

Today is the day for SQL practice #1. In this series, so far, we’ve covered most important SQL commands (CREATE DATABASE & CREATE TABLE, INSERT, SELECT) and some concepts (primary key, foreign key) and theory (stored procedures, user-defined functions, views). Now it’s time to discuss some interesting SQL queries.
The Model
Let’s take a quick look at the model we’ll use in this practice.

You can expect that in real-life situations (e.g., interview), you’ll have a data model at your disposal. If not, then you’ll have the description of the database (tables and data types + additional description of what is stored where and how the tables are related).
The worst option is that you have to check all the tables first. E.g., you should run a SELECT statement on each table and conclude what is where and how the tables are related. This won’t probably happen at the interview but could happen in the real-life, e.g., when you continue working on an existing project.
Before We Start
The goal of this SQL practice is to analyze some typical assignments you could run into at the interview. Other places where this might help you are college assignments or completing tasks related to online courses.
The focus shall be on understanding what is required and what is the learning goal behind such a question. Before you continue, feel free to refresh your knowledge on INNER JOIN and LEFT JOIN, how to join multiple tables, SQL aggregate functions, and the approach to how to write complex queries. If you feel ready, let’s take a look at the first 2 queries (we’ll have some more in upcoming articles). For each query, we’ll describe the result we need, take a look at the query, analyze what is important for that query, and take a look at the result.
SQL Practice #1 – Aggregating & LEFT JOIN
Create a report that returns a list of all country names (in English), together with the number of related cities we have in the database. You need to show all countries as well as give a reasonable name to the aggregate column. Order the result by country name ascending.
|
1 2 3 4 5 |
SELECT country.country_name_eng, COUNT(city.id) AS number_of_cities FROM country LEFT JOIN city ON country.id = city.country_id GROUP BY country.id, country.country_name_eng ORDER BY country.country_name_eng ASC; |
Let’s analyze the most important parts of this query:
- We’ve used LEFT JOIN (LEFT JOIN city ON country.id = city.country_id) because we need to include all countries, even those without any related city
- We must use COUNT(city.id) AS number_of_cities and not only COUNT(*) AS number_of_cities because COUNT(*) would count if there is a row in the result (LEFT JOIN creates a row no matter if there is related data in other table or not). If we count the city.id, we’ll get the number of related cities
- The last important thing is that we’ve used GROUP BY country.id, country.country_name_eng instead of using only GROUP BY country.country_name_eng. In theory (and most cases), grouping by name should be enough. This will work OK if the name is defined as UNIQUE. Still, including a primary key from the dictionary, in cases similar to this one, is more than desired
You can see the result returned in the picture below.
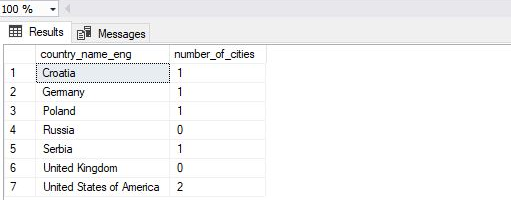
SQL Practice #2 – Combining Subquery & Aggregate Function
Write a query that returns customer id and name and the number of calls related to that customer. Return only customers that have more than the average number of calls of all customers.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
SELECT customer.id, customer.customer_name, COUNT(call.id) AS calls FROM customer INNER JOIN call ON call.customer_id = customer.id GROUP BY customer.id, customer.customer_name HAVING COUNT(call.id) > ( SELECT CAST(COUNT(*) AS DECIMAL(5,2)) / CAST(COUNT(DISTINCT customer_id) AS DECIMAL(5,2)) FROM call ); |
The important things I would like to emphasize here are:
- Please notice that we’ve used aggregate functions twice, once in the “main” query, and once in the subquery. This is expected because we need to calculate these two aggregate values separately – once for all customers (subquery) and for each customer separately (“main” query)
- The aggregate function in the “main” query is COUNT(call.id). It’s used in the SELECT part of the query, but we also need it in the HAVING part of the query (Note: HAVING clause is playing the role of the WHERE clause but for aggregate values)
- Group is created by id and customer name. These values are the ones we need to have in the result
- In the subquery, we’ve divided the total number of rows (COUNT(*)) by the number of distinct customers these calls were related to (COUNT(DISTINCT customer_id)). This gave us the average number of calls per customer
- The last important thing here is that we used the CAST operator (CAST(… AS DECIMAL(5,2))). This is needed because the final result would probably be a decimal number. Since both COUNTs are integers, SQL Server would also return an integer result. To prevent this from happening, we need to CAST both divider and the divisor as decimal numbers
Let’s take a look at what the query actually returned.

Conclusion
In today’s SQL practice, we’ve analyzed only two examples. Still, these two contain some parts you’ll often meet at assignments – either in your work, either in a testing (job interview, college assignments, online courses, etc.). In the next part, we’ll continue with a few more interesting queries that should help you solve problems you might run into.
Table of contents

His past and present engagements vary from database design and coding to teaching, consulting, and writing about databases. Also not to forget, BI, creating algorithms, chess, philately, 2 dogs, 2 cats, 1 wife, 1 baby...
You can find him on LinkedIn
View all posts by Emil Drkusic
- Learn SQL: How to prevent SQL Injection attacks - May 17, 2021
- Learn SQL: Dynamic SQL - March 3, 2021
- Learn SQL: SQL Injection - November 2, 2020