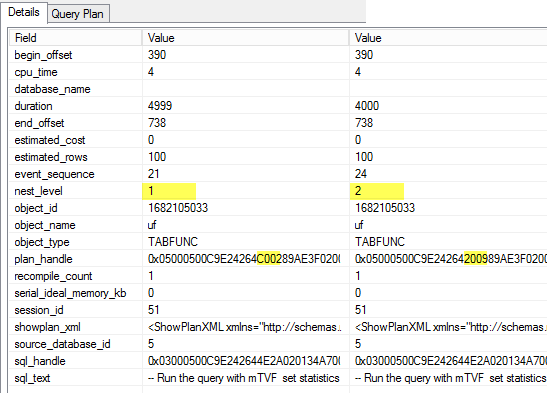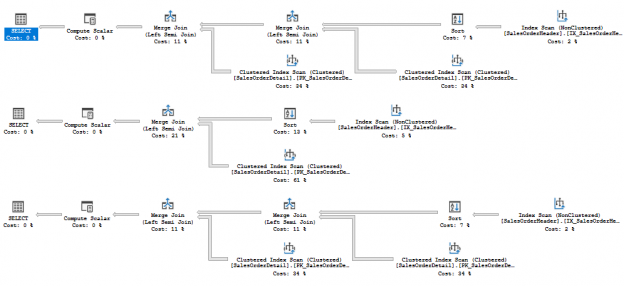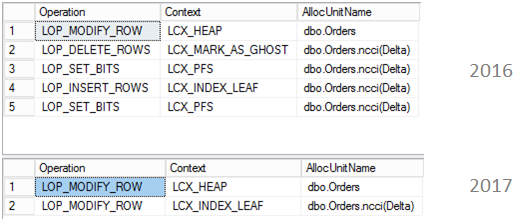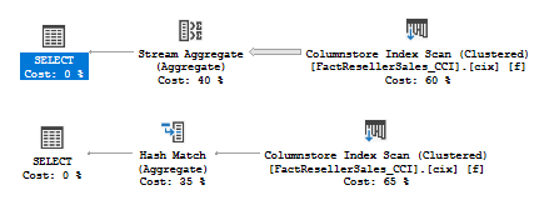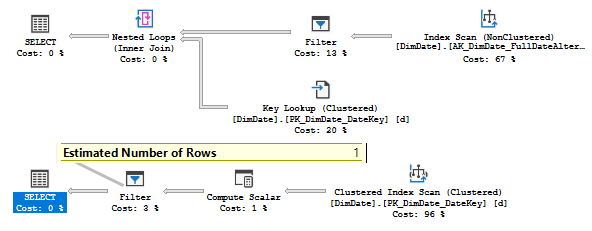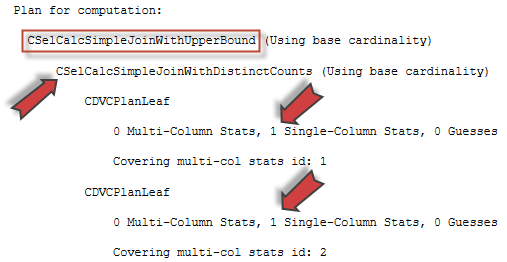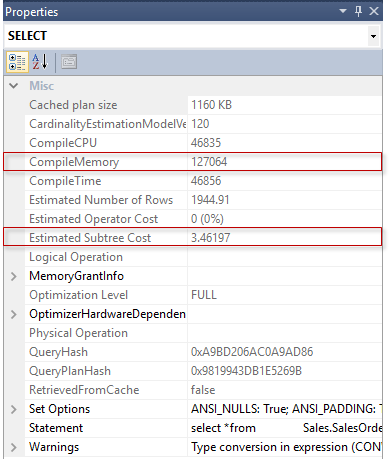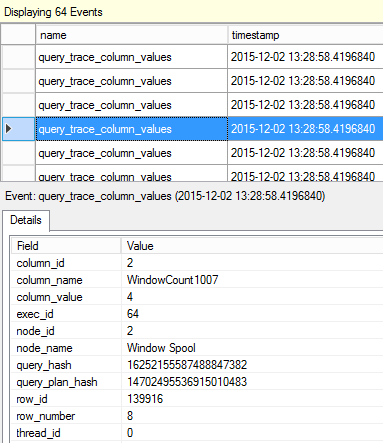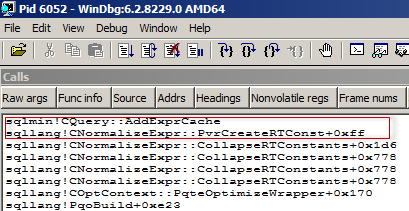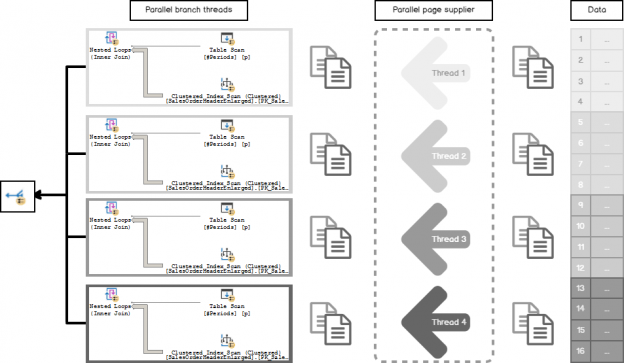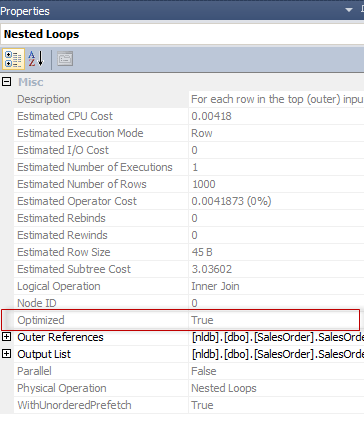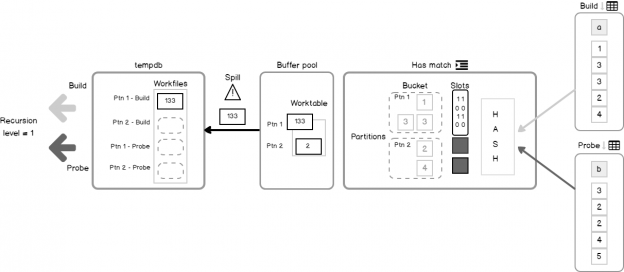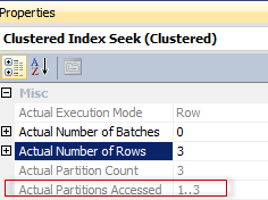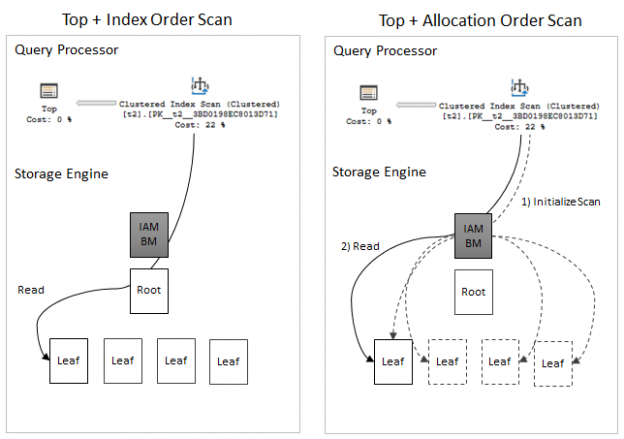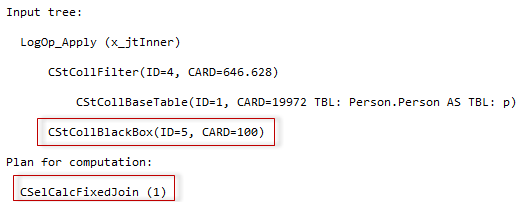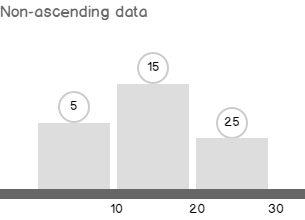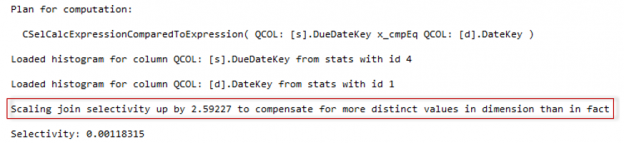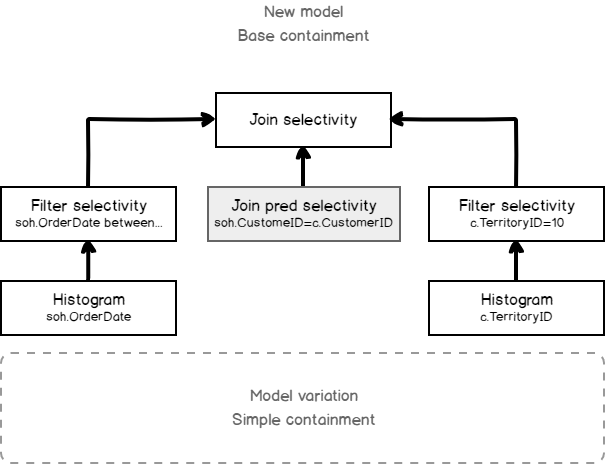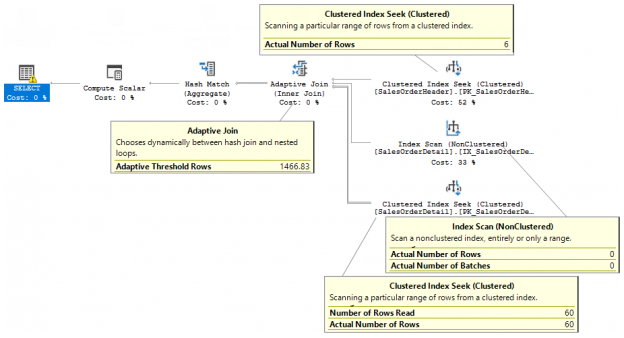
SQL Server 2017 brings a new query processing methods that are designed to mitigate cardinality estimation errors in query plans and adapt plan execution based on the execution results. This innovation is called Adaptive Query Processing and consist of the three features:
- Adaptive Memory Grant Feedback;
- Interleaved Execution;
- Adaptive Joins.