
Association Rule Mining in SQL Server is the next article in our data mining article series in which we have discussed Naïve Bayes, Decision Trees, and Time Series until now. Association Rule Mining, also known as Market Basket Analysis, mainly because Association Mining is used to find out the items which are bought together by the customers during their shopping.
The most popular Association Rule Mining example that you will find is the story at the supermarket chain in the US. It is said that they have found out that the customers that are buying beer will buy nappies for their kids. After this finding, management has taken a decision to move the beer palette close to the nappy palette. By doing so, of course, they were able to increase sales. In addition to the money, they were able to make their customers happy. Also, customers buying time was reduced and so the congestion in the supermarket. This means that the Association Rule Mining is helpful to users in many ways.
Though Association Mining is always discussed with shopping, there are other possible areas of applications such as troubleshooting, medicine, and marketing, etc. In troubleshooting, by using Association Rule, you can diagnose what issues occur together. Also, in the domain of medicine, Association Rule will help to find out what types of the disease occur together. This means there are a lot of ways of utilizing the Association Rule in business.
How to Use Association Rule Mining in SQL Server
This time, there is a small change to the SSAS data mining project to what we have done before. This is due to the fact that we will be using a couple of views in the AdventureWorksDW database, whereas we were using only one view in all previous examples. Those two views are vAssocSeqOrders and vAssocSeqLineItems. vAssocSeqOrders view has orders while the vAssocSeqLineItems view has order lines for the orders. Following screenshot shows sample data set in those two views:
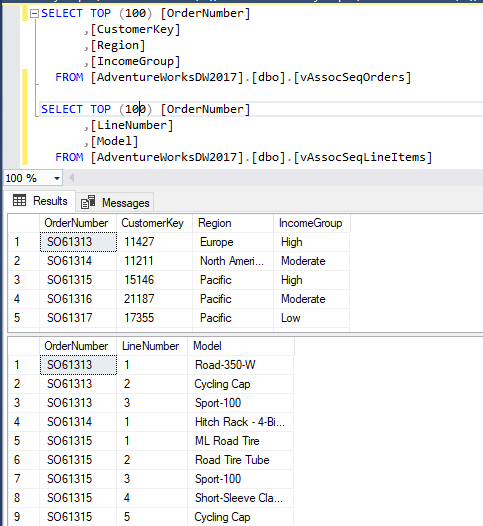
If you carefully look at the above screenshot, for the order number SO61313, there are three order lines in the second view.
Let us open SQL Server Data Tools (SSDT) and create an SSAS project to set up the Association Rule Mining. Then create a data source pointing to the AdventureworksDW database as we did in the previous articles.
For the data source view, let us add the specified views as shown in the below screenshot:
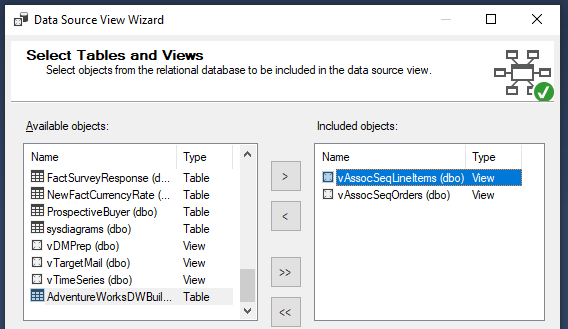
When these two views are added to the data source views, the relation between these two views is not added by default. This means you need to join those two views manually.
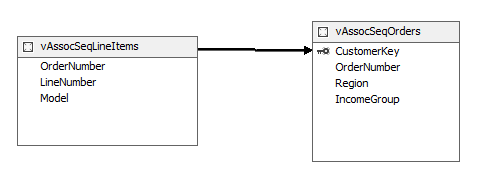
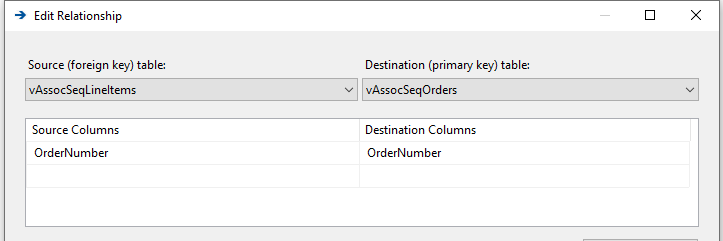
Verify the relationship by double-clicking the arrow sign. Source and Destination tables should be as shown along with the OrderNumber column. If it is in reverse, click the Reverse button to change it.
Next, we need to choose the case and the nested table. Up to now, we had to choose only the case table in our previous examples. However, in the Associating Rule Mining, since there are two views, we need to choose the case and the nested table, as shown in the below screenshot.
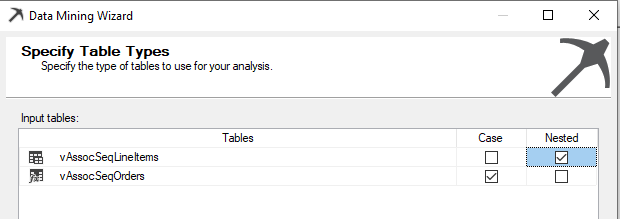
vAssocSeqOrders view was chosen as the Case table where the vAssocSeqLineItems is chosen as the Nested table.
The objective of the Association Rule Mining is to find out what models are selling together. Therefore, the product model will be the input as well as the predict attribute. OrderNumber and the Model are the keys. You can see those selections as shown in the below screenshot:
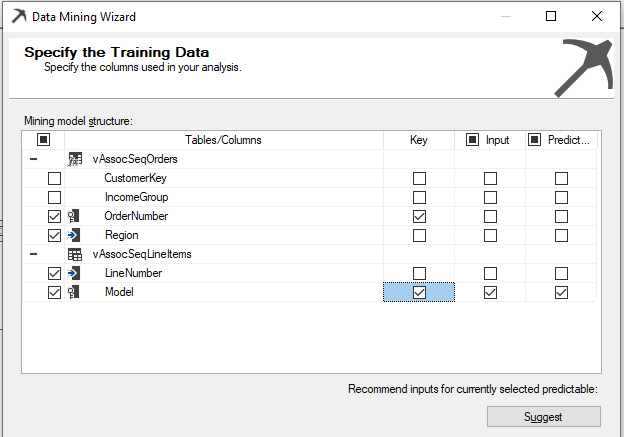
After the Association Rule configuration is completed, then the model can be processed. Then users can review the prediction model and perform the predictions.
Mining Model Viewer
Let us view the data patterns from the Association Rule model, which was built before.
In the Mining Model viewer, there are three tabs to view the data patterns. In the Rules tab, it will show the rules that can be derived fro the Association Rule Mining model in the sample set.
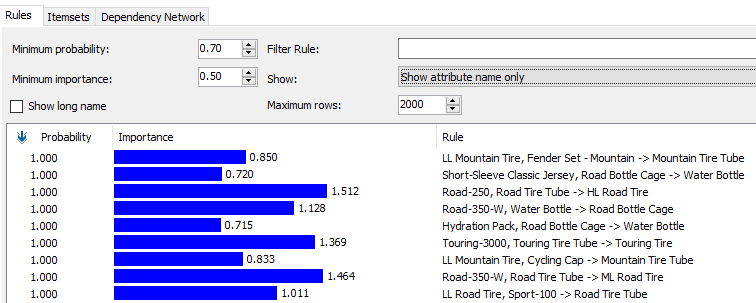
The main part of the Rule tab is the rule grid, which displays the all qualified Association Rule Minings along with their probabilities and their importance. The importance score will tell how useful the rule is. If the importance score is high, most likely greater than 1, the rule is of higher quality.
In the above screenshot, the customer who buys LL Mountain Tire and Fender Set-Mountain will buy Mountain Tire Tube. Probability 1 means that it will be true always. The importance of this rule is 0.850.
The Minimum importance level can be set for a model before processing so that the processing performance can be improved.
The next tab is ItemSets table, which will display the frequent itemsets discovered from the Association Rule algorithm.
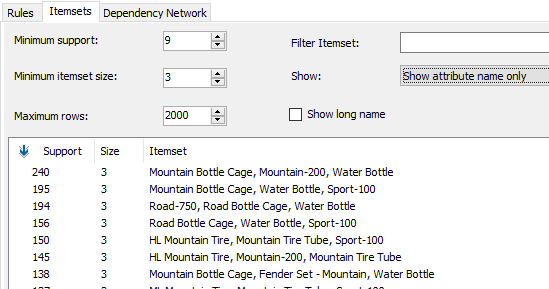
Users can set the minimum support at this view as well as a model parameter so that the performance of the model process will be improved. Users can also select the minimum item set. In this example, minimum itemset size is set at 3, which means that three combinations of models are selected. Also, if needed, it is possible to put rules which consist of a specific item model by setting up filtering in Filter Itemset.
In the above data set, Mountain Bottle Cage, Mountain-200, and Water Bottle are in 240 orders so that you can identify the frequency of the itemset combinations.
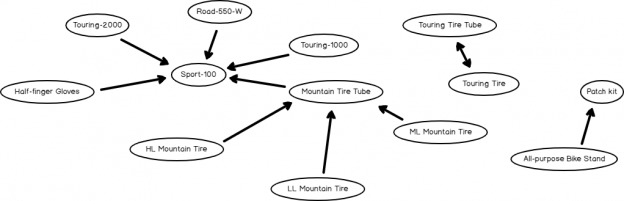
The third tab in the model viewer, Dependency Network, graphically illustrates the relationship between the itemsets, as shown in the below screenshot.
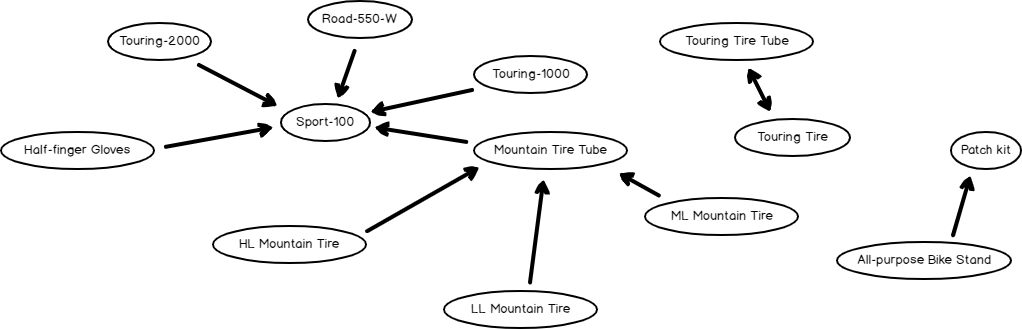
If you analyze the above screenshot, you will see that Sport-100 will be bought by the customers who bought the Touring-1000, Touring-2000, Road-550-W and Half-Finger Gloves separately. There is another great finding that customers who buy Touring Tire will buy Touring Tire Tube and importantly, vice versa is also true. This is indicated by the arrow that points both ways.
If you click any node, those nodes will be highlighted with different colors, as shown in the below screenshot.
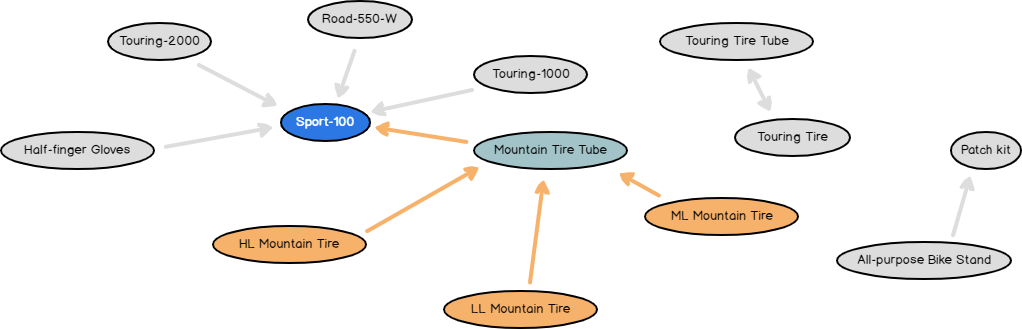
This will indicate different relations of the selected node with the other nodes in the relationship diagrams.
Model Parameters
Model parameters can be set so that the Association Rule Mining can be configured to improve performance and accuracy.
This can be set from the following dialog box.
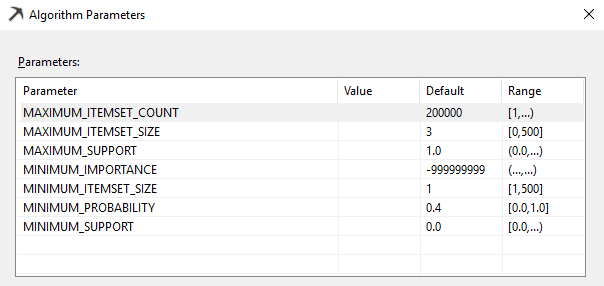
MAXIMUM_ITEMSET_COUNT
The default value for this parameter is 200,000. This parameter defines how many predications will be generated.
MAXIMUM_ITEMSET_SIZE
This parameter defines the maximum number of itemsets. The default value for this parameter is 3. Reducing this number will reduce the model processing time.
MAXIMUM_SUPPORT
This parameter defines the maximum support threshold of a frequent itemset. This parameter can be used to filter out those items that are too frequent, which is obvious. This parameter is available only in Enterprise edition.
MINIMUM_IMPORATANCE
This threshold will filter out rules which are less than the defined parameter value. This parameter is available only in Enterprise edition.
MINIMUM_ITEMSET_SIZE
This parameter defines the minimum number of itemsets. The default value for this parameter is 1. Reducing this number will not reduce the model processing time. This parameter is available only in Enterprise edition.
MINUMUM_PROBABILITY
This parameter specifies the minimum probability that a rule is true. For example, setting this value to 0.5 specifies that no rule with less than 50% probability is generated.
MINIMUM_SUPPORT
This parameter specifies the minimum number of cases that must contain the itemset before generating a rule. Setting this value to less than 1 specifies the minimum number of cases as a percentage of the total cases. Setting this value to a whole number greater than 1 specifies the minimum number of cases as the absolute number of cases that must contain the itemset. The algorithm may increase the value of this parameter if memory is limited.
Prediction
Predication is an important part of any data mining algorithm. Predication can be done from the following Mining Model Prediction tab, as shown below:
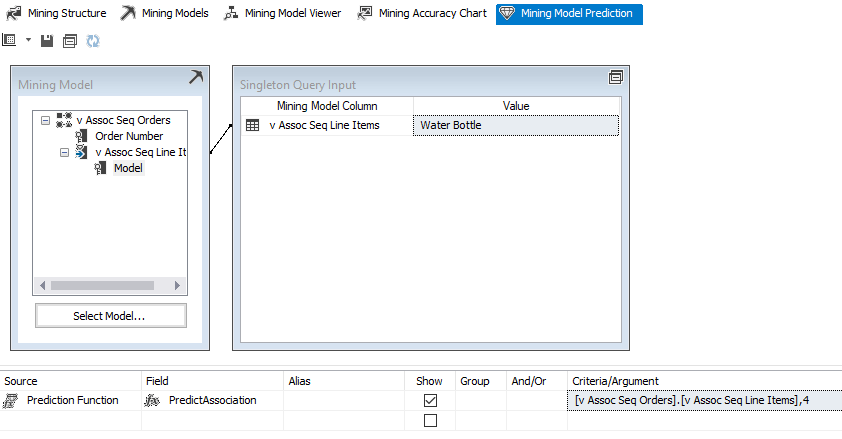
The above screenshot shows how to predict what are the items which will be bought by the customers who had bought Water Bottle.
Conclusion
In conclusion, the Association Rule Mining method is an excellent way of finding associated items and optimizing article procurement and allocation in case of shopping applications.
Table of contents

View all posts by Dinesh Asanka
- Testing Type 2 Slowly Changing Dimensions in a Data Warehouse - May 30, 2022
- Incremental Data Extraction for ETL using Database Snapshots - January 10, 2022
- Use Replication to improve the ETL process in SQL Server - November 4, 2021