
This article explains what the basic features and differences between ETL and ELT are. I’m also going to explain in detail what an ELT pipeline is and a relevant architecture for the same in Azure. So far, we have come a long way dealing with ETL tools which basically are Extract, Transformation and Load technique used in populating a data warehouse. ELT, on the other hand, is another way to load data into a warehouse that implements the process of Extract, Load and Transform.
When we try to understand ETL, it is the technique that we use to connect to source data, extract the data from those sources, transform the data in-memory to support the reporting requirements and then finally load the transformed data into a data warehouse. In a typical ETL workload, the tool can connect to the source databases periodically and extract the data from those sources. Further, these extraction methods are either full or incremental loads, which means either the complete data from the source is loaded or only a changed portion of the data.
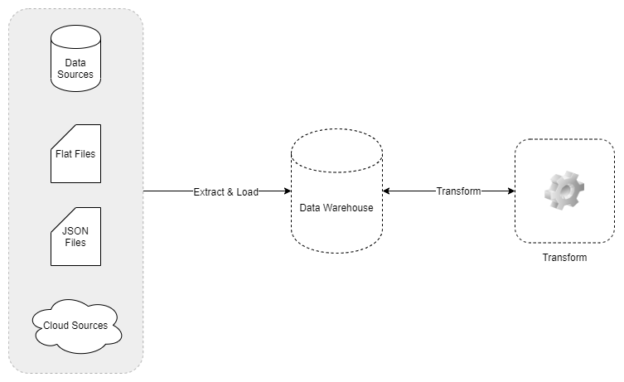
The figure below provides a graphical illustration of an ETL workload. Notice that the data is extracted from the sources and then transformed by the ETL tool in memory before being loaded into the warehouse.
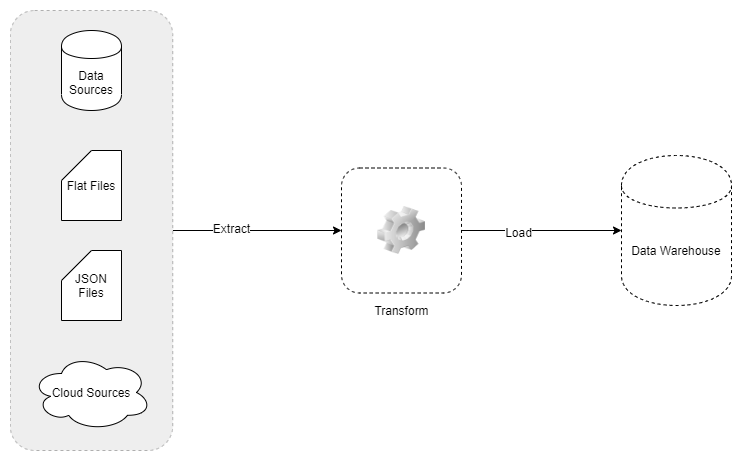
Figure 1 – Overview of ETL
ELT is another technique, where the data is extracted and loaded into the warehouse directly without any transformations. Once the extract and load process has been completed, the transformation logic is applied to the warehouse where the data is stored. This transformed data is then again loaded back into the warehouse from where reporting and other business decisions can be supported. In the later part of this article, I’ll sight why we would need to use this technique over the traditional ETL method that we have been using for so long and differentiate the features between ETL and ELT workloads.
In the figure below, the difference between ETL and ELT is clearly visible, as in this case, the data is extracted and loaded into the warehouse first and then transformed.
Figure 2 – Overview of ELT
Why do we need ELT?
The traditional method of using the ETL architecture is monolithic in nature, often used to connect only to schema-based data sources and they have very little or no room to process data flowing at very high speed. With the businesses dealing with high velocity and veracity of data, it becomes almost impossible for the ETL tools to fetch the entire or a part of the source data into the memory and apply the transformations and then load it to the warehouse.
In modern applications, we tend to have a variety of different data sources ranging from structured schema-based SQL sources to an unstructured NoSQL database. These different data sources rarely have any identical schema and each time a new source is added it becomes difficult or more time consuming to implement the logic in a traditional ETL tool.
An important factor that leads to the implementation of ELT systems is the adoption of the cloud data warehouses or data lakes by the organizations. An example of a cloud data warehouse is Azure Synapse Analytics (formerly known as Azure SQL Data Warehouse) or maybe Amazon RedShift. These cloud data warehouses have an MPP architecture (Massively Parallel Processing) and can be provisioned in very little time. Snowflake is also an example of a cloud data warehouse where all the infrastructure is managed, and customers need not worry about anything other than designing the business logic.
Also, these cloud data warehouses support the columnar store which is very helpful while analyzing large datasets with petabytes of data. In a columnar store, the data is stored by columns as opposed to the traditional method of row-wise data stores. In addition to this, cloud data warehouses are provisioned to run in multiple nodes with a combination of various RAMs and SSDs to support the high-speed processing of data. These are a few reasons which make a cloud data warehouse suitable for transforming and analyzing data on the fly without affecting the query performance.
Comparing ETL and ELT
|
ETL |
ELT |
|
|
Technology Adoption |
ETL has been in the market for over two decades now and is relatively easier to find developers who have vast experience in designing ETL systems. |
On the other hand, ELT is a new technology that is more focused on cloud-based warehouses. Searching suitable engineers to develop ELT pipelines are as easy as for ETL. |
|
Data Availability |
In an ETL workload, the data which is required only for analytics or reporting is being loaded into the warehouse, leaving other unnecessary data in the source systems as is. |
Whereas in an ELT system, we tend to load anything and everything into a warehouse or a data lake from where it can be analyzed at a later point of time. |
|
Calculated Fields and Transformations |
Yes, in ETL, we can add or remove specific columns while transforming the data in the ETL tool. We can also add calculated columns and load them to the warehouse. |
In ELT, additional columns are directly added to the existing dataset in the warehouse. Usually, there is no modification of the source columns. |
|
Transformation Complexities |
In an ETL workload, we can implement much complex data transformations as and when required. All these transformations occur in-memory. |
In an ELT workload, the more focus is given towards analyzing highly variable structured and unstructured data that is arriving at a high pace rather than complexities. |
|
Infrastructure |
Most of the traditional ETL tools need to be installed on-premises which incur a lot of cost to the analytics workloads. |
ELT, on the other hand, is mostly cloud-based and doesn’t require to be installed on the premises. |
|
Postproduction Maintenance |
In an ETL pipeline, that is installed on-premises, maintenance is frequently required. |
ELT, since it is cloud-based or serverless, no or very little maintenance is required. |
|
Transformation Area |
In an ETL pipeline, the transformations are applied in memory in a staging layer before the data is being loaded into the data warehouse. |
In ELT, the transformations are applied once the data has been loaded into the warehouse or a data lake. In this case, usually, there is no requirement for a staging layer unlike in the ETL. |
|
Support for semi-structured and unstructured data |
Although an ETL tool can read data from semi-structured or unstructured data sources, it is usually transformed in the staging layer and only stored as a proper structure in the warehouse. |
ELT is designed to handle all types of data structures from semi-structured to unstructured data in the data lakes which can be further analyzed. |
Example of ETL and ELT Workloads in Azure
Now that we have some idea about the comparisons between ETL and ELT, let us go ahead and see how a typical ELT workload can be implemented in Azure.
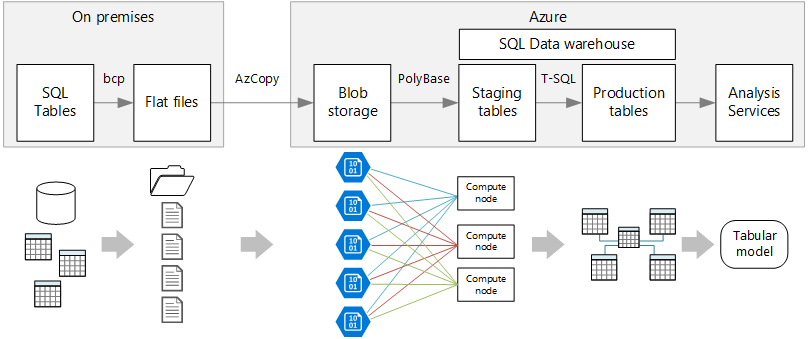
Figure 3 – ELT Workload in Azure (Source)
As you can see in the figure above, the on-premises data is first ingested into the blob storage which is a file system in the cloud and from there it is computed and stored in the SQL Data Warehouse for further analysis. To read more about this architecture, please follow the official documentation from Microsoft.
In the next figure, you can see how data is being imported from the various data sources and then ingested into the SQL Data Warehouse using Data Factory. Further, a semantic model is created using Azure Analysis Services and the data is visualized using Power BI.
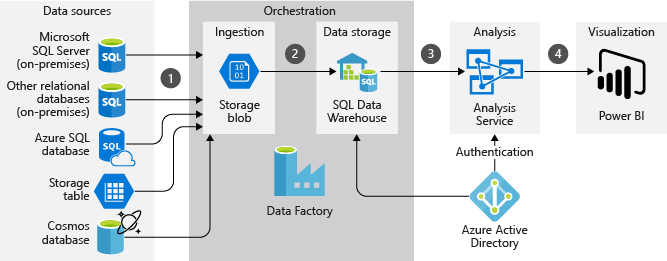
Figure 4 – ELT Tools in Azure (Source)
Conclusion
In this article, we talked about the main differences between ETL and ELT architecture. Data processing is an important operation for an organization, and it should be chosen carefully. Although there are a few differences between ETL and ELT, for most of the modern analytics workload, ELT is the most preferred option as it reduces the data ingestion time to a great extent as compared to the traditional ETL process. This helps organizations to make faster decisions and improvise analytical capabilities.

He is a prolific author, with over 100 articles published on various technical blogs, including his own blog, and a frequent contributor to different technical forums.
In his leisure time, he enjoys amateur photography mostly street imagery and still life. Some glimpses of his work can be found on Instagram. You can also find him on LinkedIn
View all posts by Aveek Das
- Getting started with PostgreSQL on Docker - August 12, 2022
- Getting started with Spatial Data in PostgreSQL - January 13, 2022
- An overview of Power BI Incremental Refresh - December 6, 2021