
Duplicate rows in a SQL Server database table can become a problem. We will see how we can find and handle those duplicate rows using T-SQL in this article.
Introduction
We might discover duplicate rows in a SQL Server database table. This article will describe T-SQL techniques to find them, and if necessary, remove them.
Sample Database
For this article, we’ll focus on a sample database called OFFICE_EQUIPMENT_DATABASE, Built-in SQL Server 2014 Standard Edition, on an updated Windows 10 PC. The database has this overall structure:
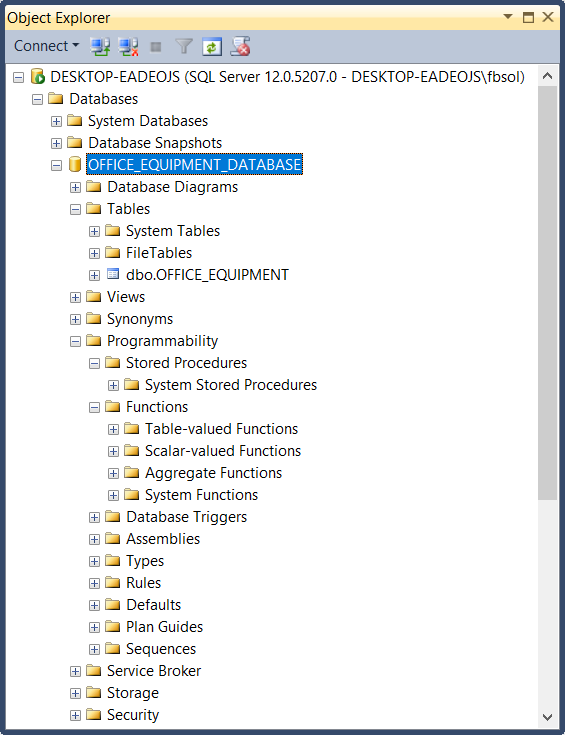
This database has no stored procedures, no user-defined functions, etc. It has one table, called OFFICE_EQUIPMENT as shown here:
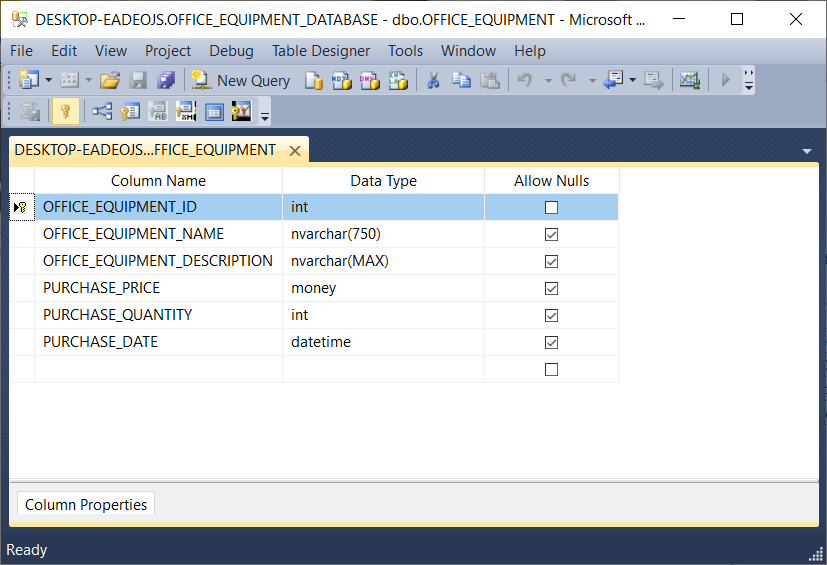
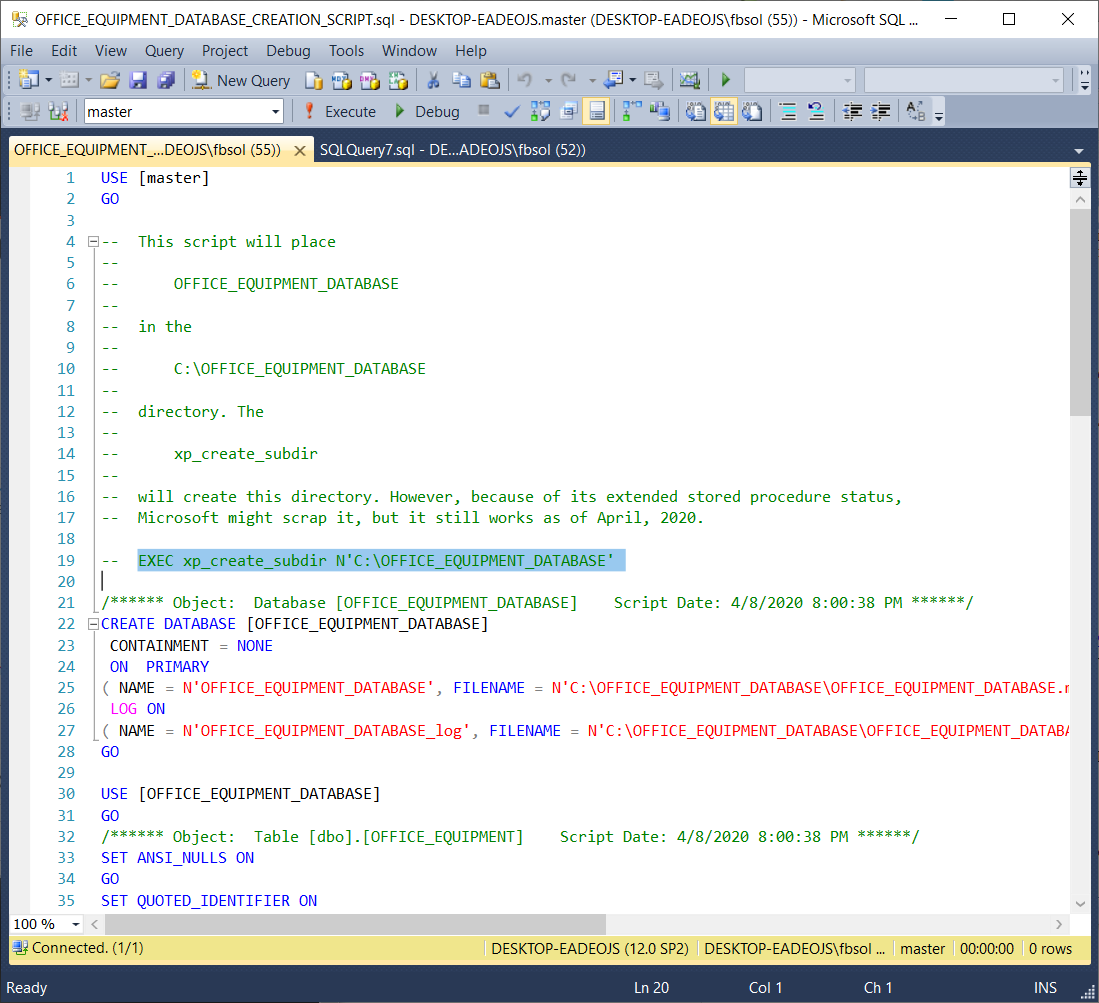
The following script will build the OFFICE_EQUIPMENT_DATABASE database, its table, and the rows in that table:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 |
USE [master] GO -- This script will place -- -- OFFICE_EQUIPMENT_DATABASE -- -- in the -- -- C:\OFFICE_EQUIPMENT_DATABASE -- -- directory. The -- -- xp_create_subdir -- -- will create this directory. However, because of its extended stored procedure status, -- Microsoft might scrap it, but it still works as of April, 2020. -- EXEC xp_create_subdir N'C:\OFFICE_EQUIPMENT_DATABASE' /****** Object: Database [OFFICE_EQUIPMENT_DATABASE] Script Date: 4/8/2020 8:00:38 PM ******/ CREATE DATABASE [OFFICE_EQUIPMENT_DATABASE] CONTAINMENT = NONE ON PRIMARY ( NAME = N'OFFICE_EQUIPMENT_DATABASE', FILENAME = N'C:\OFFICE_EQUIPMENT_DATABASE\OFFICE_EQUIPMENT_DATABASE.mdf' , SIZE = 4096KB , MAXSIZE = UNLIMITED, FILEGROWTH = 1024KB ) LOG ON ( NAME = N'OFFICE_EQUIPMENT_DATABASE_log', FILENAME = N'C:\OFFICE_EQUIPMENT_DATABASE\OFFICE_EQUIPMENT_DATABASE_log.ldf' , SIZE = 1024KB , MAXSIZE = 2048GB , FILEGROWTH = 10%) GO USE [OFFICE_EQUIPMENT_DATABASE] GO /****** Object: Table [dbo].[OFFICE_EQUIPMENT] Script Date: 4/8/2020 8:00:38 PM ******/ SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO CREATE TABLE [dbo].[OFFICE_EQUIPMENT]( [OFFICE_EQUIPMENT_ID] [int] NOT NULL, [OFFICE_EQUIPMENT_NAME] [nvarchar](750) NULL, [OFFICE_EQUIPMENT_DESCRIPTION] [nvarchar](max) NULL, [PURCHASE_PRICE] [money] NULL, [PURCHASE_QUANTITY] [int] NULL, [PURCHASE_DATE] [datetime] NULL, CONSTRAINT [PK_OFFICE_EQUIPMENT] PRIMARY KEY CLUSTERED ( [OFFICE_EQUIPMENT_ID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY] GO INSERT [dbo].[OFFICE_EQUIPMENT] ([OFFICE_EQUIPMENT_ID], [OFFICE_EQUIPMENT_NAME], [OFFICE_EQUIPMENT_DESCRIPTION], [PURCHASE_PRICE], [PURCHASE_QUANTITY], [PURCHASE_DATE]) VALUES (1, N'PRINTER PAPER', N'20 LB. PRINTER PAPER (ONE REAM)', 2.4900, 7, CAST(N'2019-03-17 00:00:00.000' AS DateTime)) GO INSERT [dbo].[OFFICE_EQUIPMENT] ([OFFICE_EQUIPMENT_ID], [OFFICE_EQUIPMENT_NAME], [OFFICE_EQUIPMENT_DESCRIPTION], [PURCHASE_PRICE], [PURCHASE_QUANTITY], [PURCHASE_DATE]) VALUES (2, N'PEN', N'BIC BALLPOINT PEN MEDIUM (BLUE)', 0.7000, 42, CAST(N'2020-01-08 00:00:00.000' AS DateTime)) GO INSERT [dbo].[OFFICE_EQUIPMENT] ([OFFICE_EQUIPMENT_ID], [OFFICE_EQUIPMENT_NAME], [OFFICE_EQUIPMENT_DESCRIPTION], [PURCHASE_PRICE], [PURCHASE_QUANTITY], [PURCHASE_DATE]) VALUES (3, N'PAPER CLIP', N'MEDIUM AND JUMBO PAPER CLIPS', 3.7900, 118, CAST(N'2019-11-12 00:00:00.000' AS DateTime)) GO INSERT [dbo].[OFFICE_EQUIPMENT] ([OFFICE_EQUIPMENT_ID], [OFFICE_EQUIPMENT_NAME], [OFFICE_EQUIPMENT_DESCRIPTION], [PURCHASE_PRICE], [PURCHASE_QUANTITY], [PURCHASE_DATE]) VALUES (4, N'STAPLER', N'SWINGLINE STAPLER - 20 SHEET CAPACITY', 5.1100, 3, CAST(N'2018-10-01 00:00:00.000' AS DateTime)) GO INSERT [dbo].[OFFICE_EQUIPMENT] ([OFFICE_EQUIPMENT_ID], [OFFICE_EQUIPMENT_NAME], [OFFICE_EQUIPMENT_DESCRIPTION], [PURCHASE_PRICE], [PURCHASE_QUANTITY], [PURCHASE_DATE]) VALUES (5, N'ENVELOPE', N'#10 BUSINESS SECURITY ENVELOPES - SINGLE WINDOW', 0.0400, 500, CAST(N'2019-08-22 00:00:00.000' AS DateTime)) GO INSERT [dbo].[OFFICE_EQUIPMENT] ([OFFICE_EQUIPMENT_ID], [OFFICE_EQUIPMENT_NAME], [OFFICE_EQUIPMENT_DESCRIPTION], [PURCHASE_PRICE], [PURCHASE_QUANTITY], [PURCHASE_DATE]) VALUES (6, N'PENCIL', N'#2 PENCIL', 0.0800, 150, CAST(N'2020-02-17 00:00:00.000' AS DateTime)) GO INSERT [dbo].[OFFICE_EQUIPMENT] ([OFFICE_EQUIPMENT_ID], [OFFICE_EQUIPMENT_NAME], [OFFICE_EQUIPMENT_DESCRIPTION], [PURCHASE_PRICE], [PURCHASE_QUANTITY], [PURCHASE_DATE]) VALUES (7, N'ERASER', N'TICONDEROGA PINK ERASER', 1.6700, 3, CAST(N'2020-01-22 00:00:00.000' AS DateTime)) GO INSERT [dbo].[OFFICE_EQUIPMENT] ([OFFICE_EQUIPMENT_ID], [OFFICE_EQUIPMENT_NAME], [OFFICE_EQUIPMENT_DESCRIPTION], [PURCHASE_PRICE], [PURCHASE_QUANTITY], [PURCHASE_DATE]) VALUES (8, N'PEN', N'BIC BALLPOINT PEN MEDIUM (BLUE)', 0.7000, 42, CAST(N'2020-01-08 00:00:00.000' AS DateTime)) GO INSERT [dbo].[OFFICE_EQUIPMENT] ([OFFICE_EQUIPMENT_ID], [OFFICE_EQUIPMENT_NAME], [OFFICE_EQUIPMENT_DESCRIPTION], [PURCHASE_PRICE], [PURCHASE_QUANTITY], [PURCHASE_DATE]) VALUES (9, N'PAPER CLIP', N'MEDIUM AND JUMBO PAPER CLIPS', 3.7900, 118, CAST(N'2019-11-12 00:00:00.000' AS DateTime)) GO INSERT [dbo].[OFFICE_EQUIPMENT] ([OFFICE_EQUIPMENT_ID], [OFFICE_EQUIPMENT_NAME], [OFFICE_EQUIPMENT_DESCRIPTION], [PURCHASE_PRICE], [PURCHASE_QUANTITY], [PURCHASE_DATE]) VALUES (10, N'PAPER CLIP', N'MEDIUM AND JUMBO PAPER CLIPS', 3.7900, 118, CAST(N'2019-11-12 00:00:00.000' AS DateTime)) GO INSERT [dbo].[OFFICE_EQUIPMENT] ([OFFICE_EQUIPMENT_ID], [OFFICE_EQUIPMENT_NAME], [OFFICE_EQUIPMENT_DESCRIPTION], [PURCHASE_PRICE], [PURCHASE_QUANTITY], [PURCHASE_DATE]) VALUES (11, N'PAPER CLIP', N'MEDIUM AND JUMBO PAPER CLIPS', 3.7900, 120, CAST(N'2019-11-12 00:00:00.000' AS DateTime)) GO INSERT [dbo].[OFFICE_EQUIPMENT] ([OFFICE_EQUIPMENT_ID], [OFFICE_EQUIPMENT_NAME], [OFFICE_EQUIPMENT_DESCRIPTION], [PURCHASE_PRICE], [PURCHASE_QUANTITY], [PURCHASE_DATE]) VALUES (12, N'PRINTER PAPER', N'20 LB. PRINTER PAPER (ONE REAM)', 2.4900, 7, CAST(N'2019-03-17 00:00:00.000' AS DateTime)) GO INSERT [dbo].[OFFICE_EQUIPMENT] ([OFFICE_EQUIPMENT_ID], [OFFICE_EQUIPMENT_NAME], [OFFICE_EQUIPMENT_DESCRIPTION], [PURCHASE_PRICE], [PURCHASE_QUANTITY], [PURCHASE_DATE]) VALUES (13, N'PRINTER PAPER', N'20 LB. PRINTER PAPER (ONE REAM)', 2.4900, 7, CAST(N'2019-03-17 00:00:00.000' AS DateTime)) GO INSERT [dbo].[OFFICE_EQUIPMENT] ([OFFICE_EQUIPMENT_ID], [OFFICE_EQUIPMENT_NAME], [OFFICE_EQUIPMENT_DESCRIPTION], [PURCHASE_PRICE], [PURCHASE_QUANTITY], [PURCHASE_DATE]) VALUES (14, N'PRINTER PAPER', N'20 LB. PRINTER PAPER (ONE REAM)', 2.4900, 7, CAST(N'2018-03-17 00:00:00.000' AS DateTime)) GO INSERT [dbo].[OFFICE_EQUIPMENT] ([OFFICE_EQUIPMENT_ID], [OFFICE_EQUIPMENT_NAME], [OFFICE_EQUIPMENT_DESCRIPTION], [PURCHASE_PRICE], [PURCHASE_QUANTITY], [PURCHASE_DATE]) VALUES (15, N'PAPER CLIP', N'MEDIUM AND JUMBO PAPER CLIPS', 3.8900, 118, CAST(N'2019-11-12 00:00:00.000' AS DateTime)) GO INSERT [dbo].[OFFICE_EQUIPMENT] ([OFFICE_EQUIPMENT_ID], [OFFICE_EQUIPMENT_NAME], [OFFICE_EQUIPMENT_DESCRIPTION], [PURCHASE_PRICE], [PURCHASE_QUANTITY], [PURCHASE_DATE]) VALUES (16, N'PRINTER PAPER', N'35 LB. PRINTER PAPER (ONE REAM)', 2.4900, 7, CAST(N'2019-11-12 00:00:00.000' AS DateTime)) GO |
This script places the database LDF and MDF files in the C:\OFFICE_EQUIPMENT_DATABASE directory. We can manually create this directory, but the screenshot below shows the T-SQL call to an extended stored procedure xp_create_subdir at line 19. We can create the directory if we manually “paint” and execute this line. As an extended stored procedure, Microsoft could scrap xp_create_subdir at any time, but the above script includes it as an option. Of course, we can uncomment line 19 before running the script.
The Table Data
Run the below statements to see all of the OFFICE_EQUIPMENT table rows, as seen in this screenshot:
|
1 2 3 4 5 6 |
USE OFFICE_EQUIPMENT_DATABASE; SELECT OFFICE_EQUIPMENT_ID, OFFICE_EQUIPMENT_NAME, OFFICE_EQUIPMENT_DESCRIPTION, PURCHASE_PRICE, PURCHASE_QUANTITY, PURCHASE_DATE FROM OFFICE_EQUIPMENT ORDER BY OFFICE_EQUIPMENT_NAME; |
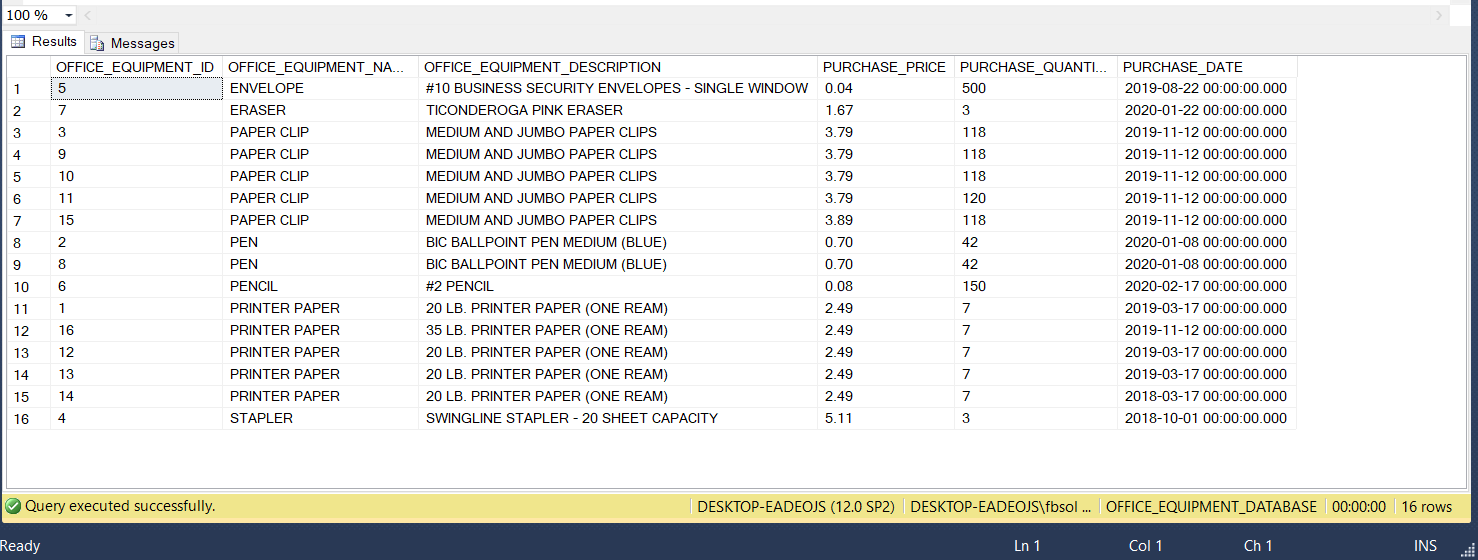
Every row has a unique OFFICE_EQUIPMENT_ID value. In a way, the table has unique rows because the OFFICE_EQUIPMENT_ID column operates as a primary key field in this table. If we ignore this column, however, we can clearly see that many rows have duplicate data shared across other columns. For example, this code returns rows with duplicate non-ID values:
|
1 2 3 4 5 6 |
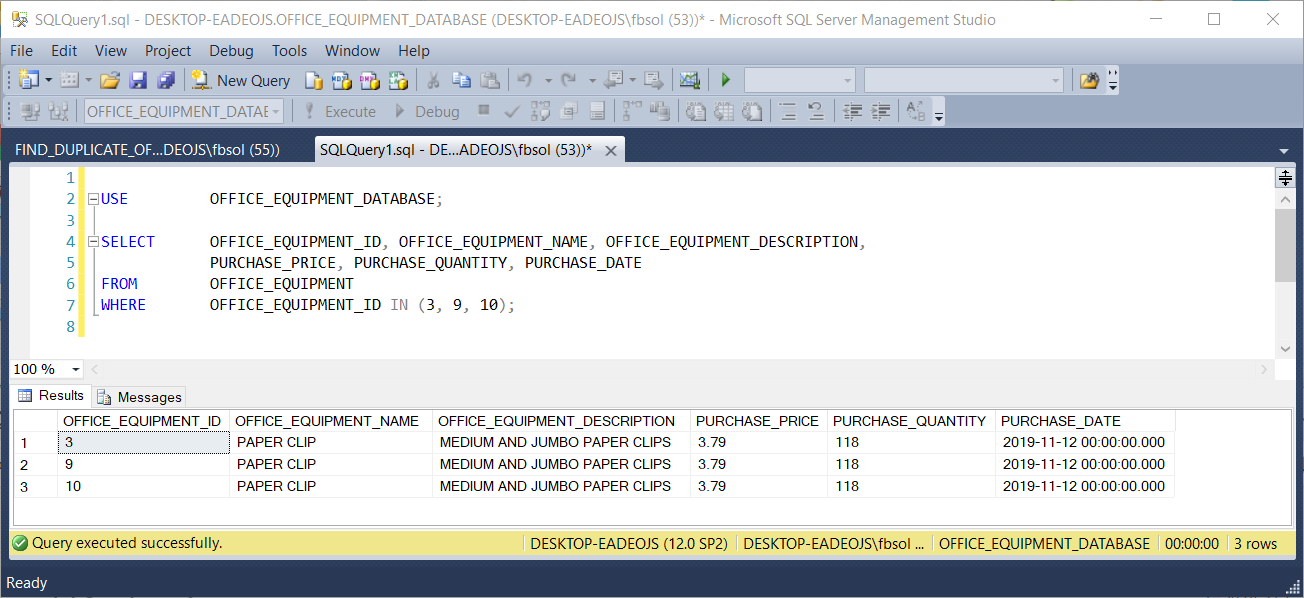
USE OFFICE_EQUIPMENT_DATABASE; SELECT OFFICE_EQUIPMENT_ID, OFFICE_EQUIPMENT_NAME, OFFICE_EQUIPMENT_DESCRIPTION, PURCHASE_PRICE, PURCHASE_QUANTITY, PURCHASE_DATE FROM OFFICE_EQUIPMENT WHERE OFFICE_EQUIPMENT_ID IN (3, 9, 10); |
This screenshot shows the result set:
This code returns another result set with similar behavior:
|
1 2 3 4 5 6 |
USE OFFICE_EQUIPMENT_DATABASE; SELECT OFFICE_EQUIPMENT_ID, OFFICE_EQUIPMENT_NAME, OFFICE_EQUIPMENT_DESCRIPTION, PURCHASE_PRICE, PURCHASE_QUANTITY, PURCHASE_DATE FROM OFFICE_EQUIPMENT WHERE OFFICE_EQUIPMENT_ID IN (1, 13, 14); |
This screenshot shows the second result set:

Simply looking for duplicate rows by eye might work for a sixteen-row table, but it won’t work for a table with thousands, or millions, of rows. We need a better technique.
Identify Duplicate Data Rows
In an earlier SQL Shack article Overview of the SQL ROW_NUMBER function, Prashanth Jayaram explored the SQL Server ROW_NUMBER() function. This function will become an important part of the solution we’ll build. When we use the T-SQL ROW_NUMBER() function, we must also add a certain SQL clause to separate, or partition, a query result set. This partition separates the result set rows into at least one defined subset of rows, only for use by the ROW_NUMBER() function. The partition process might produce one subset that covers all the rows – that’s OK. ROW_NUMBER() needs this separation to support its row numbering operations. The partitioning does not change the data in any way. Prashanth explained that the ROW_NUMBER() function will set a sequential number, in a separate column, for every row in the row subset partition. The OVER() clause placed right after the ROW_NUMBER() function handles the partitioning task for ROW_NUMBER(). In this T-SQL query, the ROW_NUM column sequentially numbers every row:
|
1 2 3 4 5 6 |
USE OFFICE_EQUIPMENT_DATABASE; SELECT OFFICE_EQUIPMENT_ID, OFFICE_EQUIPMENT_NAME, OFFICE_EQUIPMENT_DESCRIPTION, PURCHASE_PRICE, PURCHASE_QUANTITY, PURCHASE_DATE, ROW_NUMBER() OVER(ORDER BY OFFICE_EQUIPMENT_NAME) AS ROW_NUM FROM OFFICE_EQUIPMENT; |
This screenshot shows the result set:
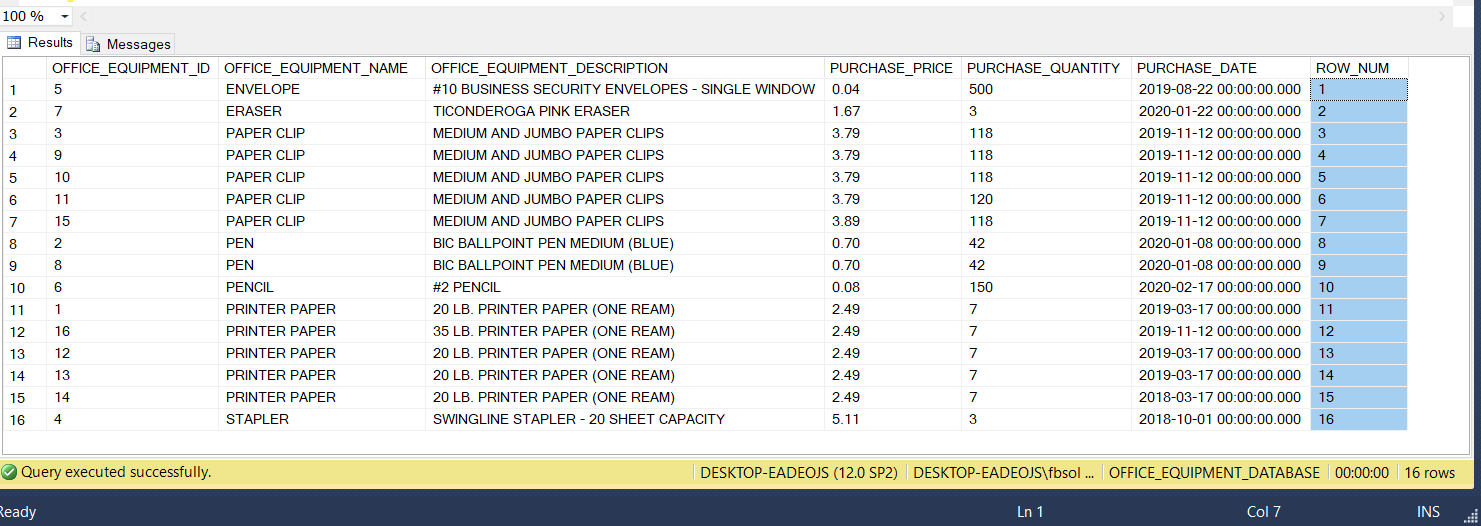
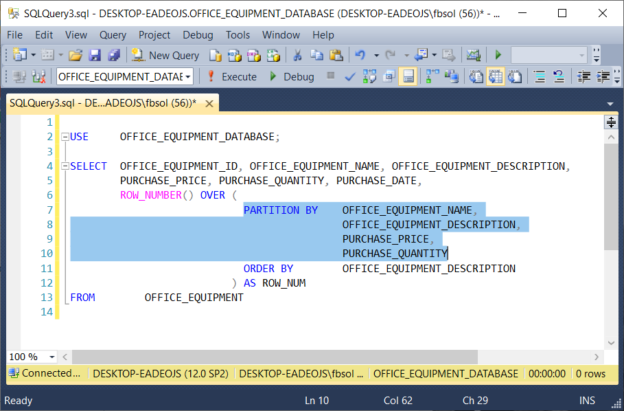
Microsoft explains that the OVER() clause “ . . . determines the partitioning and ordering of a rowset . . .” Its syntax offers many options, but to solve our specific problem, we’ll use the ORDER BY clause with the ROW_COUNT() function. The ORDER BY clause as used here expects at least one column, and we’ll use the OFFICE_EQUIPMENT_NAME column, as seen at line 6 in the above screenshot. Any specific table column, or any combination of table columns, will work here. The T-SQL ROW_NUMBER() function will get the complete OVER() clause it wants, and it can then set a ROW_NUM value for each row. As a side effect, this ORDER BY clause will also determine the row order of the final query result set. We made some progress, but we must define the rules that make rows identical. Then, we must gather those defined duplicate rows together. The PARTITION BY clause will solve this part of the problem.
Placed in the OVER() clause, the T-SQL PARTITION BY clause divides, or separates, the result set rows into subsets, or partitions. The OVER clause can use these subsets in its own operations that support other SQL Server functions. We can use the OVER() clause here to build a definition of duplicate rows.
In the below query, the OVER clause has a PARTITION BY clause, in addition to its required ORDER BY clause. As seen in a new query tab, this screenshot highlights the PARTITION BY clause:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
USE OFFICE_EQUIPMENT_DATABASE; SELECT OFFICE_EQUIPMENT_ID, OFFICE_EQUIPMENT_NAME, OFFICE_EQUIPMENT_DESCRIPTION, PURCHASE_PRICE, PURCHASE_QUANTITY, PURCHASE_DATE, ROW_NUMBER() OVER ( PARTITION BY OFFICE_EQUIPMENT_NAME, OFFICE_EQUIPMENT_DESCRIPTION, PURCHASE_PRICE, PURCHASE_QUANTITY ORDER BY OFFICE_EQUIPMENT_DESCRIPTION ) AS ROW_NUM FROM OFFICE_EQUIPMENT |
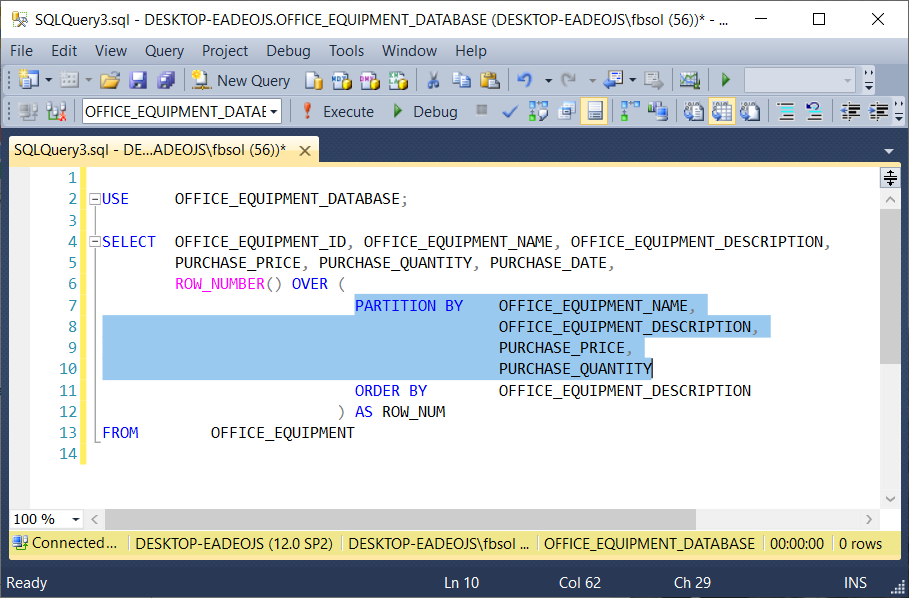
As used in the OVER() clause of this example, the PARTITION BY clause has a list of columns. In this case, PARTITION BY has columns from the OFFICE_EQUIPMENT table. When the ROW_NUMBER() function separates, or partitions, the result set rows, it uses the PARTITION BY column list to decide which columns have the values that define duplicate rows. This screenshot shows the query result set:
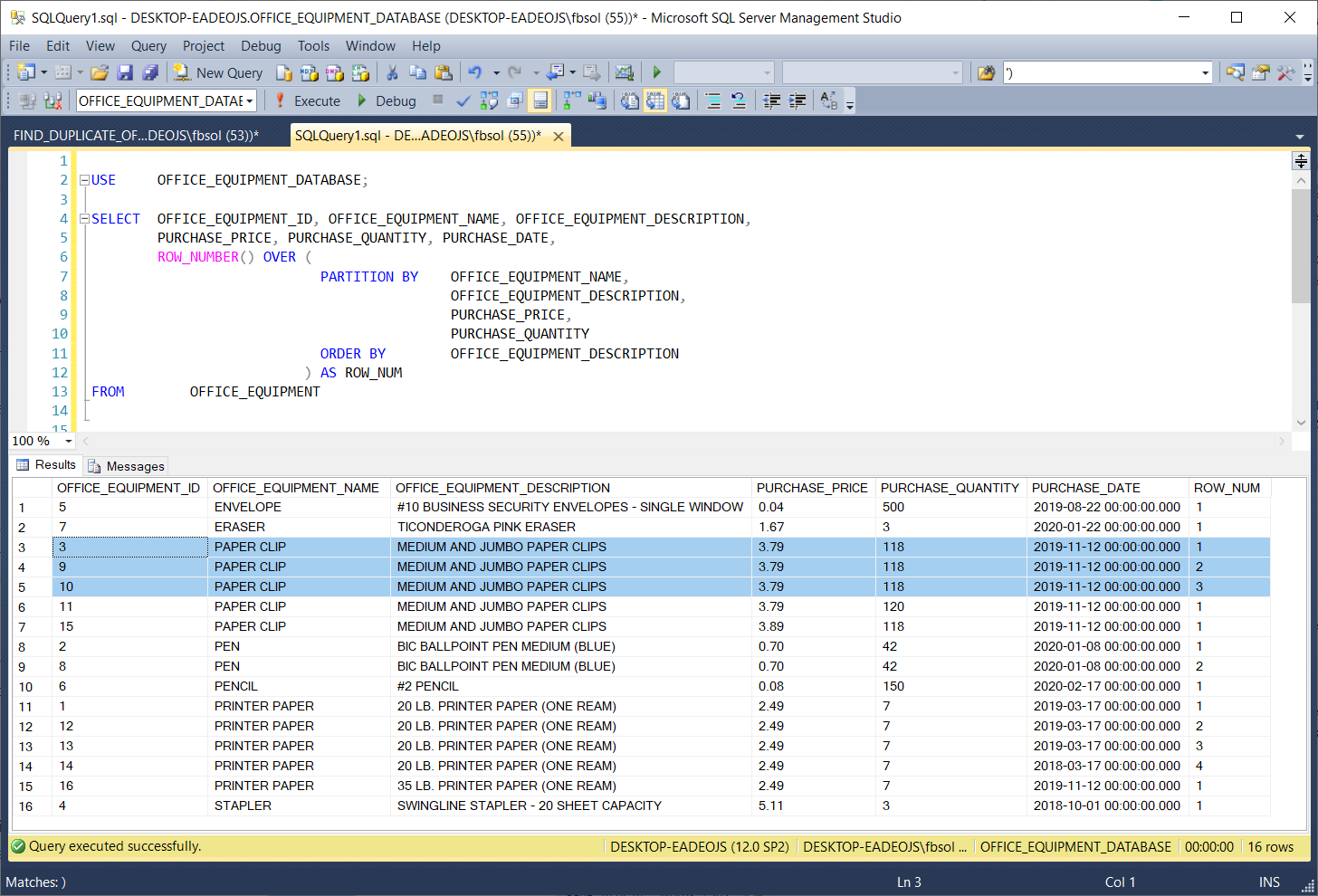
In this query, PARTITION BY looks at the values in the columns and if it finds result set rows that have identical values in all of these columns, it places these rows into a separate partition.
|
1 2 3 4 |
OFFICE_EQUIPMENT_NAME, OFFICE_EQUIPMENT_DESCRIPTION, PURCHASE_PRICE, PURCHASE_QUANTITY |
If it can build more than one different partition from the same result set, it will do so. The highlighted result set rows have identical values in these columns, so PARTITION BY brought them together in a separate partition. Then, the T-SQL ROW_NUMBER() function numbered these rows in the ROW_NUM column, starting at 1 and ending at 3. At rows 11 through 14, PARTITION BY brought another set of rows together, as shown in this screenshot:
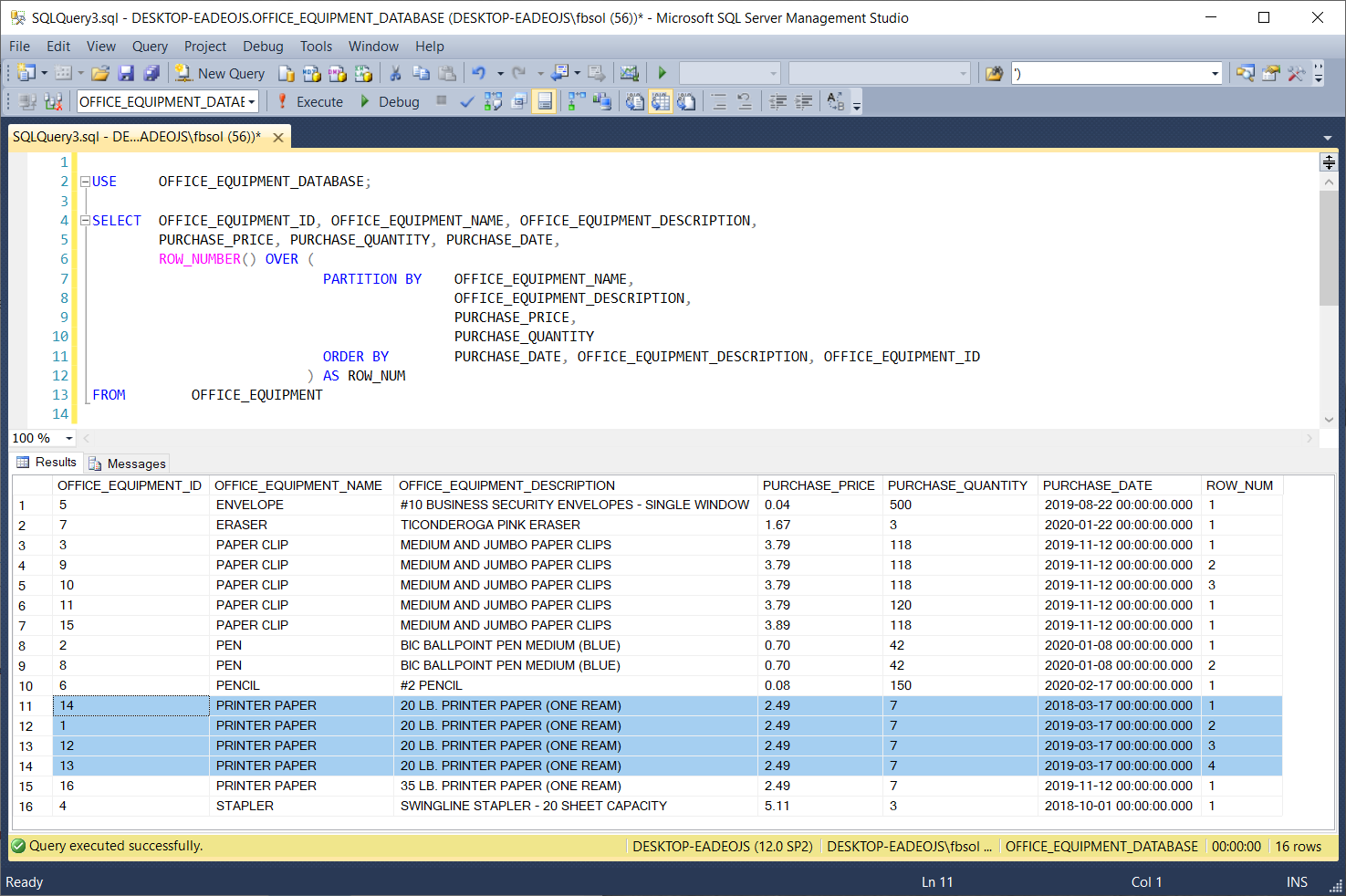
ROW_NUMBER(), OVER(), and PARTITION BY make no changes to the original data in any source database tables. Also, the ORDER BY clause in the T-SQL OVER() clause handles one, some, or all of the OFFICE_EQUIPMENT table columns, as seen in this screenshot:
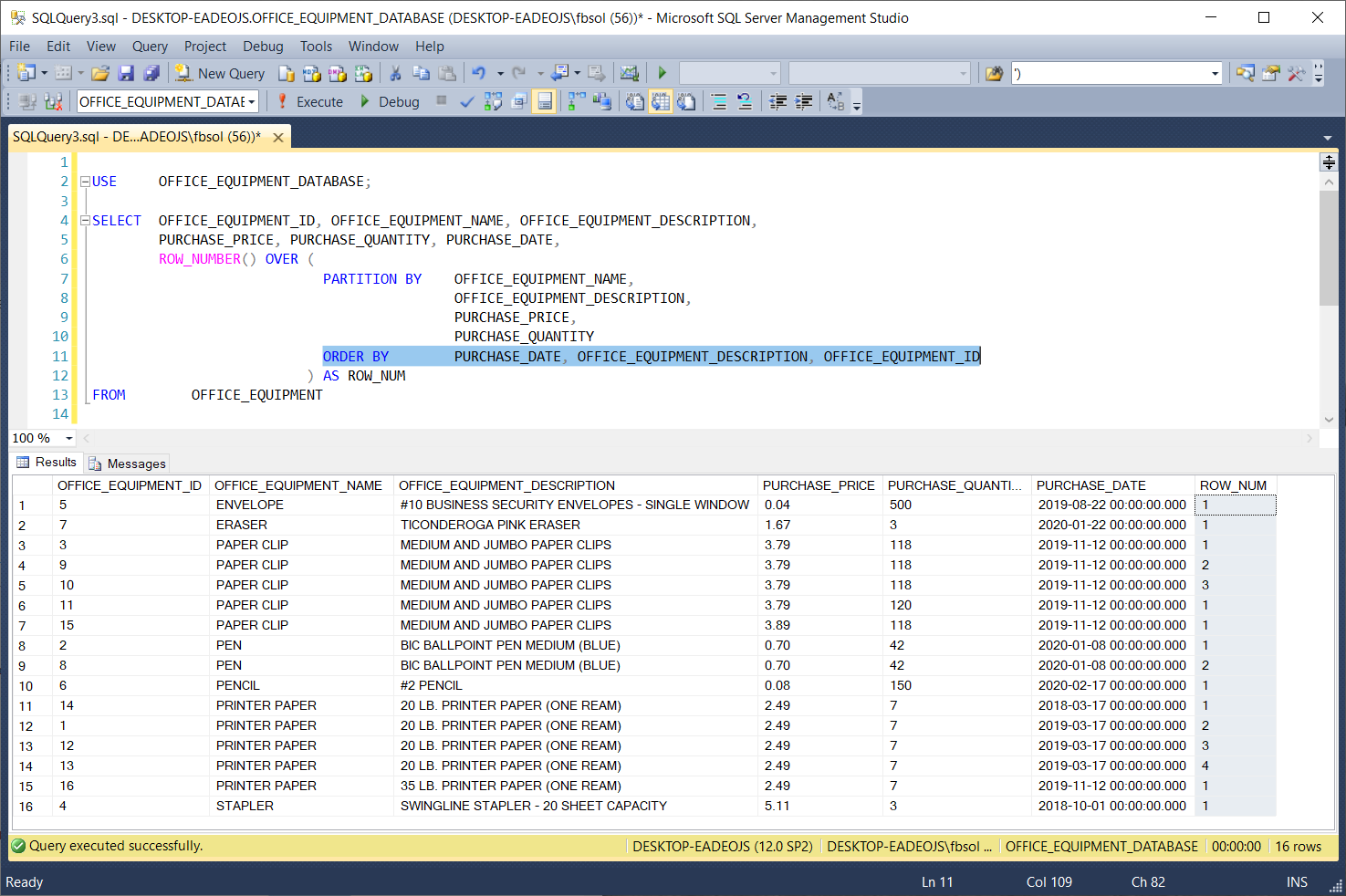
In the OFFICE_EQUIPMENT table, the OFFICE_EQUIPMENT_ID column has unique values in all of the rows. If we add this column to the PARTITION BY column list, the ROW_NUM will have values of 1 in all rows, as shown in this screenshot:
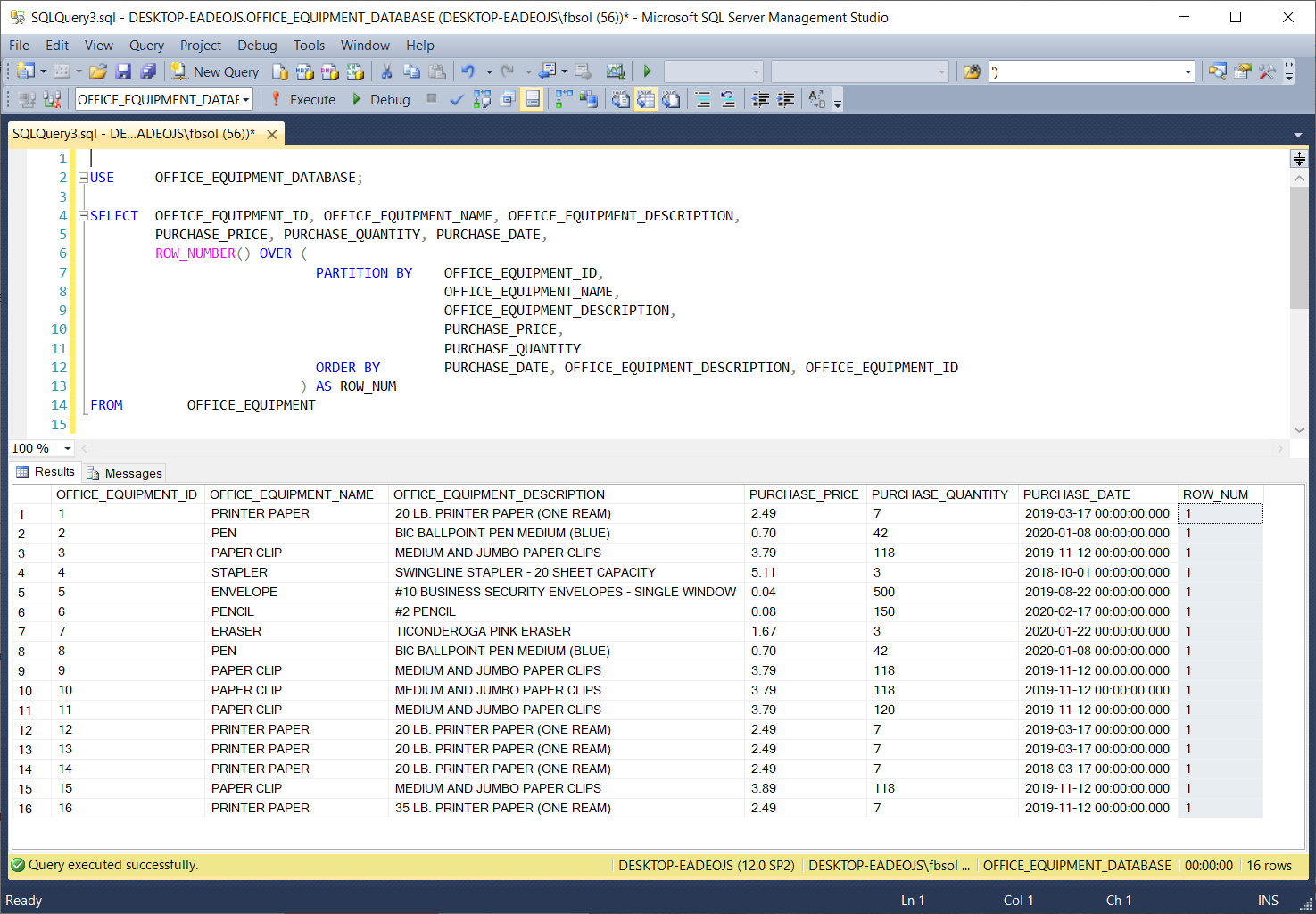
This makes sense, because PARTITION BY now looks at a column set with unique values in at least one column – in this case, OFFICE_EQUIPMENT_ID. Therefore, every row that PARTITION BY sees has a unique set of values, and it will place every row in a separate partition. Those partitions will have only one row. Therefore, every row, in every partition, will have a ROW_NUM value of 1.
The PARTITION BY clause offers fine-grained control over the columns we use to define the duplicate rows that form the partitions themselves. This query modifies an earlier query, commenting out the OFFICE_EQUIPMENT_DESCRIPTION column in the PARTITION BY clause:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
USE OFFICE_EQUIPMENT_DATABASE; SELECT OFFICE_EQUIPMENT_ID, OFFICE_EQUIPMENT_NAME, OFFICE_EQUIPMENT_DESCRIPTION, PURCHASE_PRICE, PURCHASE_QUANTITY, PURCHASE_DATE, ROW_NUMBER() OVER ( PARTITION BY OFFICE_EQUIPMENT_NAME, -- OFFICE_EQUIPMENT_DESCRIPTION, PURCHASE_PRICE, PURCHASE_QUANTITY ORDER BY OFFICE_EQUIPMENT_DESCRIPTION ) AS ROW_NUM FROM OFFICE_EQUIPMENT |
This screenshot shows the result set:

The T-SQL PARTITION BY clause gathered the highlighted rows into one separate partition, similar to the highlighted rows shown three screenshots above. In this case, however, row 15, with OFFICE_EQUIPMENT_ID value of 16, has an OFFICE_EQUIPMENT_DESCRIPTION value of “35 LB. PRINTER PAPER (ONE REAM)” which differs from the values of this column in the other rows in this subset of rows. Additionally, row 14, with OFFICE_EQUIPMENT_ID value of 14, has a PURCHASE_DATE value of 2018-03-17 00:00:00.000 which differs from the values of this column in the other rows in this subset of rows.
The query gathered and numbered these rows in the same row partition because the T-SQL PARTITION BY clause in this query defines duplicate rows based on the columns.
|
1 2 3 |
OFFICE_EQUIPMENT_NAME PURCHASE_PRICE PURCHASE_QUANTITY |
It ignores columns with potentially different values, as it builds the partitions of rows it defines as identical.
Handling Duplicate Data Rows
Now that we can define and identify duplicate rows, we can decide what to do with them. Before we begin, this script will delete and reinsert the original rows in the OFFICE_EQUIPMENT table:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
USE OFFICE_EQUIPMENT_DATABASE; TRUNCATE TABLE OFFICE_EQUIPMENT; INSERT INTO OFFICE_EQUIPMENT (OFFICE_EQUIPMENT_ID, OFFICE_EQUIPMENT_NAME, OFFICE_EQUIPMENT_DESCRIPTION, PURCHASE_PRICE, PURCHASE_QUANTITY, PURCHASE_DATE) VALUES (1, N'PRINTER PAPER', N'20 LB. PRINTER PAPER (ONE REAM)', 2.4900, 7, CAST(N'2019-03-17 00:00:00.000' AS DateTime)), (2, N'PEN', N'BIC BALLPOINT PEN MEDIUM (BLUE)', 0.7000, 42, CAST(N'2020-01-08 00:00:00.000' AS DateTime)), (3, N'PAPER CLIP', N'MEDIUM AND JUMBO PAPER CLIPS', 3.7900, 118, CAST(N'2019-11-12 00:00:00.000' AS DateTime)), (4, N'STAPLER', N'SWINGLINE STAPLER - 20 SHEET CAPACITY', 5.1100, 3, CAST(N'2018-10-01 00:00:00.000' AS DateTime)), (5, N'ENVELOPE', N'#10 BUSINESS SECURITY ENVELOPES - SINGLE WINDOW', 0.0400, 500, CAST(N'2019-08-22 00:00:00.000' AS DateTime)), (6, N'PENCIL', N'#2 PENCIL', 0.0800, 150, CAST(N'2020-02-17 00:00:00.000' AS DateTime)), (7, N'ERASER', N'TICONDEROGA PINK ERASER', 1.6700, 3, CAST(N'2020-01-22 00:00:00.000' AS DateTime)), (8, N'PEN', N'BIC BALLPOINT PEN MEDIUM (BLUE)', 0.7000, 42, CAST(N'2020-01-08 00:00:00.000' AS DateTime)), (9, N'PAPER CLIP', N'MEDIUM AND JUMBO PAPER CLIPS', 3.7900, 118, CAST(N'2019-11-12 00:00:00.000' AS DateTime)), (10, N'PAPER CLIP', N'MEDIUM AND JUMBO PAPER CLIPS', 3.7900, 118, CAST(N'2019-11-12 00:00:00.000' AS DateTime)), (11, N'PAPER CLIP', N'MEDIUM AND JUMBO PAPER CLIPS', 3.7900, 120, CAST(N'2019-11-12 00:00:00.000' AS DateTime)), (12, N'PRINTER PAPER', N'20 LB. PRINTER PAPER (ONE REAM)', 2.4900, 7, CAST(N'2019-03-17 00:00:00.000' AS DateTime)), (13, N'PRINTER PAPER', N'20 LB. PRINTER PAPER (ONE REAM)', 2.4900, 7, CAST(N'2019-03-17 00:00:00.000' AS DateTime)), (14, N'PRINTER PAPER', N'20 LB. PRINTER PAPER (ONE REAM)', 2.4900, 7, CAST(N'2018-03-17 00:00:00.000' AS DateTime)), (15, N'PAPER CLIP', N'MEDIUM AND JUMBO PAPER CLIPS', 3.8900, 118, CAST(N'2019-11-12 00:00:00.000' AS DateTime)), (16, N'PRINTER PAPER', N'35 LB. PRINTER PAPER (ONE REAM)', 2.4900, 7, CAST(N'2019-11-12 00:00:00.000' AS DateTime)); |
We saw this query earlier in this article:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
USE OFFICE_EQUIPMENT_DATABASE; SELECT OFFICE_EQUIPMENT_ID, OFFICE_EQUIPMENT_NAME, OFFICE_EQUIPMENT_DESCRIPTION, PURCHASE_PRICE, PURCHASE_QUANTITY, PURCHASE_DATE, ROW_NUMBER() OVER ( PARTITION BY OFFICE_EQUIPMENT_NAME, OFFICE_EQUIPMENT_DESCRIPTION, PURCHASE_PRICE, PURCHASE_QUANTITY ORDER BY OFFICE_EQUIPMENT_DESCRIPTION ) AS ROW_NUM FROM OFFICE_EQUIPMENT |
This query partitions the OFFICE_EQUIPMENT table on these columns:
|
1 2 3 4 |
OFFICE_EQUIPMENT_NAME OFFICE_EQUIPMENT_DESCRIPTION PURCHASE_PRICE PURCHASE_QUANTITY |
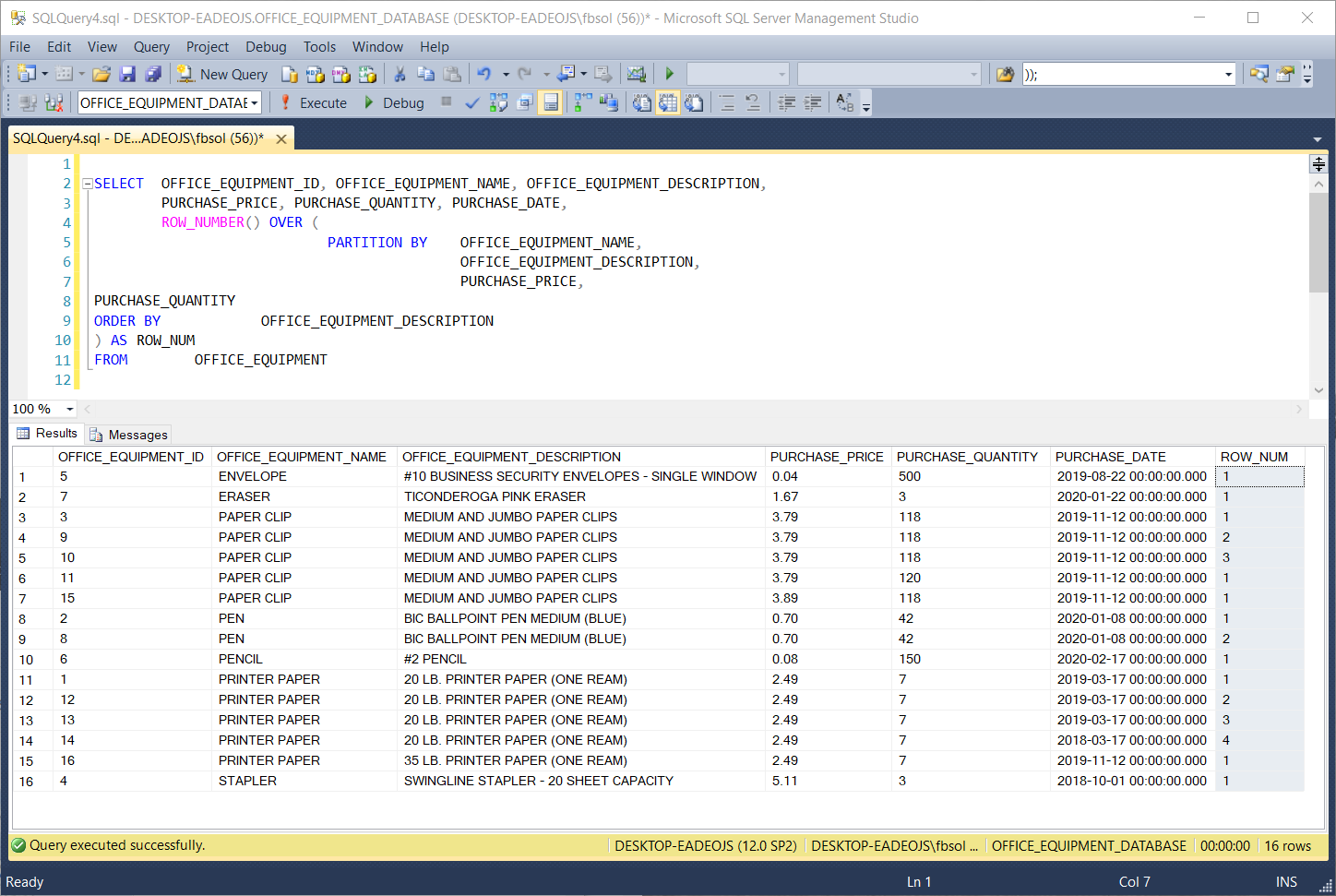
In this screenshot, the ROW_NUM column values greater than 1 flag the duplicate rows, as we defined them in the PARTITION BY clause. We can try to return only those duplicate rows, with this query:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
USE OFFICE_EQUIPMENT_DATABASE; SELECT OFFICE_EQUIPMENT_ID, OFFICE_EQUIPMENT_NAME, OFFICE_EQUIPMENT_DESCRIPTION, PURCHASE_PRICE, PURCHASE_QUANTITY, PURCHASE_DATE, ROW_NUMBER() OVER ( PARTITION BY OFFICE_EQUIPMENT_NAME, OFFICE_EQUIPMENT_DESCRIPTION, PURCHASE_PRICE, PURCHASE_QUANTITY ORDER BY OFFICE_EQUIPMENT_DESCRIPTION ) AS ROW_NUM FROM OFFICE_EQUIPMENT WHERE ROW_NUM > 1 |
However, this won’t work, as this screenshot shows:
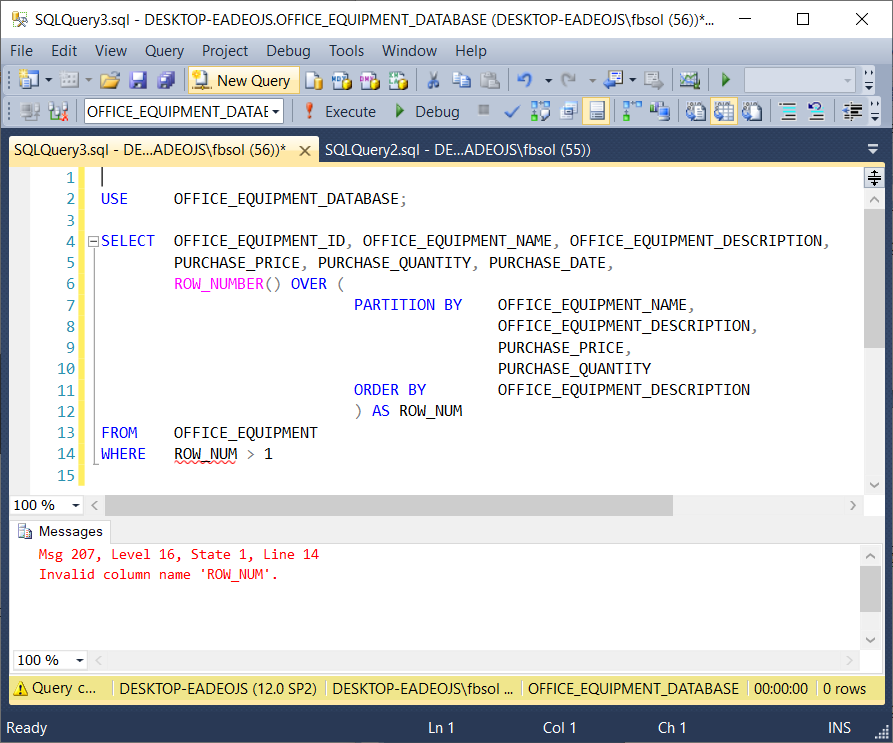
Microsoft explains that the WHERE clause executes before the SELECT clause. As a result, the WHERE clause in this query will never see the ROW_NUM column, and the query returns an error. However, the Microsoft source also explains that the FROM clause executes first. With this in mind, we can rebuild the query. We’ll use the above query as a subquery in the FROM clause of a parent query, as seen here:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
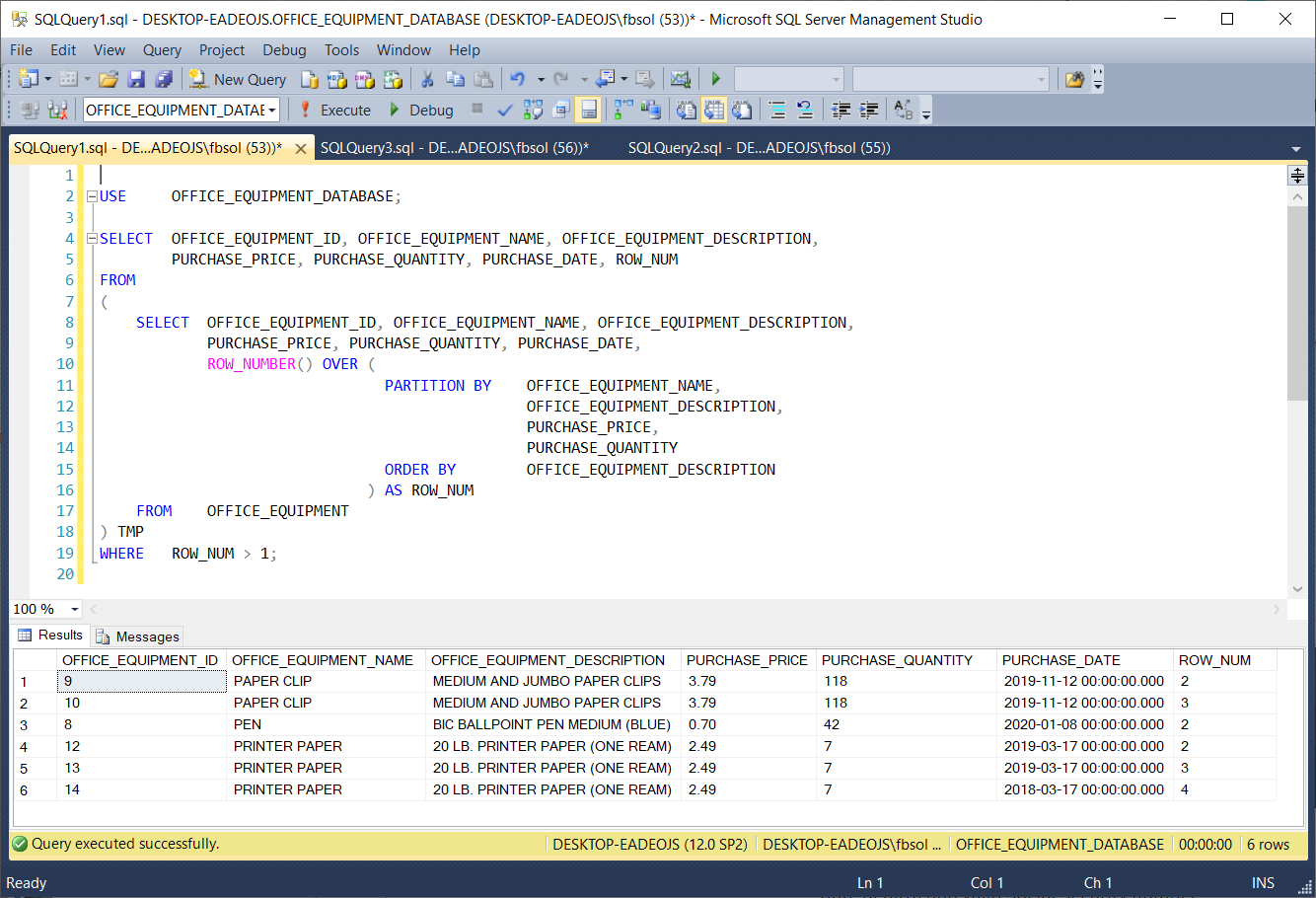
USE OFFICE_EQUIPMENT_DATABASE; SELECT OFFICE_EQUIPMENT_ID, OFFICE_EQUIPMENT_NAME, OFFICE_EQUIPMENT_DESCRIPTION, PURCHASE_PRICE, PURCHASE_QUANTITY, PURCHASE_DATE, ROW_NUM FROM ( SELECT OFFICE_EQUIPMENT_ID, OFFICE_EQUIPMENT_NAME, OFFICE_EQUIPMENT_DESCRIPTION, PURCHASE_PRICE, PURCHASE_QUANTITY, PURCHASE_DATE, ROW_NUMBER() OVER ( PARTITION BY OFFICE_EQUIPMENT_NAME, OFFICE_EQUIPMENT_DESCRIPTION, PURCHASE_PRICE, PURCHASE_QUANTITY ORDER BY OFFICE_EQUIPMENT_DESCRIPTION ) AS ROW_NUM FROM OFFICE_EQUIPMENT ) TMP WHERE ROW_NUM > 1; |
This screenshot shows that the WHERE clause filter worked:
Expanding on this approach, this query will delete the duplicate rows:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
USE OFFICE_EQUIPMENT_DATABASE; DELETE OE FROM ( SELECT OFFICE_EQUIPMENT_ID, ROW_NUMBER() OVER ( PARTITION BY OFFICE_EQUIPMENT_NAME, OFFICE_EQUIPMENT_DESCRIPTION, PURCHASE_PRICE, PURCHASE_QUANTITY ORDER BY OFFICE_EQUIPMENT_DESCRIPTION ) AS ROW_NUM FROM OFFICE_EQUIPMENT ) DRT INNER JOIN OFFICE_EQUIPMENT OE ON -- ALIAS DUPLICATE_ROW_TABLE AS DRT DRT.OFFICE_EQUIPMENT_ID = OE.OFFICE_EQUIPMENT_ID WHERE DRT.ROW_NUM > 1; |
This screenshot shows that the query worked:
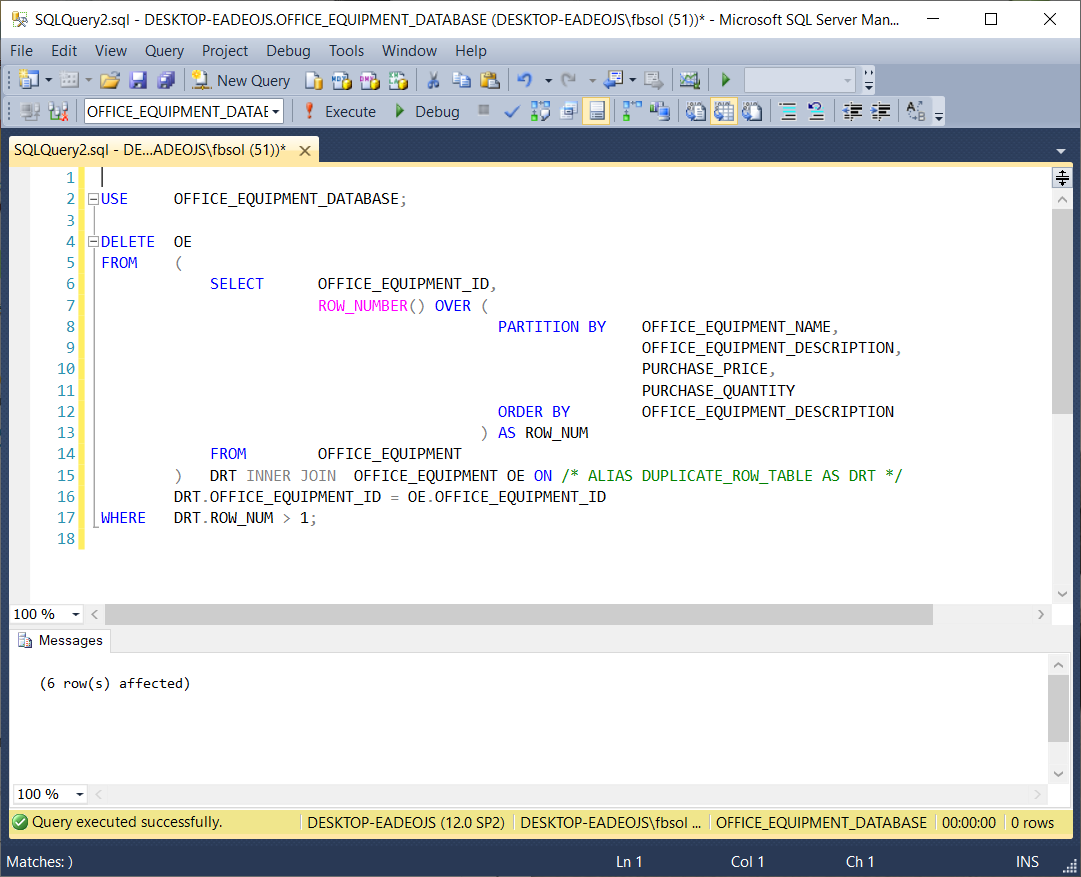
The information from Microsoft helped out. In a parent query, we placed the original ROW_NUMBER() query as a subquery in the FROM clause. We aliased this subquery as DRT at line 15, and joined DRT to the OFFICE_EQUIPMENT table at lines 15 and 16. The parent query WHERE clause at line 17 filtered the duplicate rows found in the DRT subquery.
We can use this query to test the DELETE:
|
1 2 3 4 5 6 7 8 9 |
USE OFFICE_EQUIPMENT_DATABASE; SELECT OFFICE_EQUIPMENT_ID, OFFICE_EQUIPMENT_NAME, OFFICE_EQUIPMENT_DESCRIPTION, PURCHASE_PRICE, PURCHASE_QUANTITY, ROW_NUMBER() OVER (PARTITION BY OFFICE_EQUIPMENT_NAME, OFFICE_EQUIPMENT_DESCRIPTION, PURCHASE_PRICE, PURCHASE_QUANTITY ORDER BY OFFICE_EQUIPMENT_DESCRIPTION) AS RANK1 FROM OFFICE_EQUIPMENT |
Using this test query, this screenshot verifies the DELETE query:
Instead of deleting the duplicate rows, we might want to identify them first, and decide what to do later. We can modify the DELETE query we saw earlier to build a new query as seen here and in the screenshot below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
USE OFFICE_EQUIPMENT_DATABASE; SELECT OFFICE_EQUIPMENT_ID FROM ( SELECT OFFICE_EQUIPMENT_ID, ROW_NUMBER() OVER ( PARTITION BY OFFICE_EQUIPMENT_NAME, OFFICE_EQUIPMENT_DESCRIPTION, PURCHASE_PRICE, PURCHASE_QUANTITY ORDER BY OFFICE_EQUIPMENT_DESCRIPTION ) AS ROW_NUM FROM OFFICE_EQUIPMENT ) ROW_NUM |
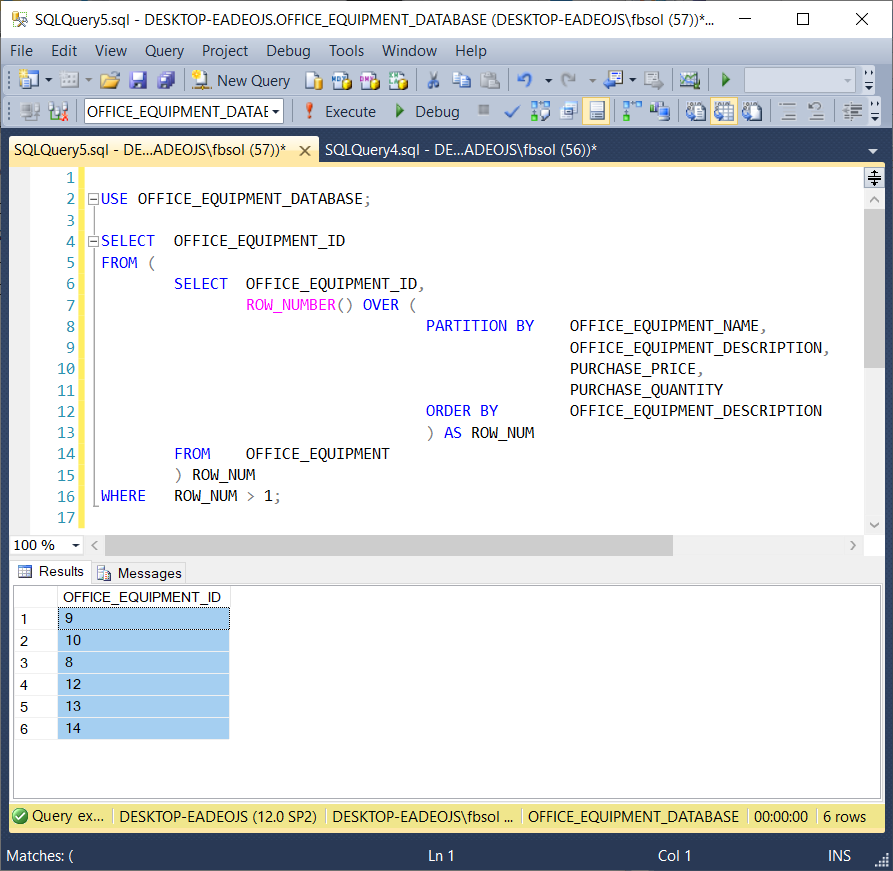
Similar to the earlier DELETE query, we placed the original ROW_NUMBER() query as a subquery in the FROM clause. The FROM clause at line 5 executes first – before the line 16 WHERE clause. This means that the T-SQL WHERE clause can see the ROW_NUMBER() data, and filter on it. Now that we have the specific OFFICE_EQUIPMENT_ID values that we need in a list, we can place these values in another table, use them in other queries, etc.
Conclusion
As database resources grow in size and importance, we need to measure their data quality, to identify and fix problems. As part of that, we should identify duplicate database table rows. Then, we can delete them. We can move them to other tables, other databases, or even other servers. Once we find those duplicate rows, we can decide what to do next. This article shows how to lever T-SQL to find those duplicate rows.

See more about Frank at LinkedIn.
Remove the non-standard characters from this address: fb} <s.author@gmail.com to reach him by email.
- Lever the TSQL MAX/MIN/IIF functions for Pinpoint Row Pivots - May 16, 2022
- Use Kusto Query Language to solve a data problem - July 5, 2021
- Azure Data Explorer and the Kusto Query Language - June 21, 2021