
From troubleshooting many data flow applications designed by others, I’ve seen a common pattern of over complexity with many designs. Putting aside possible risks by introducing too much complexity, troubleshooting these designs often involves opening many different applications – from a notepad file, to SSIS, to SQL Server Management Studio, to a script tool, etc. It may sound like many of these are doing a hundred steps, yet many times, they’re simply importing data from a file, or calling five stored procedures and then a file task of moving a file. This complexity is often unnecessary, as is opening many different tools when we can use a few tools and solve issues faster.
In this part one of this series, we’ll look at a few of the options that we can specify when using BULK INSERT that may reduce our need to use other tools that introduce complex troubleshooting or involve opening multiple applications that aren’t needed. While there may be a time and place to use many tools for one task, we should take opportunities to reduce complexity if complex designs aren’t required or if the requirements allow for reduced tool use.
Bulk Insert Basics With and Without Delimiters
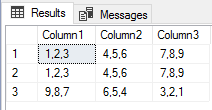
If we’re importing data from a flat file, we may find that bulk insert provides us with a useful tool that we can use for importing the data. We’ll start with entire files that have no delimiters. In the below code snippet, we insert a SQL file of data (in this case, a query) and we’ll notice that we don’t specify any delimiters for rows or columns. The query below the code shows the result – all the data enter one column and one row, as our table is set to handle this amount of data (varchar-max can store up to 2GB of data).
|
1 2 3 4 5 6 7 8 |
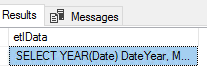
CREATE TABLE etlImport1( etlData VARCHAR(MAX) ) BULK INSERT etlImport1 FROM 'C:\ETL\Files\Read\Bulk\dw_query20180101.sql' SELECT * FROM etlImport1 |
One column and one row of data from the file we inserted.
We insert a SQL file of data, but we could have inserted a wide variety of files, such as text, configurations, etc. Provided that we don’t specify a delimiter for a row or column and the file is within the size allowed, bulk insert will add the data. If our table had a varchar specification of 1, the bulk insert would fail. We’ll see this example next – inserting the same file again in a new table that specifies a varchar of 1 character:
|
1 2 3 4 5 6 |
CREATE TABLE etlImport2( etlData VARCHAR(1) ) BULK INSERT etlImport2 FROM 'C:\ETL\Files\Read\Bulk\dw_query20180101.sql' |

We see a truncation error because the file’s data exceeds the length allowed in the table.
We will typically be inserting delimited files where characters specify new rows and columns. Delimiters can vary significantly from characters of the alphabet to special characters. Some of the most common characters in files that delimit data are commas, vertical bars, tab characters, new line characters, spaces, dollar or currency symbols, dashes, and zeros. When we specify row and column delimiters, we use the two specifications of FIELDTERMINATOR for the column delimiter and ROWTERMINATOR for the row delimiter. In the below file, our column delimiter is a comma while our row terminator is a vertical bar: our file will be a 3 column, 3 row table when inserted.
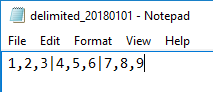
Our example delimited file where commas specify new columns (FIELDTERMINATOR) and vertical bars specify new rows (ROWTERMINATOR).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
CREATE TABLE etlImport3( Column1 VARCHAR(1), Column2 VARCHAR(1), Column3 VARCHAR(1) ) BULK INSERT etlImport3 FROM 'C:\ETL\Files\Read\Bulk\delimited_20180101.txt' WITH ( FIELDTERMINATOR = ',' ,ROWTERMINATOR = '|' ) SELECT * FROM etlImport3 |
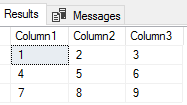
The results of our bulk insert with commas as the column delimiters and vertical bars as the row delimiters.
We’ll notice a couple of patterns:
- Our table is designed to only allow 1 character in each column. If the file had a comma-delimited column of 2 or more characters, we would get a truncation error like the one we saw above this. In some cases, developers will prefer to insert any data followed by cleaning the data. In other cases, developers will prefer to have errors thrown if the data don’t match the expectation
- If we have marked vertical bars as the column delimiter (FIELDTERMINATOR), we’d get the truncation error because our first column would be 1,2,3 (5 characters) and that exceeds the varchar of 1. Still, we could specify a vertical bar as the column delimiter, as the delimiters may be any number of characters, but we need to ensure that our table definition matches what we find in the file
In our next step, we’ll create a new table with three columns that has a varchar of 5 characters allowed and we’ll use the same file in our previous example, except we’ll specify vertical bars as the column delimiter without specifying a row delimiter (as this would exceed our file size).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
CREATE TABLE etlImport4( Column1 VARCHAR(5), Column2 VARCHAR(5), Column3 VARCHAR(5) ) BULK INSERT etlImport4 FROM 'C:\ETL\Files\Read\Bulk\delimited_20180101.txt' WITH ( FIELDTERMINATOR = '|' ) SELECT * FROM etlImport4 |
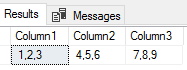
Our bulk insert shows three columns delimited by the vertical bar.
Since our columns in our new table support the length, we see the values inserted. But what would happen if we didn’t have the correct column alignment? We’ll look at this by adding a z character for a new row, but in our second row, only have one column of data 9,8,7 and try inserting it into the same table.
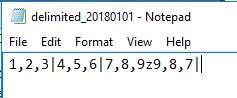
Our file has 3 columns in the first line, but the new line has 1 column (the new line starts at character z).
|
1 2 3 4 5 6 |
BULK INSERT etlImport4 FROM 'C:\ETL\Files\Read\Bulk\delimited_20180101.txt' WITH ( FIELDTERMINATOR = '|', ROWTERMINATOR = 'z' ) |

We get an error indicating that an end of file was reached, but this doesn’t match the expected format.
As we see, our bulk insert experiences an abrupt end of line that doesn’t match the expected format of our table – even though the table expects three columns, the last line has one and ends. This error is thrown without any data being inserted. To get around this error, we need three columns in every line of data that matches our table format. Let’s correct this by adding 2 more columns of data so that our file’s column number matches the table specifications:
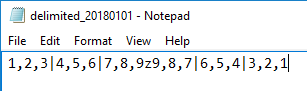
Our file now has 2 rows with 3 columns each.
|
1 2 3 4 5 6 7 8 |
BULK INSERT etlImport4 FROM 'C:\ETL\Files\Read\Bulk\delimited_20180101.txt' WITH ( FIELDTERMINATOR = '|', ROWTERMINATOR = 'z' ) SELECT * FROM etlImport4 |
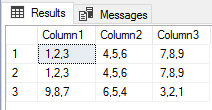
We see the first insert from the former exercise and the next two rows of our updated file.
While we’re looking at a small file in this case – a file with 2 rows of data – these errors will help when you see them in a file with millions of lines and the delimited format doesn’t match. We can prevent bulk insert from throwing an error and terminating though, which we’ll do as an exercise, but if we don’t specify anything further, the expected behavior of bulk insert will be to throw an error without inserting data.
We’ll add a new line of data to our file with the sentence of “Thisline|is|bad” after the z character that specifies a new line. We see that the sentence does match the character length in the first column even though it has the correct number of column delimiters.
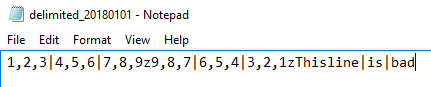
The added line of data does not match the requirements in the third row.
Instead of failing, we’ll have bulk insert add as much data as it can before it experiences an error. In the below code, we first truncate our table to empty it, bulk insert the data by allowing an error, and selecting from our table:
|
1 2 3 4 5 6 7 8 9 10 11 |
TRUNCATE TABLE etlImport4 BULK INSERT etlImport4 FROM 'C:\ETL\Files\Read\Bulk\delimited_20180101.txt' WITH ( FIELDTERMINATOR = '|', ROWTERMINATOR = 'z', MAXERRORS = 1 ) SELECT * FROM etlImport4 |

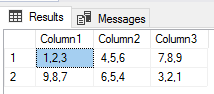
We see an error, but see that the two valid records were inserted.
We get the first two rows of data and we see the failure from bulk insert because the first column in the third row exceeds the varchar character limit of 5. Relative to the format of the file (valid delimiters, even if the specifications may be wrong), we may still be able to pass on a few errors. We still wouldn’t get around an error if the file had lines that didn’t match the expected column number format (like the above example where a line of data has no delimiters when a number are expected). Do we always want to pass on a few errors and get all the data from a file? It depends on the context, though as a general rule, I view bad data as much more of a concern than no data, so I tend to keep bad data out of a table and review the file if an error is experienced. This may not be appropriate in all data contexts.
Summary
We’ve looked at using bulk insert for inserting an entire file of data, which may be useful in some contexts like storing configuration or code files for resource management and we’ve seen that we can store up to 2GB of data using the varchar maximum specification. We’ve also looked at inserting delimited data by specifying new columns and new rows and we’ve seen failures if a file doesn’t match this format. We’ve also looked at how to overcome some errors by specifying a maximum error amount that allows bulk insert to continue even if an error is experienced.
Table of contents

He has spent a decade working in FinTech, along with a few years in BioTech and Energy Tech.He hosts the West Texas SQL Server Users' Group, as well as teaches courses and writes articles on SQL Server, ETL, and PowerShell.
In his free time, he is a contributor to the decentralized financial industry.
View all posts by Timothy Smith
- Data Masking or Altering Behavioral Information - June 26, 2020
- Security Testing with extreme data volume ranges - June 19, 2020
- SQL Server performance tuning – RESOURCE_SEMAPHORE waits - June 16, 2020