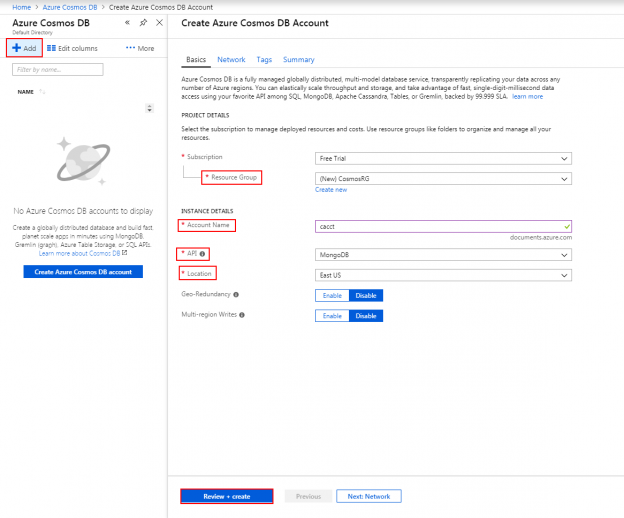
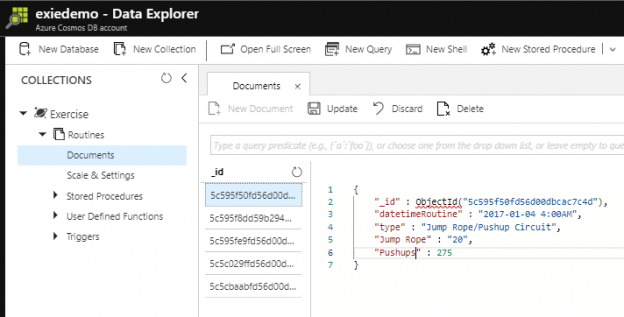
In the past two years, we’ve seen an explosion in growth with document-oriented databases like Azure Cosmos DB. MongoDB – one of the major document databases – went live on the Nasdaq and attracted some attention in the past year as well. While more developers are using the document structure for some appropriate data models, less than 10 years ago, some in the industry were predicting that document databases were unnecessary and wouldn’t last because all data could be flattened to fit the SQL model. I took the opposite approach, being an early adopter of MongoDB along with continuing to use SQL databases as I saw opportunities in both SQL and NoSQL for various data structures. While some data do fit the SQL model and SQL will continue to exist, some data are best for document databases, like Azure Cosmos DB. In this series, we’ll be looking at the why and how of document databases.