In this article, we will discuss a number of questions that you may be asked when applying to a senior SQL Server database administrator position.
Read more »

In this article, we will discuss a number of questions that you may be asked when applying to a senior SQL Server database administrator position.
Read more »
In this article, we will discuss a number of questions that you may be asked when applying to a junior SQL Server database administrator (DBA) position.
Read more »
In this article, we will discuss several scenario-related interview questions that you may be asked when applying to an Azure Administrator position.
Read more »
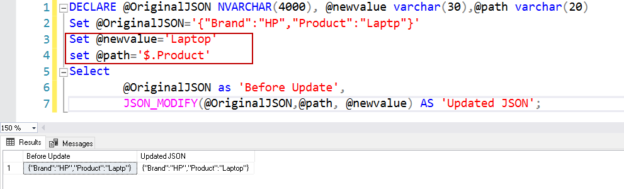
This article explores JSON_MODIFY() function to modify JSON Data in the SQL Server.
Read more »
In this article, we will learn how we can load data into Azure SQL Database from Azure Databricks using Scala and Python notebooks.
Read more »
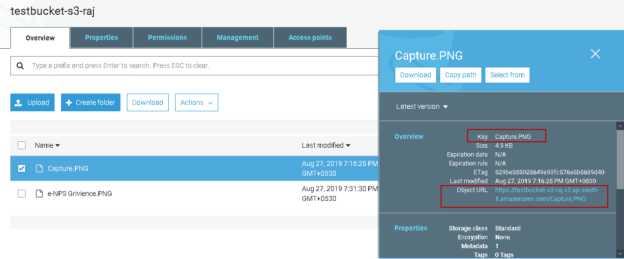
It is the second article in the Learn AWS CLI series. It gives you an overview of working with the AWS S3 bucket using CLI commands. We also look at a brief overview of the S3 bucket and its key components.
Read more »
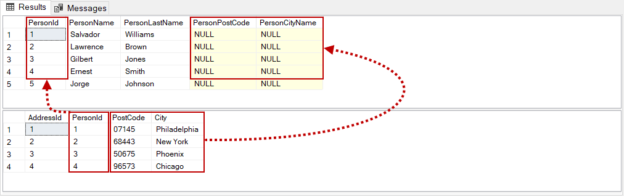
In this article, we will learn different methods that are used to update the data in a table with the data of other tables. The UPDATE from SELECT query structure is the main technique for performing these updates.
Read more »
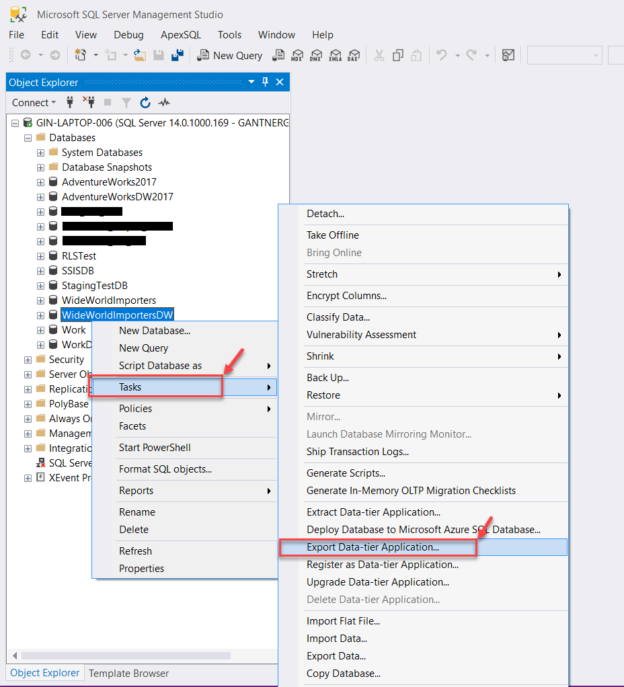
In this article, I’m going to introduce the data-tier applications in SQL Server. As the official documentation from Microsoft says – “Data-tier applications in SQL Server are a logical entity that can be used to develop and manage most of the SQL Server objects like tables, views, stored procedures, functions etc. as a self-contained package“. Essentially, what that means is it is a component of SQL Server, using which we can develop, build, test and deploy databases for SQL Server just like we can do for any other web or desktop applications.
Read more »
In this article, we will be discussing measuring Accuracy in Data Mining in SQL Server. We have discussed all the Data mining techniques that are available in SQL Server in a series of articles. The discussed techniques were Naïve Bayes, Decision Trees, Time Series, Association Rules, Clustering, Linear Regression, Neural Network, Sequence Clustering. Data mining is a predicting technique using the existing pattern. It is obvious that we won’t be able to predict 100% accurately. However, since we are using data mining outcomes for better business decisions, the result should have better accuracy. If the accuracy is very low, we tend not to use those data mining models. Therefore, it is essential to find out how accurate your data mining models are.
Read more »
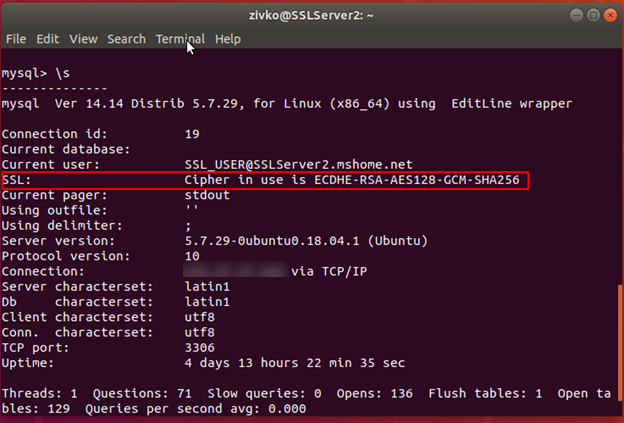
In this article, the steps to connect to remote MySQL databases using Secure Sockets Layer (SSL) will be shown. MySQL is one of the most popular relational database management systems and by default, is configured to accept only connections from the machine where MySQL is installed. To connect to the MySQL database which sits on another machine, the additional configuration must be set to accept the remote connection with secure SSL encryption.
Read more »
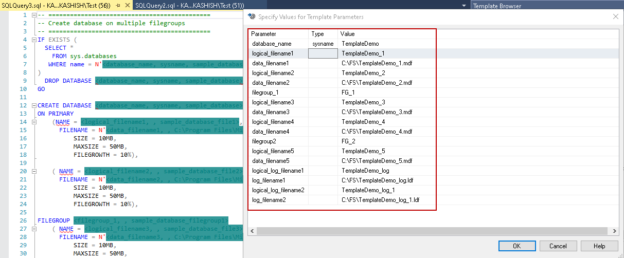
SQL Server Management Studio (SSMS) is a popular client tool to connect with SQL Server and perform various development and administrative tasks. Beginner developers or DBAs might not be familiar with T-SQL or code for specific tasks. Even for an expert DBA, query templates and shortcuts help immensely to save time and improve productivity. SSMS template explorer is an often-overlooked solution, but it is a useful feature.
Read more »
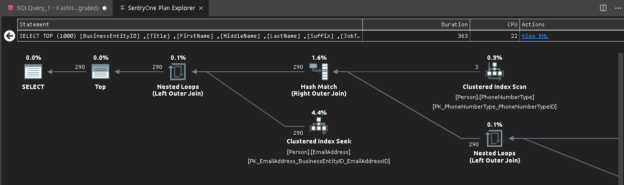
This article gives an overview of viewing execution plans in the Azure Data Studio.
Read more »
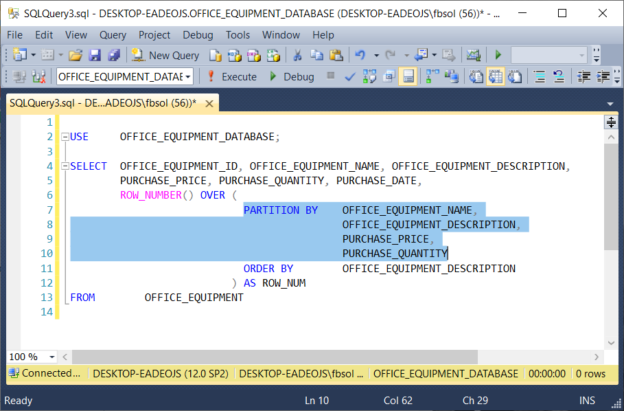
Duplicate rows in a SQL Server database table can become a problem. We will see how we can find and handle those duplicate rows using T-SQL in this article.
Read more »
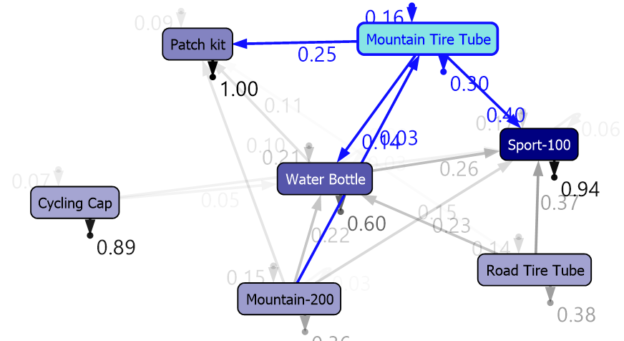
In this article, we will be discussing Microsoft Sequence Clustering in SQL Server. This is the ninth article of our SQL Server Data mining techniques series. Naïve Bayes, Decision Trees, Time Series, Association Rules, Clustering, Linear Regression, Neural Network are the other techniques that we discussed until this article.
Read more »
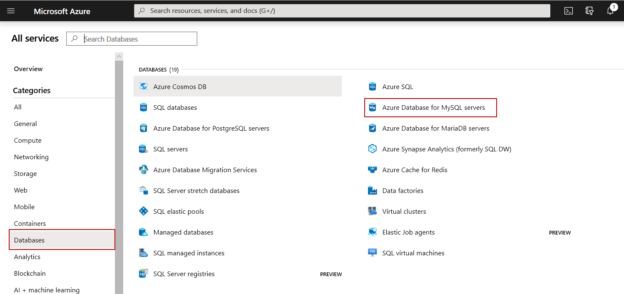
In this article, I am going to explain the step by step process to create an Azure Database for MySQL Server. Azure Database for MySQL is a fully-managed database as a service that uses MySQL community edition. It can manage the mission-critical workload with dynamic scalability. We can use it to develop various applications that leverage open-source tools and cross-platform applications. Let me explain these steps of a deployment process of MySQL Server on Azure.
Read more »
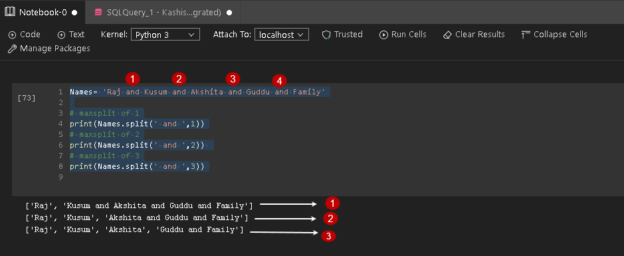
This article gives an overview of Python Script functions to split strings and string concatenation functions.
Read more »
This article is the first article in the series of Learn AWS CLI. Here we will talk about the overview, installation, and configuration of CLI tools in Windows.
Read more »
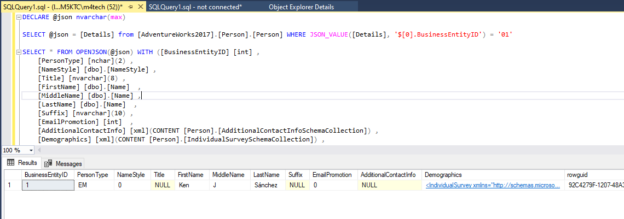
In this article, we will explain what JSON is, what are the SQL Server JSON functions introduced in 2016, how to index JSON values, and how to import JSON data into SQL tables.
Read more »
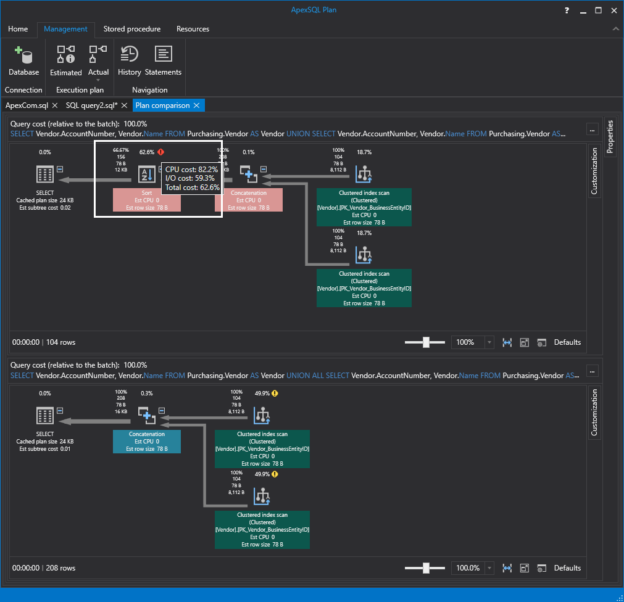
This article will cover some essential techniques for SQL query tuning. Query tuning is a very wide topic to talk about, but some essential techniques never change in order to tune queries in SQL Server. Particularly, it is a difficult issue for those who are a newbie to SQL query tuning or who are thinking about starting it. So, this article will be a good starting point for them. Also, other readers can refresh their knowledge with this article. In the next parts of this article, we will mention these techniques that help to tune queries.
Read more »
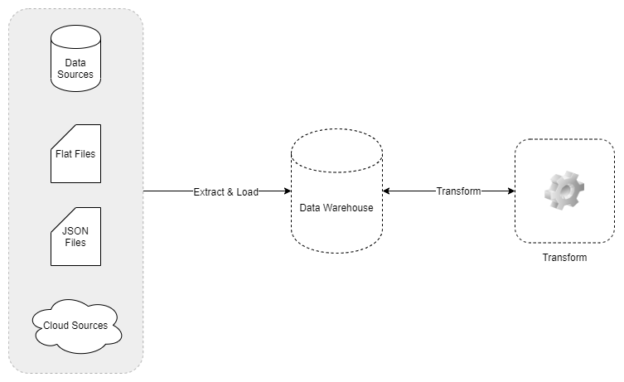
This article explains what the basic features and differences between ETL and ELT are. I’m also going to explain in detail what an ELT pipeline is and a relevant architecture for the same in Azure. So far, we have come a long way dealing with ETL tools which basically are Extract, Transformation and Load technique used in populating a data warehouse. ELT, on the other hand, is another way to load data into a warehouse that implements the process of Extract, Load and Transform.
Read more »
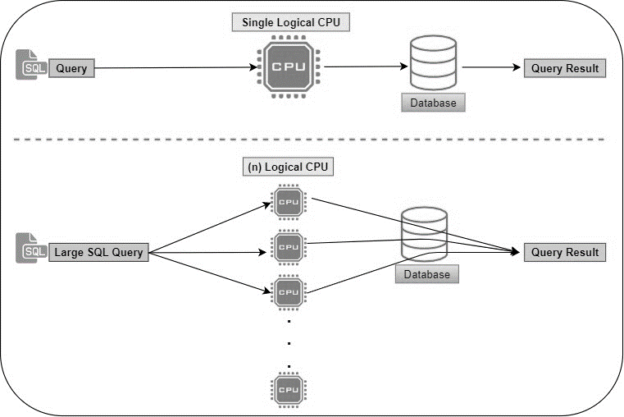
In this article, we will discuss how the Max Degree of Parallelism works in SQL Server and how does it improve the query performance. SQL Server Degree of Parallelism is the processor conveyance parameter for a SQL Server operation, and it chooses the maximum number of execution distribution with the parallel use of different logical CPUs for the SQL Server request. Microsoft SQL Server allows setting this Degree of Parallelism parameter value at the SQL Server instance level or Query level. If you do not specify the SQL Server Degree of Parallelism value at the SQL Server instance, then each request or operation has to rely on SQL Server default value and random CPU allocations.
Read more »

So far, we haven’t talked about SQL Server date and time functions. Today we’ll change that. We’ll take a close look at the ones most frequently used and mention all other date and time functions as well. This will be also the first step to create reports, including date and time functions. We’ll do that in upcoming articles in this series.
Read more »
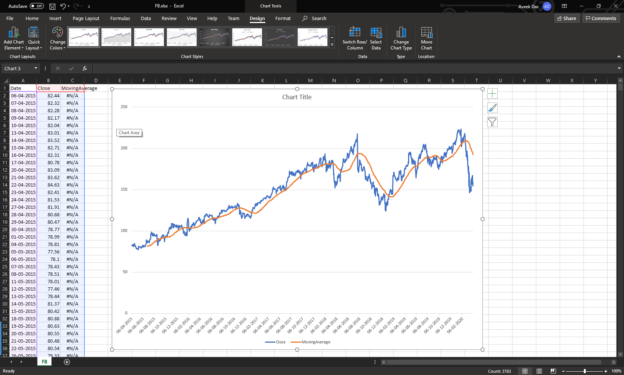
In this article, I’m going to talk in detail about the moving average in SQL and how to find out the same in Power BI and Excel. This might be a new topic for many newbies who have started out in this field, but I’m sure this will help anyone who is trying to work on smoothing averages in SQL or in Power BI.
Read more »

In the previous two articles, we’ve practiced SQL queries and went through a few more examples. Today we’ll use SQL queries and create a report from scratch. We’ll start from the simplest possible query and finish with the query returning the actual report data.
Read more »
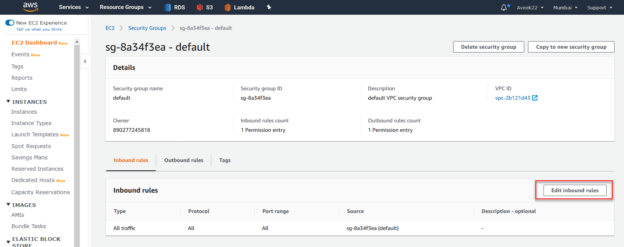
In this article, I’m going to explain how to configure an RDS Environment in Amazon Web Services (AWS) for SQL Server. Amazon RDS, also known as the Amazon Relational Database Service, is a Database-as-a-Service offered by Amazon. This enables us to create an instance of a relational database in RDS including many databases like SQL Server, MySQL, PostgreSQL etc. The entire hosting is managed by AWS, so there is no worry to maintain any on-premises data center or infrastructure from the customer’s end.
Read more »© Quest Software Inc. ALL RIGHTS RESERVED. | GDPR | Terms of Use | Privacy