
In this article, we are going to talk about discovering and archiving SQL references to invalid procedures.
We have a significant amount of database code within our database procedures we no longer use, as we’ve changed objects referenced in procedures. As we’ve moved to source control for all of our databases, we’re seeing the costs of keeping old code in our environment that we no longer use. The trouble is that we don’t know how to identify what we use since we have many teams who develop objects in our databases and use them for the features they create. What are some techniques for cleaning old database code on the database level as well as preventing this problem in the future?
Overview
Outside of the storage costs and repository costs where we must sync with many objects, old database code in the form of stored procedures that we no longer use raises security risks, as procedures provide access to data through CRUD operations. If we don’t use database code, we should practice eliminating it immediately. It is a major security risk to have stored procedures that are no longer used. As for functions, this depends on the function in question, but I recommend the practice of only keeping what’s required. We can apply the same lessons to views, users, roles, etc as well – the more database objects we use, the more we need to restrict or eliminate as we change our environment.
For the best practice to reduce effort, if we replace a database object with another object (such as replacing an old procedure with a new procedure), we should remove the old object immediately. We can archive the old object for SQL reference in an archive source control location, but we should never keep the object live. This best practice will prevent a database from possessing objects that are no longer used but could possibly reveal inappropriate information to a malicious actor.
Demonstration with A Stored Procedure
In the below code, we create a table that we’ll use for an experiment. Once we create the table, we create a procedure that inserts a record from a parameter the procedure accepts into our newly created table. We then test the procedure a few times, query the table, then drop the table. Now, when we execute the stored procedure, we get an error – the procedure fails. As we see in the below code, we can remove a table that’s referenced in a procedure.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
--- Window 1 CREATE TABLE DataEntry( TextId TINYINT IDENTITY(1,1), TextEntry VARCHAR(9) ) --- Window 2 CREATE PROCEDURE addDataEntry @string VARCHAR(9) AS BEGIN INSERT INTO Dataentry (TextEntry) VALUES (@string) END EXEC addDataEntry 'ref-1' EXEC addDataEntry 'ref-2' EXEC addDataEntry 'ref-3' EXEC addDataEntry 'ref-4' EXEC addDataEntry 'ref-5' SELECT * FROM DataEntry DROP TABLE DataEntry EXEC addDataEntry 'ref-6' |
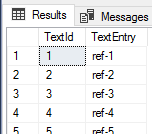
Our query shows the results of the data we added.

We can remove the table, but now when we call the procedure, the procedure fails since the table doesn’t exist.
This may be one of the complexities that we’re solving for: an invalid SQL reference where an object refers to another object that no longer exists. This scenario could also be a procedure calling another procedure with the second procedure not existing.
Identifying SQL References Before a Drop
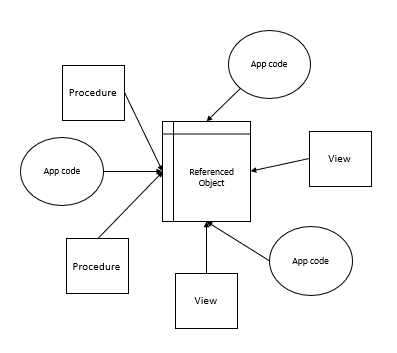
One clear solution here is to identify all references prior to dropping the referenced object and the same applies if we rename the object. Using the above example of removing a table, we could look for all the references to the table we’re dropping in our procedures, views, etc. This code becomes invalid if they reference the removed object and removing them with it reduces possible errors. There may be cases where we want to update the reference if we’ve renamed the object or created a new object to replace the old one. The flow of removing an object should be to identify references first and include these references as objects to be removed if we need to remove an object. The below diagram shows this.
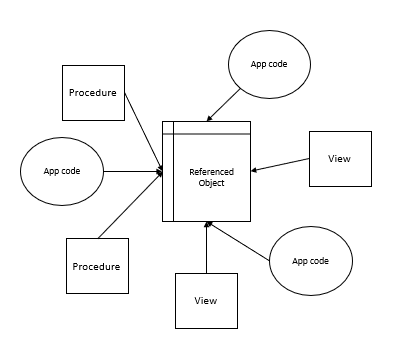
Using the above image as an example, if we remove the referenced table, notice the impact it would cause on all the other references to the table – they would be invalid.
The same logic applies to other changes from renaming objects to changing data types to changing primary keys (which should be extremely rare, but unfortunately happen). These changes can have significant effects on code that reference these. We must account for all dependent code which will be affected prior to making the change.
Assuming that we use source control for our database – from database objects to application code – we can iterate over our files using PowerShell and obtain SQL references. We’ll want to use searches that reflect how we name objects; notice the nuances in the below select statements for one table – all of which return the same data set, but query the table differently:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
SELECT * FROM etlMidLoader SELECT * FROM dbo.etlMidLoader SELECT * FROM [dbo].etlMidLoader SELECT * FROM [dbo].[etlMidLoader] SELECT etlMidLoader.* FROM [dbo].[etlMidLoader] SELECT [etlMidLoader].* FROM [dbo].[etlMidLoader] |
Developers sometimes name tables the same name as column names, so searching for a table name may return results you don’t want to see, such as returning a column from a table you don’t want to remove or update. I tend to develop with the approach of restricting most object names (tables, views, procedures, etc) with a starting identifier either indicating the object type or purpose (tb or etl) or using the action it performs (helpful for views or procedures) and the reason is that searches through source control become fast as I never get a column and table clash. One of the best DBAs I worked with enforced this rule by removing any object that didn’t follow appropriate naming convention immediately without warning – it made developers create objects with the right name from the beginning and saved time when tracking down dependencies (this also saved a lot of time for other tracking purposes). However, this assumption would be inappropriate in many development environments because many environments don’t have strict practices like this.
In the below code, we look for the object etload in our source control by filtering on SQL files exclusively (our assumption here being that we’re using SQL for references) and we return the file name plus the line of the file we found it along with the line of text. This script is not procedure-biased either unless we only point it at a directory that holds procedures (relative to design); it will search all SQL files for references. Even comments should be reviewed, as it’s a common practice by developers to use multi-line comments. Relative to how specific we want our filter, we can edit the if statement in the below code to be very specific with regular expressions.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
Function Read-ForSpecificText { Param( [Parameter(Mandatory=$true)][string]$file , [Parameter(Mandatory=$true)][string]$objectpattern ) Process { $readfile = New-Object System.IO.StreamReader($file) $identifylineno = 0 while (($fileline = $readfile.ReadLine()) -ne $null) { if ($fileline -match “$objectpattern”) { Write-Output (‘”’ + $file + ‘” ‘ + $identifylineno.ToString() + “: “ + $fileline) } $identifylineno++ } $readfile.Close() $readfile.Dispose() } } $sourcecodesql = Get-ChildItem “C:\Src\Repo One\Reposins\” -Filter *.sql -Recurse foreach ($sqlfile in $sourcecodesql) { Read-ForSpecificText -file $sqlfile.FullName -objectpattern “etlload” } |

We see three objects reference our table with the filenames and the line numbers of the files.
What we do in cases like this may be to alter the objects and remove the SQL reference, or archive the objects first – if we want to keep these even if the etlload table has been removed – and then alter the objects.
Because some environments will write SQL code directly in their middleware or frontend code, this script can expand to those file extensions, such as .cs, etc.
Refreshing the Stored Procedure
While removing referenced objects along with their references is the best practice as we can immediately prevent this issue from the beginning, if we’re in a situation where we need to remove objects that may be invalid, we can use T-SQL’s built-in sql_dependencies, which can assist us in some situations. If we use the above example for our stored procedure that references a table we’ll see the effects of the results when we query this when the table exists and when it doesn’t:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
--- Before drop SELECT t2.[name] ProcedureName , t3.[name] ReferenceName FROM sys.sql_dependencies t1 INNER JOIN sys.procedures t2 ON t1.object_id = t2.object_id INNER JOIN sys.objects t3 ON t1.referenced_major_id = t3.object_id WHERE t2.[name] = 'addDataEntry' --- After drop SELECT t2.[name] ProcedureName , t3.[name] ReferenceName FROM sys.sql_dependencies t1 INNER JOIN sys.procedures t2 ON t1.object_id = t2.object_id INNER JOIN sys.objects t3 ON t1.referenced_major_id = t3.object_id WHERE t2.[name] = 'addDataEntry' |
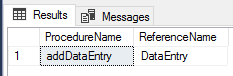
The results before we drop the DataEntry table.
The results after we drop the DataEntry table
We may be tempted to write a query from the above tables where we find no references, but in some cases, stored procedures may not reference any tables and this may be valid. In the same manner, a stored procedure may call dynamic code inside it, which would make our assumptions invalid (whereas the PowerShell script would catch this). For an example, let’s create a procedure with dynamic SQL that references our table:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
CREATE PROCEDURE addDataEntryDyn AS BEGIN EXEC('INSERT INTO Dataentry (TextEntry) VALUES (''String'')') END --- Recreate the table: CREATE TABLE DataEntry( TextId TINYINT IDENTITY(1,1), TextEntry VARCHAR(9) ) --- Call our new procedure EXEC addDataEntryDyn --- Query our table SELECT * FROM DataEntry --- No references? SELECT t2.[name] ProcedureName , t3.[name] ReferenceName FROM sys.sql_dependencies t1 INNER JOIN sys.procedures t2 ON t1.object_id = t2.object_id INNER JOIN sys.objects t3 ON t1.referenced_major_id = t3.object_id WHERE t2.[name] = 'addDataEntryDyn' |
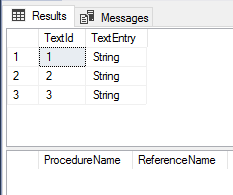
No references found.
Developers will sometimes call CRUD operations in this way, so we have to be careful in assuming that we’ll catch everything related with this query.
Conclusion
Part of creating software involves working with dependent code where an object, like a stored procedure or view, references another object, such as a table. As we fix bugs and update our software, we may remove objects that cause failures or invalid SQL references. We also may lose code that’s valuable for future reference (thus my recommendation of archiving it some way). These invalid references, errors, or calls can introduce possible bugs along with possible security risks. The best practice is to catch references as early as possible, as it’s the easiest time to remove or update references if an object must be removed.
References
SQL Dependencies, which may be removed in a future version of SQL Server
How to find unused stored procedures
Best practices of working with procedures from Microsoft
.NET’s StreamReader exercises for reading files
Finding invalid references in views (SQLShack)

He has spent a decade working in FinTech, along with a few years in BioTech and Energy Tech.He hosts the West Texas SQL Server Users' Group, as well as teaches courses and writes articles on SQL Server, ETL, and PowerShell.
In his free time, he is a contributor to the decentralized financial industry.
View all posts by Timothy Smith
- Data Masking or Altering Behavioral Information - June 26, 2020
- Security Testing with extreme data volume ranges - June 19, 2020
- SQL Server performance tuning – RESOURCE_SEMAPHORE waits - June 16, 2020