

When we develop security testing within inconsistent data volume situations, we should consider our use of anti-malware applications that use behavioral analysis. Many of these applications are designed to catch and flag unusual behavior. This may help prevent attacks, but it may also cause ETL flows to be disrupted, potentially disrupting our customers or clients. While we may have a consistent flow of data throughout a time period – allowing for a normal window of behavior to occur – we may also have an inconsistent data schedule or inconsistent amount of data that cause these applications to flag files, directories, or the process itself.
When Anti-Malware causes report outage
In many environments, security testing involves checking for possible vulnerabilities against attack. In one example I had to investigate, the testing overlooked significant changes in data load and extract volumes that were possible. The assumption was that these loads and extracts would happen within a data range (such as “within 500GB per day”), but it only took one exceptional day to cause the anti-malware application to flag the load before the extract. The result of this was an outage with reports. It’s possible that we’re not checking for legitimate process ranges in our testing and this can be costly in the same manner as a breach in some contexts. In this case, the solution for future security testing required resources and time to improve the possible range of data volume during extracts and loads.
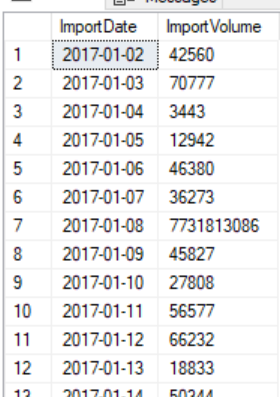
An example of inconsistent data loads daily showing the date and volume of data that can complicate security testing and prevention
Identifying data volume ranges
If we’ve seen this issue or if this may be a possible issue, we want to prevent it through tracking our data volume ranges in each environment. This means that following an extract or load, we want to track the amount of data – whether we want to use row counts, data size, etc. When we review this on reports, we want to know the average data volume and the maximum data volume. Consider that we may have an extract data volume of 100,000 records for 700 days consistently, then one day we have an extract data volume of 1,500,000 records. That one data point would not be enough to affect the average, but it may be flagged by anti-malware because it’s unusually high (this is similar in structure to the incident I reviewed). Depending on these numbers, we may want to review how we’re security testing for a possible false flag with anti-malware.
In the below script, we create a table for identifying data volume ranges over time and we include the environment in this table, as there may be variance in environments that we want to know about ahead of time. Because aggregates will generally be used when querying this table and new records will be infrequently added, I create it with a clustered columnstore index. We may use other derivatives of this table, such as storing the data size in gigabytes; the key is tracking how often we get unusually large extracts or loads, the size of these large extracts or loads, and whether our security testing will pass these situations.
|
1 2 3 4 5 6 7 |
CREATE TABLE tbLoads( Environment VARCHAR(15), LoadDate DATETIME, DataVolume BIGINT ---- Replacement could be SizeInGB ) CREATE CLUSTERED COLUMNSTORE INDEX CCI_tbLoads ON tbLoads |
When environments differ
In some circumstances, we may have a development and QA environment that does not match the data volume of our production environment. In the below image from a query comparing data volumes across environments, we see a comparison between an average QA environment load and production environment load. Notice the extreme deviation from the average (measured by maximum data load divided by average data load) – production’s largest deviation from its average was seven multiples, while QA was 2 multiples:
|
1 2 3 4 5 6 7 |
SELECT Environment , AVG(DataVolume) AvgLoad , (MAX(DataVolume)/(AVG(DataVolume))) MaxLoadDivByAvg FROM tbLoads GROUP BY Environment ORDER BY AVG(DataVolume) DESC |
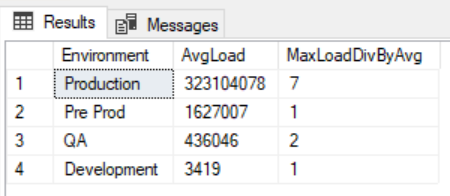
In this example, our security testing in QA would not catch the possible data volume range that would exist in production
This may give us false positives in our security testing if anti-malware software is involved because it may not flag our extracting or loading in development due to a low data range volume but flags it in production. It’s the production cost of an outage we want to avoid. The technique we can use in testing is to match the extreme range in our data volume that may exist in production. If production may have a data load that is seven multiples of the average load, we should duplicate the same type of multiple for development and QA. We must remember that it’s not the amount of data, but the range of data volume from the maximum load (or extract) to the average.
Possible solutions
We will build our ETL flows around possible solutions that keep our environment protected while allowing legitimate data flow to occur. For these situations, we may do one or more of the following:

(Example) Some anti-malware applications may allow us to exclude some file paths for scanning.
- Waive the folder path or specific file (if named consistently) for our ETL extracts and loads – including in our security testing environment, if the anti-malware allows for this option. We would want other monitoring to ensure that nothing outside extracts and loads occurs though
- Determine the size of the extract, or load before importing or exporting, if we can determine this information and intervene if necessary (or automate an intervention if possible). Unfortunately, this may not assist us if the file is flagged due to size when the file source submits it
- Allow for more flexibility on the server if the scheduled time is consistent. This would be an ideal time to attack though, so this may only be appropriate with other techniques or in some situations
- Allow the increased security measures from the anti-malware (file or path flagging) and delay the reports – an appropriate technique in environments where security is the highest priority. Keep in mind that unless our ETL is inconsistent, a flagged operation may be malware
- Perform “false” extracting and loading in all environments (including production) and with our security testing to ensure that our data flow covers the possible range of volume (trains the anti-malware on what may be normal)
- Delineate our ETL extract and load server or servers where these have no anti-malware application. This would only be appropriate in environments where security is less of a concern
Attackers will often perform reconnaissance on a target before attacking so that they understand their target before they attack. This means that patterns like allowing folder paths, time flexibility, etc. may be discovered ahead of time.
Summary
Anti-malware applications can provide us with tools to prevent attacks or identify attacks. However, in large data volume environments with inconsistent extracting or loading, they may add complexity if they flag legitimate data functionality. Our security testing should involve identifying where this may occur and how we can prevent and work-around this while being cautious about what our solution may involve. While we want to ensure our data flow, we also want to be careful that we don’t open our environment to attacks.

He has spent a decade working in FinTech, along with a few years in BioTech and Energy Tech.He hosts the West Texas SQL Server Users' Group, as well as teaches courses and writes articles on SQL Server, ETL, and PowerShell.
In his free time, he is a contributor to the decentralized financial industry.
View all posts by Timothy Smith
- Data Masking or Altering Behavioral Information - June 26, 2020
- Security Testing with extreme data volume ranges - June 19, 2020
- SQL Server performance tuning – RESOURCE_SEMAPHORE waits - June 16, 2020