
In CTEs in SQL Server; Querying Common Table Expressions the first article of this series, we looked at creating common table expressions for select statements to help us organize data. This can be useful in aggregates, partition-based selections from within data, or for calculations where ordering data within groups can help us. We also saw that we weren’t required to explicitly create a table an insert data, but we did have to ensure that we had names for each of the columns along with the names being unique. Now, we’ll use our select statements for inserts and updates.
Development styles with Inserts, Updates and Deletes
Outside of environments that use all three SQL CRUD operations (inserts, updates and deletes), there are two predominant development styles with these write operations that are useful to know when we consider common table expressions and write operations:
- Remove everything and reload: in SQL Server, this can be achieved through the use of the truncate plus insert operations. If designed in a horizontally scaled manner, this can provide the fastest route for new data with only a small amount of updated data (or no updated data)
- Never delete, only add and update: this is the soft delete or soft transaction approach where records aren’t removed, but updated to be inactive. This removes the delete operation, but can add in storage and performance costs since data are never removed
These are the other popular combinations along with environments that use all three write CRUD operations. What’s important to consider relates to how inserts, updates and deletes fundamentally function and what this means for performance:
- Inserts add data from a data set, whether that data set is a file, table, variable, hard-coded value, or other data. This can be all the data from that data set or a subset of the data. Relative to design (new records versus adding records between existing records), inserts can be a light write operation
- Updates change existing data either in full or in partial from other information, whether a data source or a data variable. Relative to the space with existing data and the update performed, this can be costly in fragmentation, in the data source that is used as a reference, etc. Common table expressions may reduce our likelihood of reversing an update, which can be very costly in some cases
- Deletes remove existing partial data from sets. I will assume here that anyone wanting to remove all data from a table will use a truncate to reduce logging (though there may be reasons truncate is avoided). Deletes therefore inherently use a select in that they remove partial data and the removal may create extra space among existing records in storage along how deletes mark records in the transaction log
The reason these points are important is that we can optimized write operations for the best performance, but we can’t out-optimize their inherent design. If we have to remove 100 records against a table that will cause fragmentation because of how our records are organized, no common table expression or subquery will subvert the minimum cost required by the transaction. We can use this tool for helping us reduce the cost to as close to minimum, but each write operation will come with costs.
Inserts with SQL CTEs
Generally, many insert transactions do not require significant complexity outside of transformations or validation. For this reason, I will rarely use any common table expression, subquery or temp table structure with insert transactions. If I use any of these three tools with inserts, the query almost always meets the following criteria:
- The insert requires
organization of data on top ofnew structure or added structure. An example of this would be a query that has data partitioned by year that then needs the totals and average for the year. The data partitioned would be the new structure on top of the data, and the aggregates would be the organization on top of that new structure - The insert comes from a query that involves analysis of comparing data sets or comparing values where the organization of the values occurs before comparison. An example of this would be a join of two tables by a value that must be derived from a query, such as getting the year from a date field to join tables
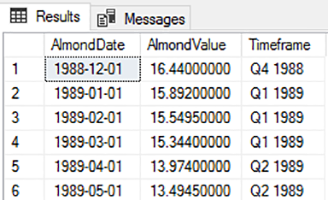
The above scenarios tend to be more common in data warehouse (OLAP) environments and like with other transactions, we have alternatives that may be more appropriate. For an example of an insert with common table expressions, in the below query, we see an insert occur to the table, reportOldestAlmondAverages, with the table being created through the select statement (and dropped before if it exists).
IF OBJECT_ID('reportOldestAlmondAverages') IS NOT NULL
BEGIN
DROP TABLE reportOldestAlmondAverages
END
;WITH GroupAlmondDates AS(
SELECT
YEAR(AlmondDate) AlmondYear
, AlmondDate
, AlmondValue
FROM tbAlmondData
WHERE AlmondDate < '1990-12-31'
), GetAverageByYear AS(
SELECT
AlmondYear
, AVG(AlmondValue) AvgAlmondValueForYear
FROM GroupAlmondDates
GROUP BY AlmondYear
)
SELECT t.AlmondDate
, tt.AvgAlmondValueForYear AnnualAvg
, (t.AlmondValue - tt.AvgAlmondValueForYear) ValueDiff
INTO reportOldestAlmondAverages
FROM GroupAlmondDates t
INNER JOIN GetAverageByYear tt ON t.AlmondYear = tt.AlmondYear
SELECT * FROM reportOldestAlmondAverages
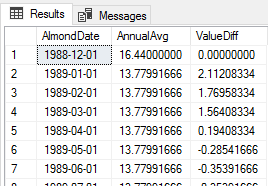
Our created report table from the two CTEs joined.
The CTE in SQL Server offers us one way to solve the above query – reporting on the annual average and value difference from this average for the first three years of our data. We take the least amount of data we’ll need to use in our first common table expression, then get the average in our next, and join these together to return our report.
The above insert statement also illustrates a development technique that we should apply to all data operations – filter as early as possible and use as little as required with data. We don’t want aggregates being run against a full table, if we only want to run an aggregate for a small timeframe. While SQL CTEs can make development easy, there is a tendency to get everything early, then filter later (this is also common with other data operations too). The better development technique is to filter as strict as possible early so that we return the fewest data points we need, from unnecessary rows to unnecessary columns. This especially becomes true if we migrate data to another server and our query is involved in a linked server query.
Like with other transactions including select statements, the data from the wrapped query inside the parenthesis is inserted, meaning if the wrapped query has 100 records, 100 records will be inserted unless a where excludes them (the actual columns are determined by what is selected).
Updates with SQL CTEs
We can use common table expressions to update data in a table and this becomes very intuitive when we do updates with JOINs. Similar to other operations, we will use a wrapped select for the data we want to update and the transaction will only run against the records that are a part of the select statement. We’ll first look at a simple update, then look at the easy of doing a joined update.
In the below example, we first add a column to our table that allows 9 varchar characters and we use a SQL CTE to update all the records in our table to a blank value (previous records were null values). Following what we’ve learned in inserts and selects, we only select what we want to update and nothing more – we always want to get in the practice of returning the least amount of data we need (both for performance and security). Once we add our column and update our records to blank, we can used the wrapped query inside the common table expression to check our blank values.
ALTER TABLE tbAlmondData ADD Timeframe VARCHAR(9) ;WITH UpdateAll AS( SELECT Timeframe FROM tbAlmondData ) UPDATE UpdateAll SET Timeframe = ''
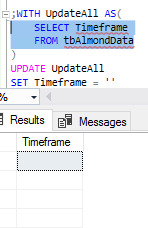
We can run a validation after we run the update by highlighting the query inside the SQL CTE.
If I had specified top 10 or had added a where clause for only 10 values, the update would have only run against those 10 values. This becomes incredibly useful to limit the scope of updates with our select statement inside the SQL CTE specifying the exact records to update.
Next, we’ll create a quarter table that we’ll use for an update CTE in SQL Server, with a join and insert four records. For our update, we’ll join our tbAlmondData to our newly created QuarterTable on the quarter part of the AlmonddDate (we could run this update by using the DATEPART function alone, but this example will also show how we can use a join statement to make updating easy with SQL CTEs). We want our new timeframe column to hold the value of QN YYYY, such as Q1 1989. For our select statement inside the common table expression, we’ll select our Timeframe column (which will need to be updated) as well as the varchar combination of QuarterValue and casted year of our AlmondDate column as a varchar of size four. We can check how the existing Timeframe column and how the NewTimeframe column look before we run the update.
CREATE TABLE QuarterTable(
QuarterId TINYINT IDENTITY(1,1),
QuarterValue VARCHAR(2)
)
INSERT INTO QuarterTable
VALUES ('Q1')
, ('Q2')
, ('Q3')
, ('Q4')
;WITH UpdateTimeframe AS(
SELECT
t.Timeframe
, tt.QuarterValue + ' ' + CAST(YEAR(AlmondDate) AS VARCHAR(4)) NewTimeframe
FROM tbAlmondData t
INNER JOIN QuarterTable tt ON tt.QuarterId = DATEPART(QUARTER,t.AlmondDate)
)
UPDATE UpdateTimeframe
SET Timeframe = NewTimeframe
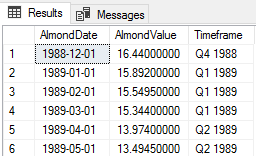
Using the joined query, we update our timeframe column.
If we needed to update one column that would be created from three joined tables, we could apply the same logic in the above query – join our data in the wrapped select statement with the existing record and the new record we need to update the existing record to, then run our updates. Not only does this allow us to run a quick check before we make an update – because we can select and run the wrapped query – it means we can use the intuitive design of joins when updating data with selects. In a similar manner, by choosing CTE names that capture what we’re doing and using column names that indicate the existing versus new, the SQL CTE itself explains the update with little confusion.
Conclusion
We see that we can quickly create insert and update statements with common table expressions and organize our data easily. We can combine these with other development techniques, such as temp tables or transaction-based queries, to simplify our troubleshooting if we experience issues. Like with large select statements, SQL CTEs may have drawbacks if we stack too many of them on each other, as we won’t have the convenient ability to query the wrapped data. In addition, we may still find situations where we don’t want to use these, as they don’t offer the best performance.
Table of contents
| CTEs in SQL Server; Querying Common Table Expressions |
| Inserts and Updates with CTEs in SQL Server (Common Table Expressions) |
| CTE SQL Deletes; Considerations when Deleting Data with Common Table Expressions in SQL Server |
| CTEs in SQL Server; Using Common Table Expressions To Solve Rebasing an Identifier Column |

He has spent a decade working in FinTech, along with a few years in BioTech and Energy Tech.He hosts the West Texas SQL Server Users' Group, as well as teaches courses and writes articles on SQL Server, ETL, and PowerShell.
In his free time, he is a contributor to the decentralized financial industry.
View all posts by Timothy Smith
- Data Masking or Altering Behavioral Information - June 26, 2020
- Security Testing with extreme data volume ranges - June 19, 2020
- SQL Server performance tuning – RESOURCE_SEMAPHORE waits - June 16, 2020