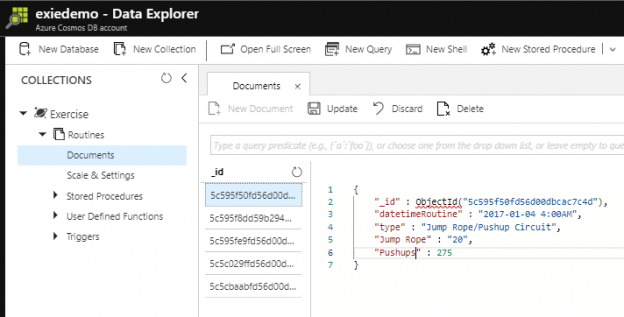
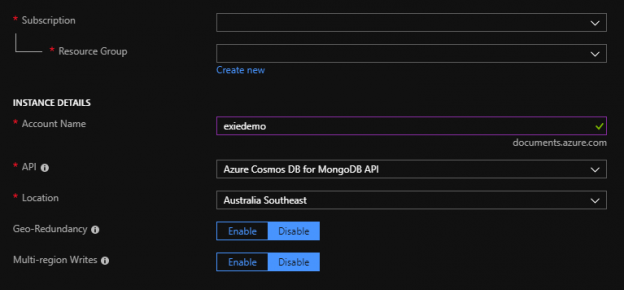
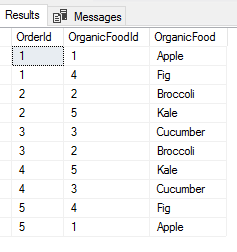
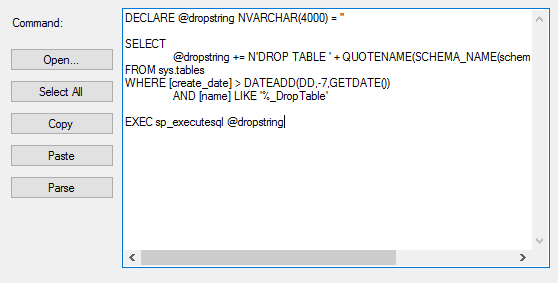
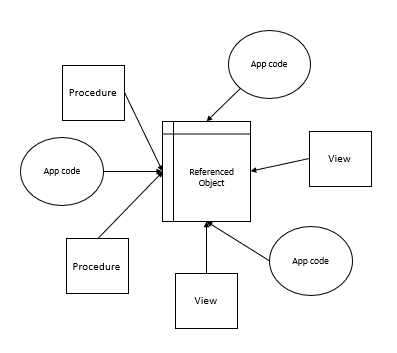
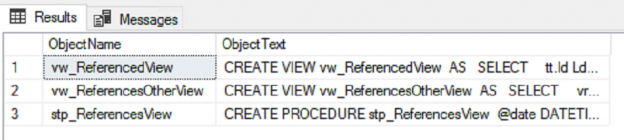
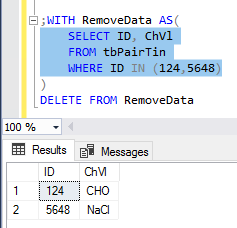
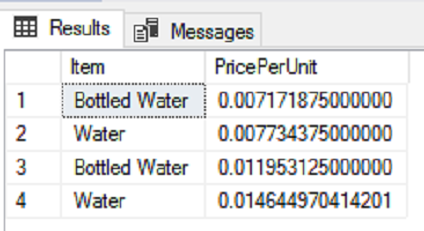
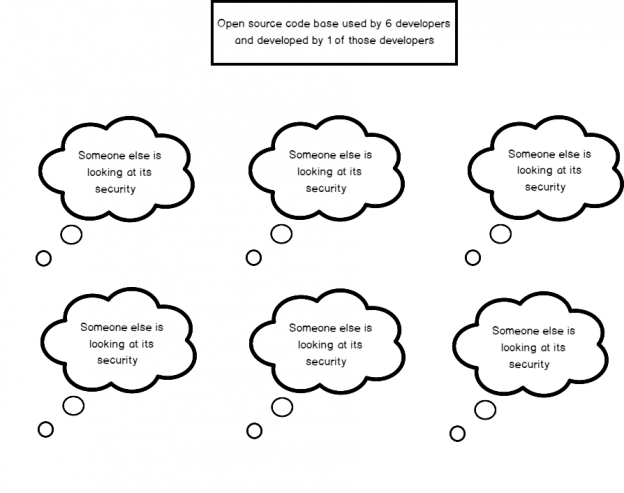
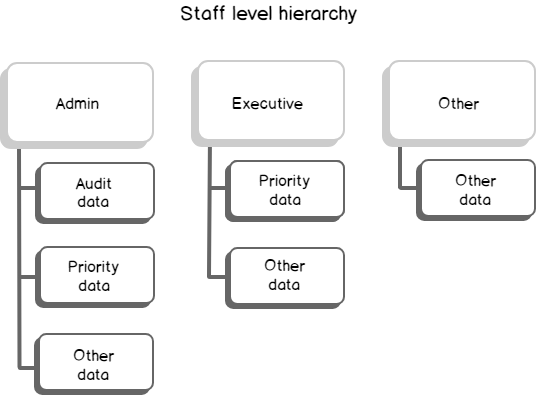
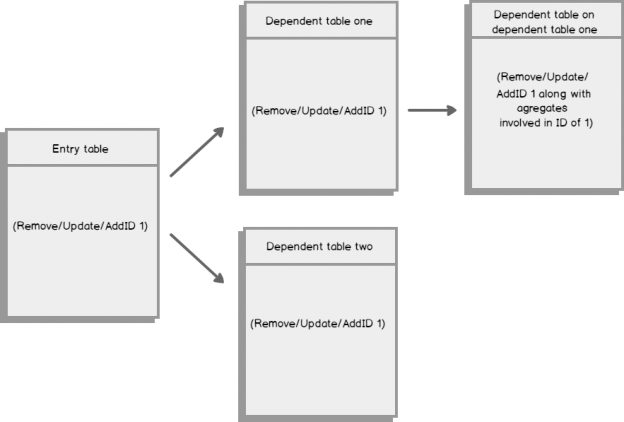
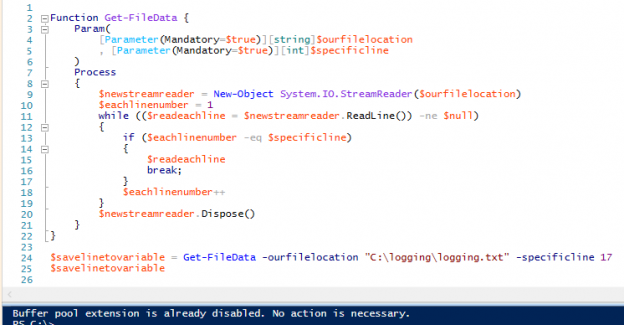
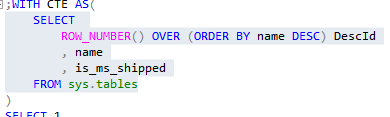
In the first part of this series Getting Started with Azure Cosmos DB, we looked at using Azure Cosmos DB for saving an individual’s fitness routine and why this database structure is better for this data than a SQL database while also showing that we still have to organize our structure like a file system organizes files. In this part of our series, we’ll begin looking at the terminology translation between NoSQL and SQL along with running updates for our documents and queries with filters that return some fields in our document, but not other fields.