
In the past two years, we’ve seen an explosion in growth with document-oriented databases like Azure Cosmos DB. MongoDB – one of the major document databases – went live on the Nasdaq and attracted some attention in the past year as well. While more developers are using the document structure for some appropriate data models, less than 10 years ago, some in the industry were predicting that document databases were unnecessary and wouldn’t last because all data could be flattened to fit the SQL model. I took the opposite approach, being an early adopter of MongoDB along with continuing to use SQL databases as I saw opportunities in both SQL and NoSQL for various data structures. While some data do fit the SQL model and SQL will continue to exist, some data are best for document databases, like Azure Cosmos DB. In this series, we’ll be looking at the why and how of document databases.
Understanding “Why”
If you step into a room of developers who are accustomed to working with SQL and you suggest a document database for a data model because you know the data fit the model, you may experience resistance (though less today since these databases have been around longer). Unfortunately, since document databases like Azure Cosmos DB are still relatively new, you will need to know why they’re appropriate in some contexts. In addition, document databases can be integrated with SQL databases, where a document database is a source of data (like file systems are sometimes a source of data) with values being extracted for reporting in a SQL database.
We have a document-like database that we use regularly – the file system. This analogy is the easiest to relate to because the file system can store many different types of files with different structures while still keeping some meta-information that we can query, such as the name, creation and modified time, the file type, etc. The second point is key: a document database, like Azure Cosmos DB, is not like a used car dump where we dump data and hope to find it later – we still need a structure that we’ll query by, even if the rest of the document has a different structure.

These files all share the same file path and have metadata (name, create date, etc), but differ in structure.
Because this point of querying structure can confuse beginning developers to document databases, for this tip, we’ll be looking at the business problem of developing an application and storing information for a specific individual’s exercise routines in fitness. Before we choose a database engine like SQL Server or Azure Cosmos DB, it’s important that we fundamentally understand the business problem we’re trying to solve. For querying stored data, our business requirements that our users want will be the following:
- Users query by date
- Users query by type of exercise routine
The second query involves comparing an identical exercise routine, such as comparing the distance of a jog to the distance of another jog, not to a straight press that involves weight and repetitions. Like a notebook, our Azure Cosmos DB will follow a similar pattern where new records mean the latest date. This is like someone writing down their exercises sequentially with the newest exercises occurring later in the notebook. To avoid listing hundreds of workouts in our example, we’ll look at three different types for this example:
- Treadmill run workout
- Jump rope and pushup circuit workout
- Endurance workout
We don’t need to know details about these for this example, other than they differ in their workout category and they’ll follow different structures in their documents (as we’ll see). In addition, we may have multiple documents with the same category of workout, but never at the same exact time for an individual.
Creating the Sample Documents
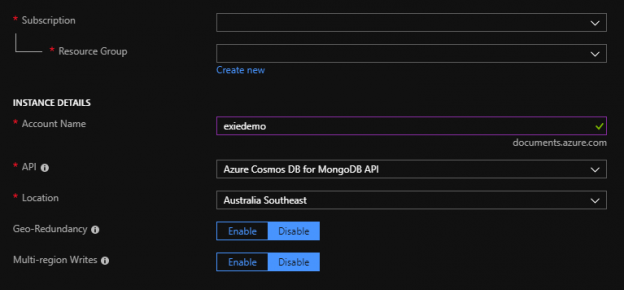
We’ll start by creating a Azure Cosmos DB and for this exercise, we’ll be using the Azure Portal. The steps for this are as follows:
- Either create a new resource group or select an existing resource group you want to use (pictured, but intentionally left blank).
- The name must be unique since we’re using the .documents.azure.com, so come up with a unique name.
- For this series, we’ll be using Azure Cosmos DB for MongoDB API
- Select an appropriate location.
- We will leave off Geo-Redundancy and Multi-region Writes, but as we’re setting this up, consider these as options that may be useful in your context.
- Click “Review and create” and it will confirm your selections before creating.
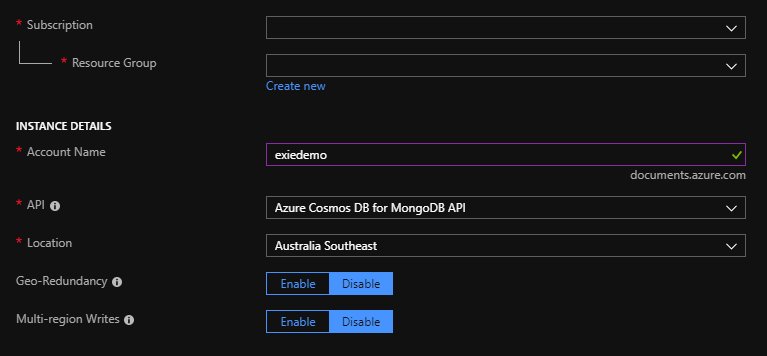
Setting up a new Cosmos database.
Adding A Collection and Documents
Our next steps will be to create our exercise database and routine collection in the Azure Cosmos DB that we just set up. The steps are as follows with images:
- First, we’ll select the option Data Explorer. This may take a few seconds to open that will allow us to create new databases and collections
- Second, we’ll click on New Collection. This will start a dialogue box that will give us some options to enter (see the below three images)
- We’ll select the option to create a new database (since we have none right now) and call it Exercise. We’ll also create a collection called routines in the Azure Cosmos DB
- Because this is only a demonstration and our requirements were storing an individual’s workout routine, we’ll select the Fixed (10GB) option and set our throughput to 400, which is low, but will suffice for this example. We would want higher throughput if we expected larger loads, though higher throughputs do cost more and we would want an unlimited size (and partition key) if we wanted to store multiple individuals’ workouts
- Finally, we want a unique key – the date and time of the exercise routine. Since an exercise for an individual can never happen at the same start time, this will be our identifier for this example
- Once we have it created, we’ll click on the database and collection and select the “Documents” option. This is where we’ll create our new documents for our Azure Cosmos DB
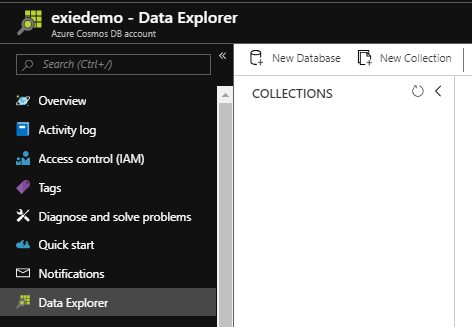
Select the “Data Explorer” option and “New Database”
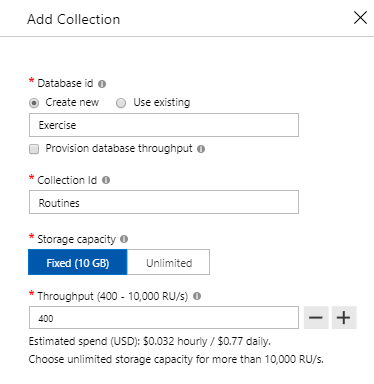
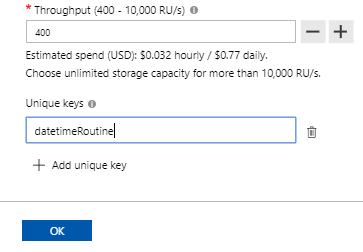
The above options show the naming of the database, collection, storage options, and unique keys along with RU/s.
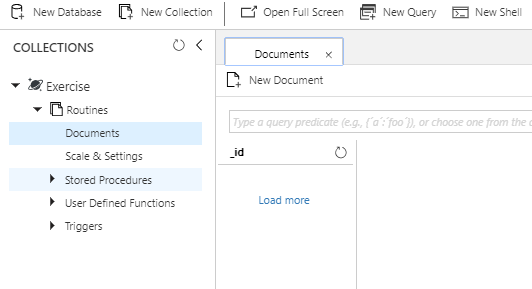
Once the database and collection is created, click “Documents” which will have nothing in it at first.
We can use a shell to run operations on the database level. In the below image, we see that I first searched for the collections (“show collections”), then searched for all documents in the collection (db.Routines.find()), which result in nothing because there are no documents. We can use the shell for interacting with our Azure Cosmos DB, especially if we’re more comfortable with it.
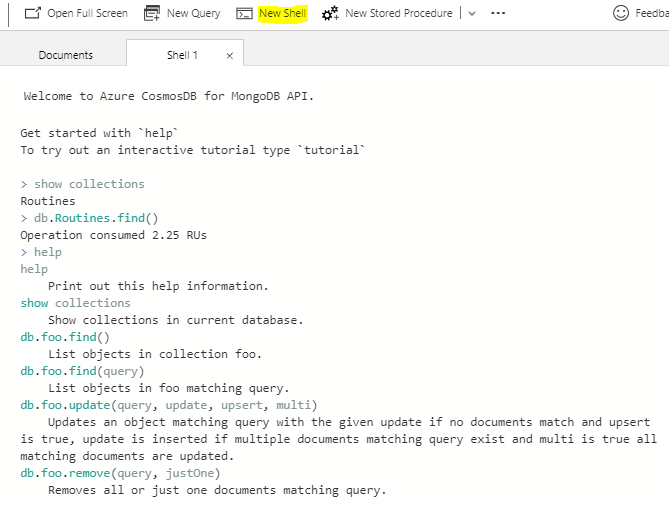
We’ll go ahead and create one document using the shell, using the insert operation. We will insert the below document that involves an exercise that is a treadmill run:
db.Routines.insert({“datetimeRoutine”:”2017-01-01 4:00AM”, “type”:”Treadmill Run”, “distance”:”3 miles”,”time”:”30 minutes”})

We’ve created our first document using the shell in Azure Cosmos DB, while receiving the total used RUs for the operation.
Now that we’ve created our first document, let’s return to the Documents option, refresh our documents, then see what we have:
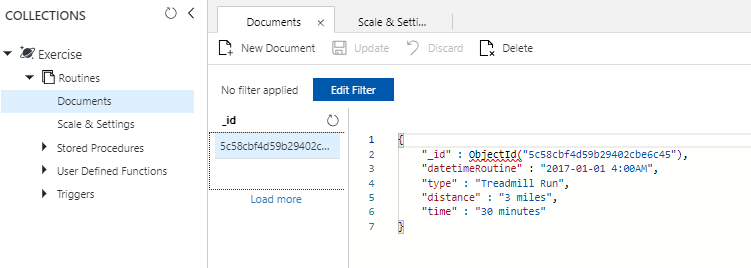
We see our first document we created through the Shell.
Because this Azure Cosmos DB is using MongoDB, every MongoDB document must have a unique id field (we could have used that for our field, but for this example we wanted the datetimeRoutine also added). This doesn’t mean that we can violate our unique rules for datetimeRoutine – for instance, if we tried inserting a duplicate record with that date, we’d get an error:

We have defined a unique key that prevents us from inserting the same datetimeRoutine.
Now, we’ll use the “New document” option to create a document over using the Shell. When we select this, we’ll see a blank document with an id field already ready. We’ll overwrite this with the below document:

We see the blank document – we do not need to use this id field and if it appears, it can be removed. The id field of _id cannot be removed.
|
1 2 3 4 5 6 |
{ "datetimeRoutine" : "2017-01-02 4:00AM", "type" : "Jump Rope/Pushup Circuit", "Jump Rope": "20 minutes", "Pushup total": 250 } |
Our result will show once we click “Save”:
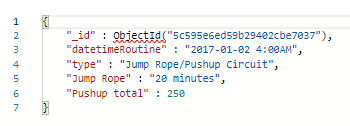
Because this Azure Cosmos DB is using MongoDB underneath, the _id field will automatically be created when we save documents. Next, we’ll create 3 more documents which are as follows:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
{ "datetimeRoutine" : "2017-01-04 4:00AM", "type" : "Jump Rope/Pushup Circuit", "Jump Rope": "20 minutes", "Pushup total": 275 } { "datetimeRoutine" : "2017-01-05 4:00AM", "type" : "Endurance", "Pushup AMRAP": 1050 } { "datetimeRoutine" : "2017-01-07 4:00AM", "type" : "Treadmill Run", "distance" : "3 miles", "time" : "30 minutes" } |
Now in our Azure Cosmos DB, we have a total of 5 documents that we’ve created for this example and as we see, these documents follow 3 different “types” of exercise routines with each having a unique start time. We can now return to our Shell and run a filtered select against our database to return the endurance workout and we can see our list of workouts as well (only 3 are shown):
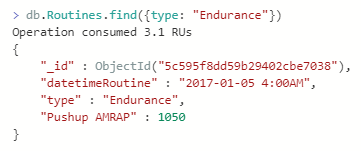
The result of our query for the endurance workout routine.
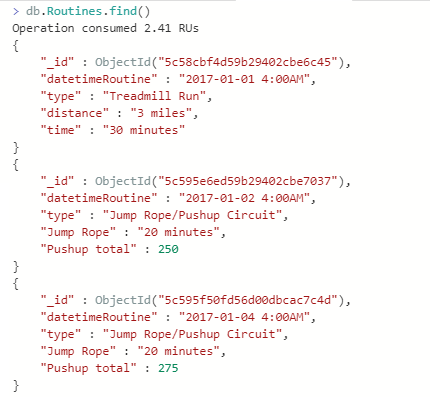
The result of our query for all documents.
We see different structures for our documents in this collection, but we also see that we have field which help us identify what they are. This is important because we’re not treating our Azure Cosmos DB as a car dump where we push data into it and devise ways to extract the data later – we’ve thought about how our individual user will query this database – by date and workout type – and we’ve used these as fields in our database.
Summary
In this part, we looked at an example involving an individual’s fitness routine because most people committed to fitness will challenge their body differently over time, which would lead to a very convoluted SQL table structure (while we see 3 routines, over time it would be in the 100s). NoSQL databases, like Azure Cosmos DB, allow for the flexibility of these constantly evolving data models while keeping them grounded by a main key or two that tends to be involved in the querying or order. In addition, a NoSQL database may be a data store for data extraction that populates a SQL database for further analysis in some cases – hybrid models with NoSQL and SQL exist just like we have file systems that feed SQL databases.
Table of contents
| Getting Started with Azure Cosmos DB |
| Updating and Querying Details in Azure Cosmos DB |
| Applying Field Operators and Objects in Azure Cosmos DB |
| Getting Started with Subdocuments in Azure Cosmos DB |

He has spent a decade working in FinTech, along with a few years in BioTech and Energy Tech.He hosts the West Texas SQL Server Users' Group, as well as teaches courses and writes articles on SQL Server, ETL, and PowerShell.
In his free time, he is a contributor to the decentralized financial industry.
View all posts by Timothy Smith
- Data Masking or Altering Behavioral Information - June 26, 2020
- Security Testing with extreme data volume ranges - June 19, 2020
- SQL Server performance tuning – RESOURCE_SEMAPHORE waits - June 16, 2020