
We manage data in a growing environment where our clients query some of our data, and on occasion will query past data. We do not have an environment that scales and we know that we need to archive some of our data in a way that allows clients to access it, but also doesn’t interfere with current data clients are more interested in querying. With the current data in our environment and new data sets will be using in the future, what are some ways we can archive and scale our environment?
Overview
With large data sets, scale and archiving data can function together, as thinking in scale may assist later with archiving old data that users seldom access or need. For this reason, we’ll discuss archiving data in a context that includes scaling the data initially, since environments with archiving needs tend to be larger data environments.
Begin with the end in mind
One of the most popular archiving techniques with data that includes date and time information is to archive data by a time window, such as a week, month or year. This provides a simple example of designing with an end in mind from the architectural side, as this becomes much easier to do if our application considers the time in which a query or process happens. We can scale from the beginning using the time rather than later migrating data from a database. Consider the below two scenarios as a comparison:
- Scenario 1: We add, transform and feed data to reports from a database or set of databases. The application and reports point to these databases. When we need to archive data, we migrate data in the form of inserts and deletes from these databases to another database where we store historic data. If a user needs to access historic data, the queries run against this historic environment.
- Scenario 2: We add, transform and feed data to reports from multiple databases (or tables) created by the time window from the application in which the data are received (or required for clients) and stored for that time, such as all data for 2017 being stored in a 2017 database only. Because there’s a time window, the databases do not grow like in Scenario 1. The time window for this database (or table structure) determines what data are stored and no archiving is necessary, as we can simply backup and restore the database on a separate server if we need to migrate the data.
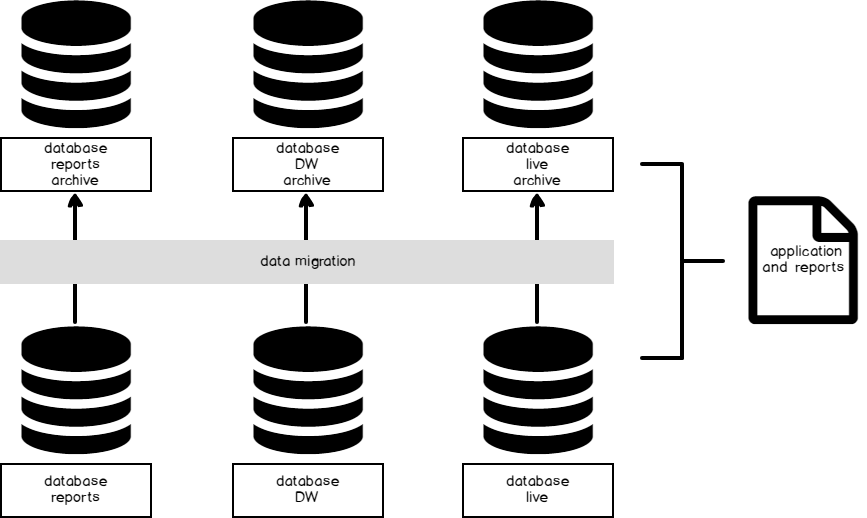
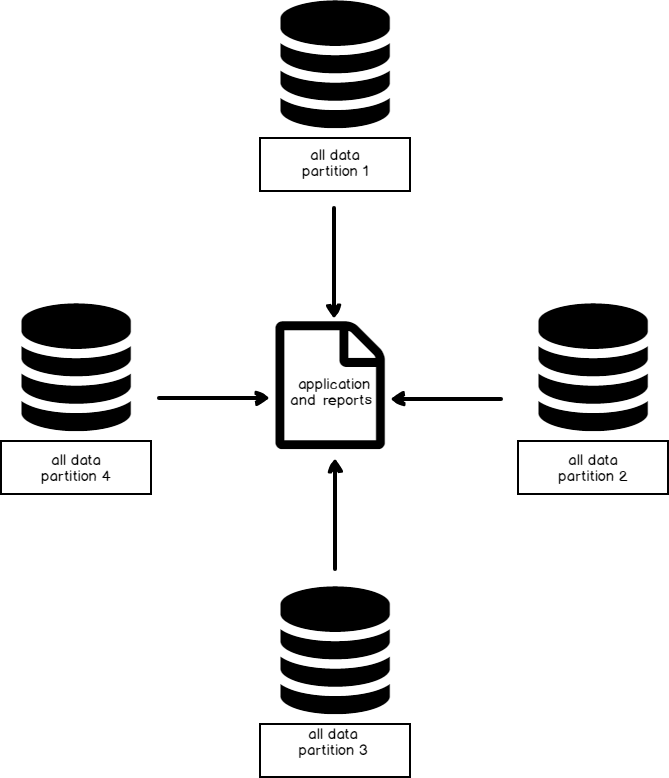
Data feeds
When we consider the end use of our data, we may discover that modeling our data from feeds will help our clients and assist us with scale. Imagine a report where people select from a drop-down menu the time frame in which they want to query data – whether in years, months or days. Behind the scenes, the query determines what database or databases are used (or tables, if we scale by tables). We treat the time in this case as the variable that determines the feed, such as 2017 being the data feed for all from the year of 2017.
We can apply this to other variables outside of time, such as an item in a store, a stock symbol, or a geographical location if we prefer to archive our data outside of using time. For instance, geographical data may change in time (often long periods of time) and feeding data for the purpose of archiving and scaling by region may be more appropriate. Stocks symbols also provide another example of this: people may only subscribe to a few symbols and this can be scaled early as separate feeds from different tables or databases. Archiving data becomes easier since each symbol is demarcated from others and reports generate faster for the user.
Our data feeds solve a possible scaling problem and resolve the question of how to archive historic data that may need to be accessed by clients.
Deriving meaningful data
We may be storing data that we are unable to archive, or that querying and application use limit our ability to migrate data. We may also be able to archive data, but find that this adds limitations, such as performance limitations or storage limitations. In these situations, we can evaluate using data summaries through deriving data to reduce the amount of data stored. Consider an example with loan data where we keep the entire loan history and how we may be able to summarize these data in meaningful ways to our clients. Suppose that our client’s concern involves the total number of payments required on a loan, the total number of payments that’s currently happened, the late and early payments, and the current payment streak. The below image with a table structure is an example of this that summarizes loan data:

Relative to what our client needs, this may offer a meaningful summary that eliminates our need to store date and time information on the payments. Using data derivatives can save us time, provided that we know what our clients want to query and we aren’t removing anything they find meaningful. If our clients want detailed information, we may be limited with this technique and design for scale, such as using a loan number combination for scale in the above example.
The 80-20 rule for archiving data
In most data environments, we see a Pareto distribution of data that clients query where the distribution may be similar to the 80-20 rule or another distribution: the majority of queries will run against the minority of data. Historic data tends to demand fewer queries, in general, though some exceptions exist. If we are limited in scaling our data from the beginning to assist with automatic archiving and we’re facing resource limitations, we have other options to design our data to with frequency of access in mind.
- We will use resource saving techniques with data that clients don’t query often, such as row or page compressions, clustered column store indexes (later versions of SQL Server), or data summaries.
- If we only have the budget for fewer servers, we’ll scale less-accessed data to servers with fewer resources while retaining highly-accessed data on servers with many resources.
- Finally, in situations where we are very restricted by resources, we can use backup-restore techniques for querying, such as keeping old data on backups by copying the data quickly to a database, backing up the database, and keeping it on file for restoring. Since this will slow the querying down if the data are necessary, as the data must first be restored, we would only use this option in environments where we faced significant resource limitations. The below example with comments shows the steps of this process using one table of data that is backed up and restored by a time window.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
---- First we copy our data we'll archive to another database SELECT * INTO Data2017.dbo.tblMeasurements FROM tblMeasurements ---- The where clause would specify the window of data we want to archive - in this case on year WHERE YEAR(DateMeasurement) = '2017' ---- We backup the database for later restore, if data are needed BACKUP DATABASE Data2017 TO DISK = 'E:\Backups\Data2017.BAK' ---- For a report, we would restore, query, and drop RESTORE DATABASE Data2017 FROM DISK = 'E:\Backups\Data2017.BAK' WITH MOVE 'Data2017' TO 'D:\Data\Data2017.mdf' , MOVE 'Data2017_log' TO 'F:\Log\Data2017_log.ldf' ---- Report Query SELECT MONTH(DateMeasurement) MonthMeasure , AVG(Measurement) AvgMeasure , MIN(Measurement) MinMeasure , MAX(Measurement) MaxMeasure FROM tblMeasurements GROUP BY MONTH(DateMeasurement) ---- Remove the database DROP DATABASE Data2017 |
This latter example heavily depends on the environment’s limitations and assumes that clients seldom access the data stored. If we’re accessing the data frequently for reports, we would move it back with the other data we keep for frequent access.
References
- Partitioning data in SQL Server using the built-in partition functions
- Enable Compression on a Table or Index
- Copy all data in a table to another table using T-SQL (very useful in automating data delineated backups)

He has spent a decade working in FinTech, along with a few years in BioTech and Energy Tech.He hosts the West Texas SQL Server Users' Group, as well as teaches courses and writes articles on SQL Server, ETL, and PowerShell.
In his free time, he is a contributor to the decentralized financial industry.
View all posts by Timothy Smith
- Data Masking or Altering Behavioral Information - June 26, 2020
- Security Testing with extreme data volume ranges - June 19, 2020
- SQL Server performance tuning – RESOURCE_SEMAPHORE waits - June 16, 2020