
When we’re developing solutions, we can sometimes forget useful commands we can use in T-SQL that make it convenient to remove data, eliminate objects, or carefully remove data. We look at three of these commands with a few examples of where we might consider using them in development, or in rare production cases. While they may offer us speed and convenience in some cases, we also look at some situations where they may not be the best tool to use.
Truncating a table over deleting every row from the table
Deleting data can be one of the most expensive DML operations and while we must do it in some situations such as deleting some records in a table, we do have an alternative with truncate if we need to remove every record in a table without each row removal being logged. In development, we will often have more freedom to truncate a table when we need to remove all rows, which will help us over using delete.
In practice, one situation where deletes and truncates can be compared is transactional replication where we’ve defined a rule that on a reset, we want to remove every row of data in the destination table and repopulate the data from the source, as a load of inserts in our situation will perform better than updates (if the situation has much fewer updates than inserts, this would not be true). If we don’t want each row elimination tracked in the transaction log, a delete operation before repopulating the data becomes expensive, whereas a truncate operation does not. In this example, we’re still assuming a few things to prefer truncates over deletes or drop, re-creates and inserts:
- We’re removing all the data in the destination table.
- Our source schema never changes in a manner that will impact the destination table. If this were to occur, we would want to either drop and recreate or make sure that we’re allowing DDL changes to pass.
- We don’t want a logged record for every row elimination on the destination table.
While this command can be helpful in many situations involving development or full refreshes of a table, we should not use (or may be unable to use) the truncate command in some situations, such as the following:
- When we only want to remove a subset of our data from a table. The truncate command will remove every row of data in the table.
- When we want the individual row removals logged, such as tracking these removals in CDC even if we’re removing all the rows. If row removals from a table impact other row removals from another table, the command must be passed to the next table. We can use truncate here only if the second table contains the exact same data, otherwise, we’ll have to use delete. While truncate table faster because it does not use the transaction log in the exact same manner that deletes uses, this means we lose references to removals if we need only some removals of a full table to pass to another table.
- When we want to remove all data from a table that are referenced by a foreign key, which holds true for the removal of referenced data.
- When we’re not (or the admins are not) willing to extend permissions to some developers that allow truncating the table, such as the ddl_admin or db_owner roles. If we’re the administrators deciding whether to extend these permissions, we should be aware that not all developers may understand references, so some tools can seem to help, but really introduce bugs.
- When the table schema changes and we want to reload all data as opposed to updating data in the table based on the new schema definition. In these situations, we want to drop the entire table, create the table with the new schema definition, and add the data.
Using common table expressions (CTEs) in delete statements
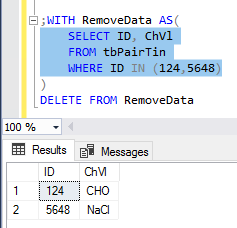
What about development situations where we want to remove a subset of records over removing all records? If we want to take extra caution about removing records, we can use a CTE for first filtering before removing records. In the below queries we see the work shown with a query that only uses a CTE for a select, then a delete statement from the same CTE.
|
1 2 3 4 5 6 |
;WITH RemoveData AS( SELECT ID, ChVl FROM tbPairTin WHERE ID IN (124,5648) ) DELETE FROM RemoveData |
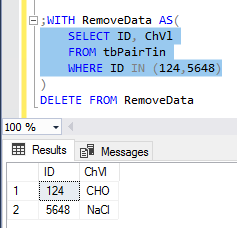
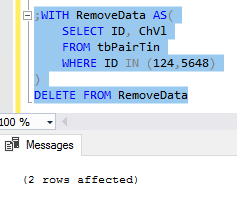
Unlike truncate statements, delete statements may be costly due to errors or an error. If we know that we need to remove all data in a table, we’re less likely to make a mistake with a truncate since all data are being removed from a table. However, a delete statement can introduce errors by accident because if a filter is wrong, mistyped, or forgotten, records are wiped out and must be recovered. Using CTEs add extra work but offers two benefits to delete statements:
- They raise awareness about what’s being removed by slowing urgency (which I’ve frequently observed is a root of many errors). A developer must first write the select, wrap it, then use the delete statement. If a developer must request that a DBA reverse a delete, the first question DBAs often ask is “what checks were in place?” or “what validation was used?” Using BEGIN TRANs, CTEs, or other validation checks look careful, whereas running a delete statement without any checks looks less careful. This is built into the CTE, as we can simply use the select within the CTE.
- A common delete technique used to reduce errors is to remove the data, then query the table to validate. The CTE structure makes this easy, as we have the select already written. I would still suggest using a begin transaction with a commit or rollback transaction and a check prior to committing.
- Due to a CTE’s structure, we can run the query inside of the CTE before executing the delete. In the above code, for instance, we can highlight the query within the CTE, then check the data. In fact, all CTE deletes can re-use the same below format where the query for removal is dropped within the parenthesis:
|
1 2 3 4 |
;WITH RemoveData AS( ---- query here ) DELETE FROM RemoveData |
While this does raise awareness and adds a convenient check in place, it does require some extra effort on the part of the developers.
Dropping all development tables by schema that are no longer required.
If we’re testing a set of tables for a proof-of-concept and we don’t intend to keep the tables in our development, the below procedure will drop all tables by a schema. If we validate our proof-of-concept, we can retain the tables or migrate them to our default or permanent schema; if we invalidate our proof-of-concept, we can remove all the tables. This procedure also makes it easy when we’re demoing concepts to teams and we create tables during a presentation under a demonstration schema for easy later removal. Finally, if we keep table backups for when we change lookup data or other smaller data sets in production and throughout our environments, we can use other tables schemas for these backups and drop them later after our testing is complete (a rare production use-case).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
CREATE PROCEDURE stpDropAllTables @schema VARCHAR(50) AS BEGIN DECLARE @sql NVARCHAR(MAX) = '' SELECT @sql += 'DROP TABLE ' + QUOTENAME(schema_name(schema_id)) + '.' + QUOTENAME([name]) + ' ' FROM sys.tables WHERE schema_name(schema_id) = @schema EXEC sp_executesql @sql END |
While it is bad practice to use keywords when naming tables or schemas, this is unfortunately common. The drop statement wraps the schema and table name within brackets using the QUOTENAME function to prevent this situation. In the below example, we create a schema and table that are both keywords and drop them successfully:
|
1 2 3 |
CREATE SCHEMA [key] CREATE TABLE [key].[Value] (ID INT) EXEC stpDropAllTables 'key' |
If you are the architect or the designer and have control, it is best practice to avoid using keywords for naming objects, but this will help in those situations where we’re required to use them by architects or clients who do not care for following best practices.
With this, we can develop on a schema and only keep objects we use. Otherwise, we can remove all objects by our development (or other named) schema.
References
- Restrictions on truncate table
- The logging behavior of the delete command from Microsoft
- Reserved keywords in T-SQL
- Microsoft on the truncate table command

He has spent a decade working in FinTech, along with a few years in BioTech and Energy Tech.He hosts the West Texas SQL Server Users' Group, as well as teaches courses and writes articles on SQL Server, ETL, and PowerShell.
In his free time, he is a contributor to the decentralized financial industry.
View all posts by Timothy Smith
- Data Masking or Altering Behavioral Information - June 26, 2020
- Security Testing with extreme data volume ranges - June 19, 2020
- SQL Server performance tuning – RESOURCE_SEMAPHORE waits - June 16, 2020