This article explores Row Sampling Transformations in SSIS and Percentage Sampling Transformations in SSIS packages
Read more »
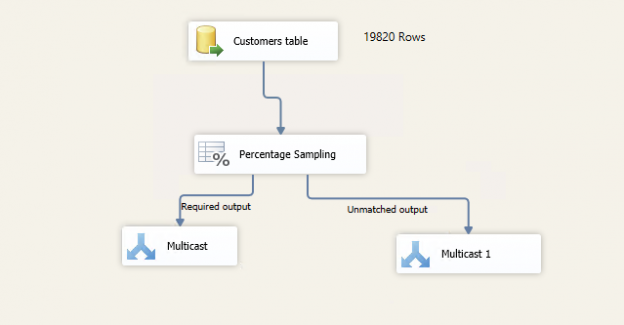
This article explores Row Sampling Transformations in SSIS and Percentage Sampling Transformations in SSIS packages
Read more »
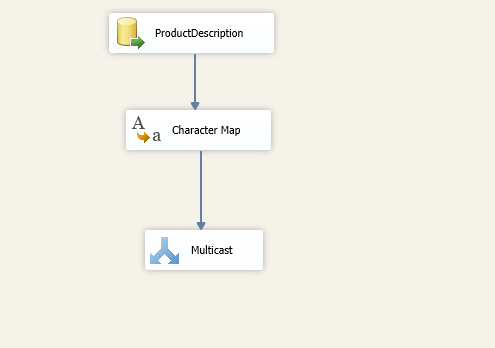
This article explores the Character Map Transformation in SSIS package with available configurations.
Read more »
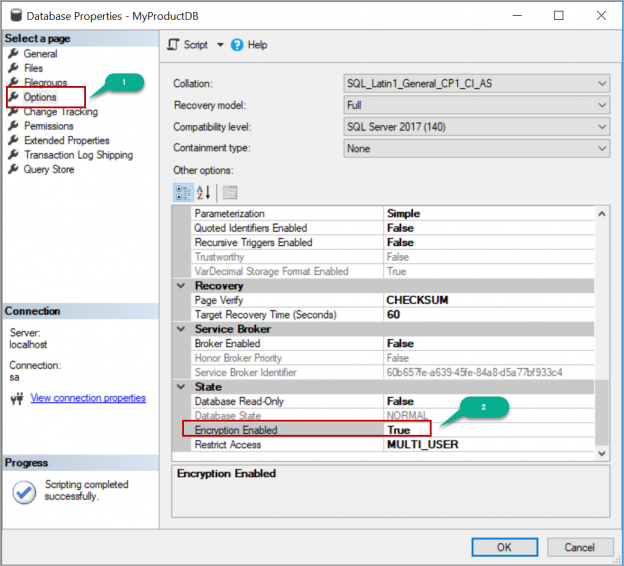
In this article, we will review how to enable Transparent Data Encryption (TDE) on a database in SQL Server and move the Transparent Data Encryption (TDE) enabled databases to a different server by restoring the backup.
Read more »

In this article, we will learn multi-statement table-valued functions (MSTVFs) basics and then we will reinforce our learnings with case scenarios.
Read more »

This article gives an overview of SQL UPPER function and SQL LOWER function to convert the character case as uppercase and lowercase respectively.
Read more »
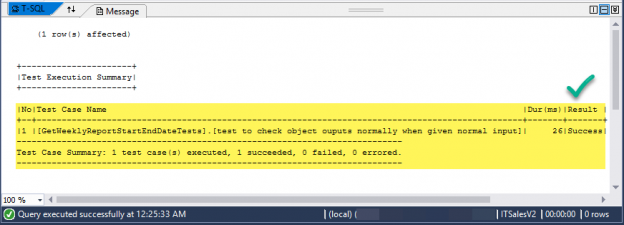
This article gives hands-on experience of writing basic utility procedures and creating their SQL unit tests using tSQLt an advanced SQL unit testing framework.
Read more »
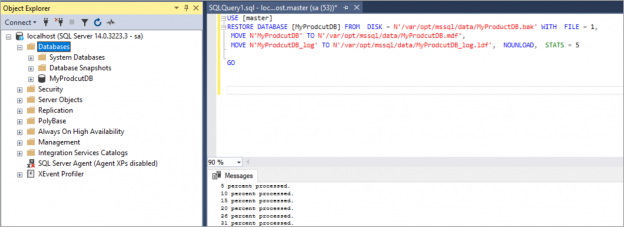
In this article, we will review how to create custom SQL Server docker images and run the containers from the custom images, upload the custom images to the docker hub.
Read more »
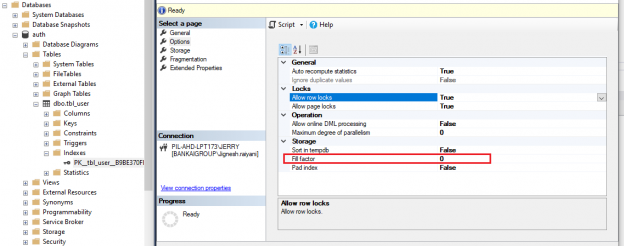
In this article, we will study in detail about the how SQL Server Index Fill factor works.
Read more »
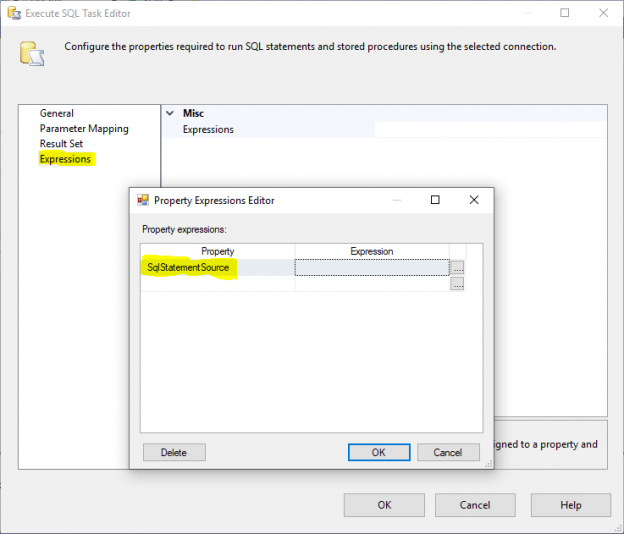
In this article, I will give an overview of Execute SQL Task in SSIS and I will try to illustrate some of the differences between writing an expression to evaluate SqlStatementSource property or writing this expression within a variable and change the Execute SQL Task Source Type to a variable.
Read more »

This article gives an overview of different editions in SQL Server and also explains the process to upgrade SQL Server editions.
Read more »
In this article, we will explore the process of SQL Delete column from an existing table. We will also understand the impact of removing a column with defined constraints and objects on it.
Read more »
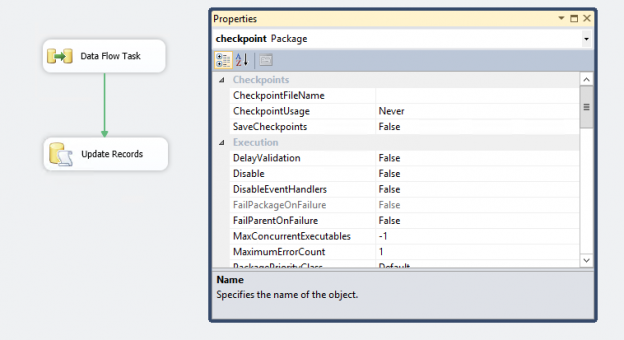
In the article, SQL Server CHECKPOINT, Lazy Writer, Eager Writer and Dirty Pages in SQL Server, we talked about the CHECKPOINT process for SQL Server databases. This article is about CHECKPOINT in SSIS package.
Read more »
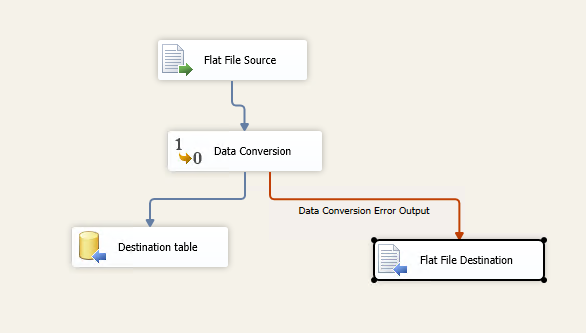
This article explains the process of configuring Error handling in SSIS package.
Read more »
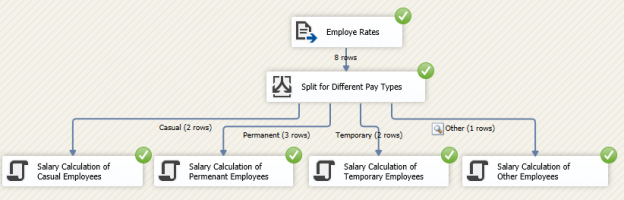
SQL Server Integration Services or SSIS is used as an ETL tool to extract-transform-load data from heterogeneous data sources to different databases. After extracting data from the different sources, most often there are a lot of transformations needed. One of the frequent transformations is SSIS Conditional Split.
Read more »
In this article, we’ll take a look at a brief TSQL history and a few examples of loops, conditionals, and stored procedures
Read more »
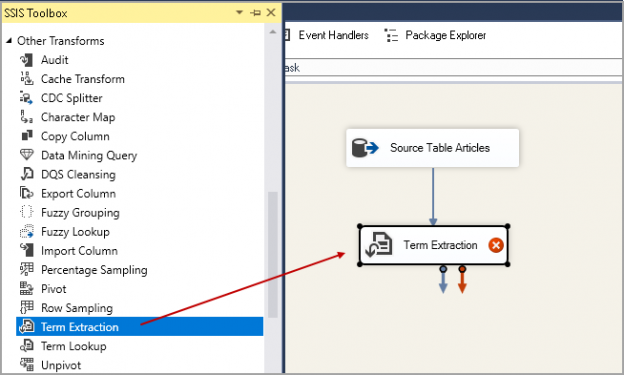
This article explores the Term extraction transformation in SSIS and its usage scenario.
Read more »
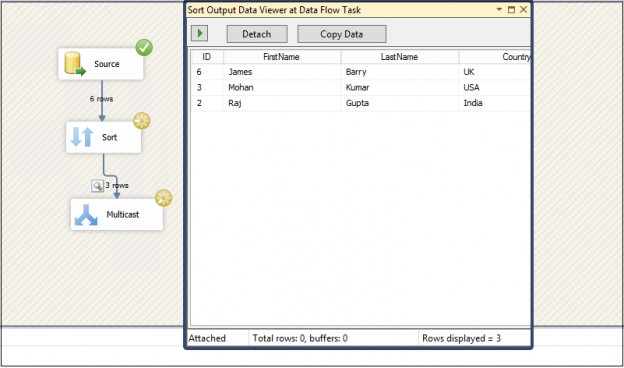
This article explains the process of performing SQL delete activity for duplicate rows from a SQL table.
Read more »
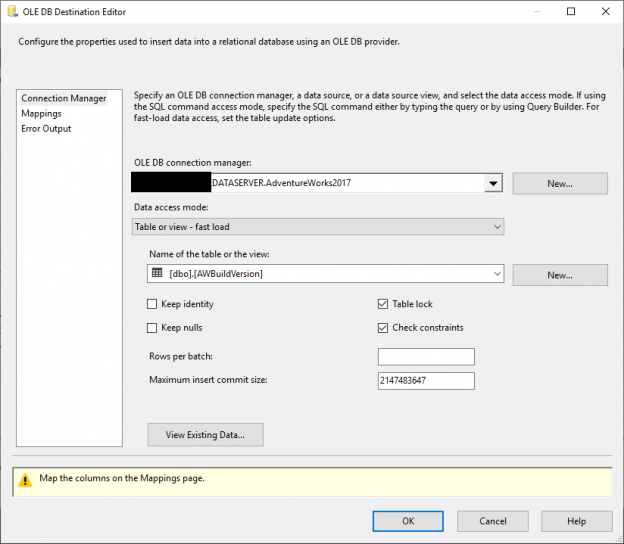
In this article, I will give an overview of SSIS OLE DB Destination and SQL Server Destination and I will try to illustrate some of the differences between both destination components based on my personal experience, SSIS official documentation and some other experts experience in this domain.
Read more »
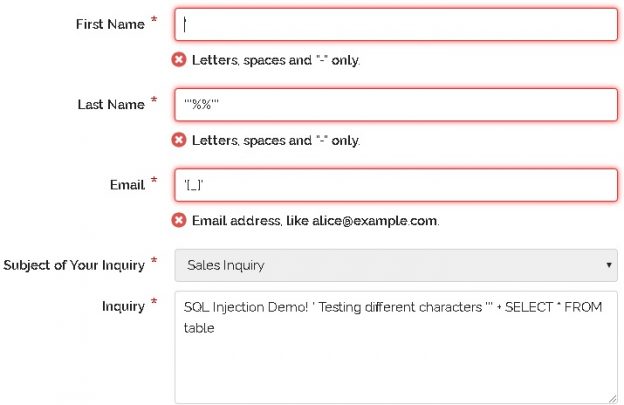
With an understanding of what SQL injection is and why it is important to an organization, we can shift into a discussion of how to prevent it. We ultimately want systems where SQL injection is impossible or very difficult to pull off. We then want systems where exploiting bugs is slow, laborious, and likely to raise monitoring alarms within an organization when attempted. The trio of layered security, prevention, and alerting can provide an immense advantage against not only SQL injection, but other data security threats.
Read more »
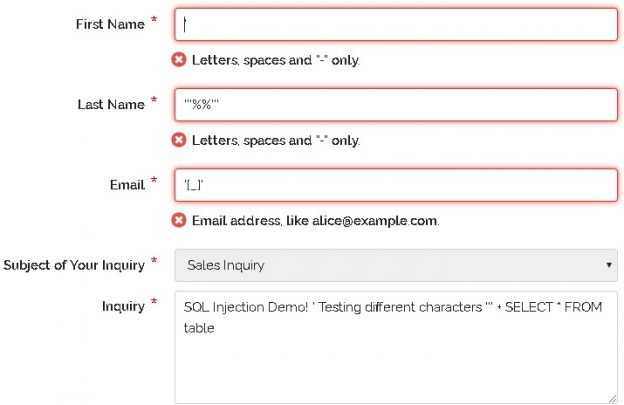
Many security vulnerabilities are discovered, patched, and go away forever. Some linger and continue to plague software development and will continue to do so for years to come. Setting aside social engineering and non-technical attacks, SQL injection remains one of the top security threats to our data, as well as one of the most misunderstood.
Read more »
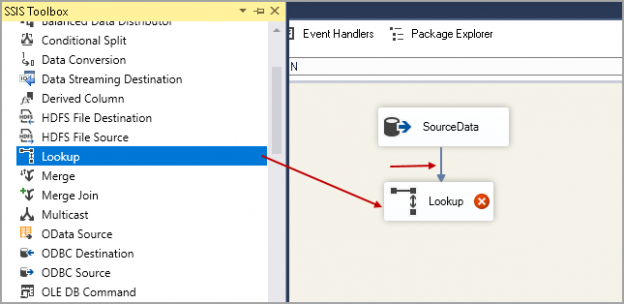
We will explore Lookup Transformation in SSIS in this article for incremental data loading in SQL Server.
Read more »
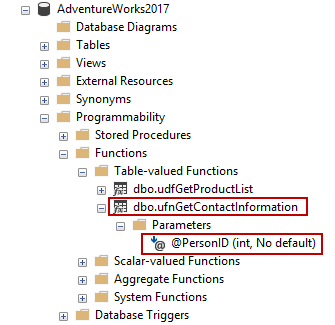
In this article series, we will find basics and common usage scenarios about the inline table-valued functions and we will also be consolidating your learnings with practical examples.
Read more »
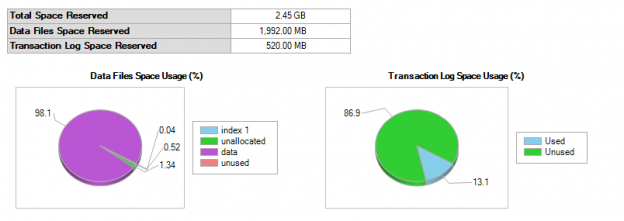
In this article, we will explore SQL Server ALTER TABLE ADD Column statements to add column(s) to an existing table. We will also understand the impact of adding a column with a default value and adding and updating the column with a value later on larger tables.
Read more »
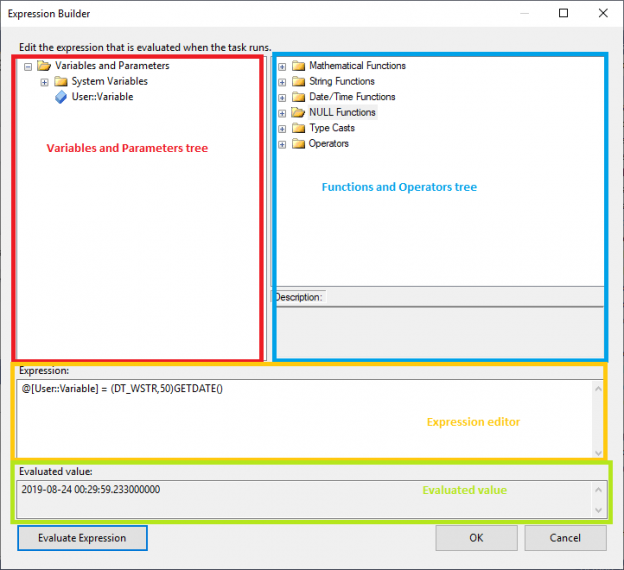
In this article, I will first give an introduction about SSIS expressions, then I will describe briefly the Expression Task and how to Evaluate a variable as expression. Then I will do a comparison between these two features to illustrate the similarities and differences between them.
Read more »
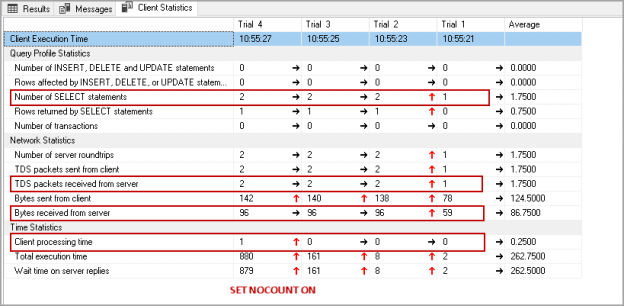
Have you ever noticed SET NOCOUNT ON statement in T-SQL statements or stored procedures in SQL Server? I have seen developers not using this set statement due to not knowing it.
Read more »© Quest Software Inc. ALL RIGHTS RESERVED. | GDPR | Terms of Use | Privacy