
This article will cover SQL bulk insert operations deterministic outcomes and responses covering not allowing any bad data to allowing all data to be inserted, regardless of errors.
As we import data our data and migrate the data to feeds, applications, APIs, or other possible reports, we want to consider applying our business rules to our data as early as possible in our flow as possible. One of the main business rules that affects any data flow covers how we address errors during our data import and our rule for what we do with these errors. The cost of catching an error later in a flow can be enormous.
This helps increase performance and it also helps us catch errors early, which we can get further clarification in the case of a data vendor, or possibly avoid using the data in question. With SQL bulk insert we can enforce business rules early in our data flow to reduce resource usage and get results with our data.
3 Possible Data Scenarios Early In A Flow
Using the premise of “having no data is better than having bad data” (bad data here could be inaccurate or meaningless for our business context), we want to consider how we structure our data flow design in a manner that eliminates bad data as early as possible. We should consider three possible scenarios related to this as this step may involve one or more of the three scenarios.
- No bad data (errors) allowed: if a data point is invalid or meaningless for our business context out of an entire set, does it invalidate the entire set? For this scenario it would. This may be useful to us (see scenario three), but we would see this as an invalidation of the data set
- Error checks: are we using a data vendor (or source) we can contact if we find bad data following a SQL bulk insert? For this scenario, getting feedback quickly is key
- Keep all data: if we determine that data are invalid (in either scenario one or two), could we use this information? This also applies to situations where we identify errors in commonly used or well-respected data sources where we uncover inaccurate data that the vendor or source may not be aware of and we want this information because of other business reasons
Depending on our answers to the above questions, we may choose some options during our file load. For an example, if one bad data point invalidates an entire data set, we may choose to fail an entire transaction when the first failure is experienced by not specifying any errors allowed. Likewise, if we have strict rules, we also want to ensure that our table design and validation following our file load eliminates any data that don’t fit what we expect. Finally, we can use some of the features we’ve covered to even automate reading out to vendors.
Scenario 1: Allowing No Errors
In most cases, we want data without errors and preventing errors early in our data flow can save us time and prevent us from importing bad data. There are some rare situations where we may identify a bad data set and want to keep it (see point 3, which I cover in more details in a below section). In these situations, we want SQL bulk insert to limit the lowest possible we’ll allow – for our example purposes that will be zero (the default). Also, we want our table to have the exact structure of data that we expect from the file, so that any data that fail to comply to our business rules, fail the file insert.
In the below example, our SQL bulk insert allows no errors – any value in the file that does not match what we expect in our table will fail. Additionally, we don’t specify options like KEEPNULLs because we don’t want any null values. We’ll set a business rule that DataY must always be greater than DataX, which we’ll check in a query. Both values must also be numerical values between 0 and 101. Because of this business rule, we’re using the smallest whole integer for our columns in the table – tinyint – and following our insert, we’re filtering out any records that aren’t between 0 and 101. In addition, we look for records where DataX exceeds the value of DataY.
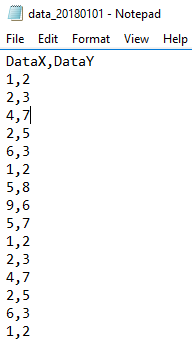
Our data file we’ll be using.
CREATE TABLE etlImport6( DataX TINYINT NOT NULL, DataY TINYINT NOT NULL ) BULK INSERT etlImport6 FROM 'C:\ETL\Files\Read\Bulk\data_20180101.txt' WITH ( FIELDTERMINATOR = ',', ROWTERMINATOR = '\n', FIRSTROW = 2 ) SELECT * FROM etlImport6 WHERE DataX > DataY OR DataX > 9 OR DataY > 9 OR DataX < 0 OR DataY < 0
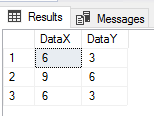
Three results fail our business rules.
From the table design to the specifications in SQL bulk insert to the following validation queries, we want to apply our business rules as strict as possible to filter out erroneous data points early. We can take this further by reducing part of our where clause and steps, assuming storage is not a concern. In the below code, we execute the same steps, except our table structure limits us to decimal values of 1 whole digit only, meaning -9 to 9 will be allowed.
CREATE TABLE etlImport6_Strict( DataX DECIMAL(1,0) NOT NULL, DataY DECIMAL(1,0) NOT NULL ) BULK INSERT etlImport6_Strict FROM 'C:\ETL\Files\Read\Bulk\data_20180101.txt' WITH ( FIELDTERMINATOR = ',', ROWTERMINATOR = '\n', FIRSTROW = 2 ) SELECT * FROM etlImport6_Strict WHERE DataX > DataY OR DataX < 0 OR DataY < 0
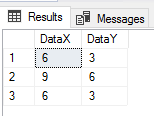
Three results still fail our business rules.
The data type tinyint costs less (1 byte), but allows a broader range. Our decimal specification is strict – throwing an arithmetic overflow if we go over, even at a slightly higher storage cost. We see that between strict SQL bulk insert specifications, table design and queries, we can reduce the number of steps to ensure that we have our data correct as early as possible in our data flow.
Scenario 2: SQL Bulk Insert with Error Checks
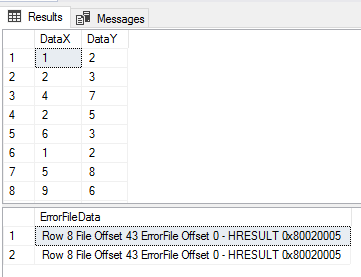
We’ll now look at a scenario that applies if we have a contact source when we experience errors and we want to quickly determine more details about these errors. In my experience with finding errors in data where there is a contact source, the fastest way to get information is to have the bad data that you can send quickly. In our example, we’ll actually be using a feature of our tool – its ability to generate an error file and insert the error files data for reporting, such as an email that can be send to us with the vendor copied in if any errors are experienced. Using the same file, we’ll add an X,Y value in the file (row 8), which we see doesn’t match our required format and we’ll have this error logged and imported.
CREATE TABLE etlImport6Error( ErrorFileData VARCHAR(MAX) ) ---- Clear from previous example TRUNCATE TABLE etlImport6 BULK INSERT etlImport6 FROM 'C:\ETL\Files\Read\Bulk\data_20180101.txt' WITH ( FIELDTERMINATOR = ',', ROWTERMINATOR = '\n', FIRSTROW = 2, MAXERRORS = 100, ERRORFILE = 'C:\ETL\Files\Read\Bulk\data_20180101' ) BULK INSERT etlImport6Error FROM 'C:\ETL\Files\Read\Bulk\data_20180101.Error.txt' SELECT * FROM etlImport6 SELECT * FROM etlImport6Error
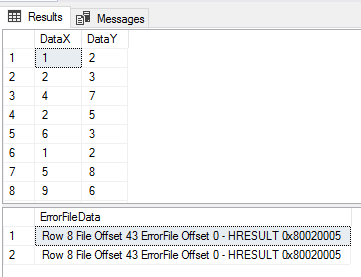
We have the errors saved in the eltImport6Error table for quick access to get details.
DECLARE @message VARCHAR(MAX) = 'We uncovered the below errors in the file data_20180101.txt:
' SELECT @message += '' + ErrorFileData + '
' FROM etlImport6Error IF LEN(@message) > 0 BEGIN SELECT @message EXEC msdb.dbo.sp_send_dbmail @profile_name = 'datasourceOne' , @recipients = 'vendor@vendorweuse.com' , @body = @message , @subject = 'Errors found' END
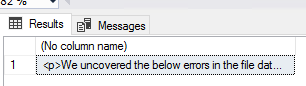
Output of the email that will be sent.
The above design calls SQL bulk insert twice – once to get the file’s data and the second time to insert the errors. With this etlImport6Error table, we then send an email alert (or we could use the query for a report to send) to our vendor about details. Our business rules fundamentally will determine whether it’s worth contacting the vendor due to errors. I would suggest keeping this process as quick as possible, as trying to manually keep a list of errors will consume extra time. This assumes that our business requirements expect us to get insight into data like these.
Scenario 3: Allowing Any Data (Including Inaccurate Data)
In some cases, we want to allow anything when we insert a file’s data. Since we know that having no data is better than having some data, this means that an inaccurate source of data can tell us information about the source, industry, or other related information if we identify errors, especially if the source of data is commonly used. For these cases following a SQL bulk insert, we want to keep the data for reports and analysis even if we know the file has bad data since the purpose is not to use as a data source, but determine if we can see these data being used.
CREATE TABLE etlImport6_Allow( DataX VARCHAR(MAX), DataY VARCHAR(MAX) ) BULK INSERT etlImport6_Allow FROM 'C:\ETL\Files\Read\Bulk\data_20180101.txt' WITH ( FIELDTERMINATOR = ',', ROWTERMINATOR = '\n', FIRSTROW = 2 ) SELECT * FROM etlImport6_Allow ---- Failure: Conversion failed when converting the varchar value 'X' to data type tinyint. SELECT CAST(DataX AS TINYINT) , CAST(DataY AS TINYINT) FROM etlImport6_Allow ---- Tracking records SELECT * FROM etlImport6_Allow WHERE DataX NOT LIKE '[0-9]' OR DataY NOT LIKE '[0-9]'
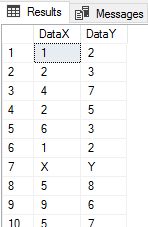
Our table is designed to allow any inconsistency.

Post insert, we’ve found an error in our data.
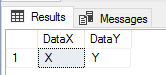
We uncover the records that don’t match.
When we look at the results, we see everything from the file and since the varchar maximum specification will allow up to 2 gigabytes of information, it’s unlikely that our load will fail due to space reasons. We may also specify smaller column sizes, if we don’t expect to have extreme values – like a varchar of 500. After our insert into our varchar columns, when we try to convert the data to what we would expect – tinyints – we get a conversion error. From here, we can use a strict search for records using numerical patterns to identify the records that aren’t numbers.
Generally, if we are going to apply allowing anything in our environment from a file source for the reasons of tracking this information, this will occur after we identify a faulty data source. This is a sequential step from one of the first steps, such as running the SQL bulk insert in our first section, finding our source is erroneous, and realizing that this finding may help our business. From a business perspective, this can be very useful. Faulty data sources can help us predict events in our industry, so if we discover a faulty data set, we may want to keep aggregates, summaries, or even the entire data set.
Conclusion
Businesses can have different rules for data and the context and industry can matter. I’ve imported thousands of data sets and these three scenarios can apply to any file source – some businesses have different rules for the same data sets that other businesses have different rules. As we see with SQL bulk insert, we can use it with a combination of data structures for any of these scenarios.
Table of contents
| T-SQL’s Native Bulk Insert Basics |
| Working With Line Numbers and Errors Using Bulk Insert |
| Considering Security with SQL Bulk Insert |
| SQL Bulk Insert Concurrency and Performance Considerations |
| Using SQL Bulk Insert With Strict Business Rules |

He has spent a decade working in FinTech, along with a few years in BioTech and Energy Tech.He hosts the West Texas SQL Server Users' Group, as well as teaches courses and writes articles on SQL Server, ETL, and PowerShell.
In his free time, he is a contributor to the decentralized financial industry.
View all posts by Timothy Smith
- Data Masking or Altering Behavioral Information - June 26, 2020
- Security Testing with extreme data volume ranges - June 19, 2020
- SQL Server performance tuning – RESOURCE_SEMAPHORE waits - June 16, 2020