
Background
As a database administrator, sometimes you need to identify details about a problem as quickly as possible and being able to build and analyze data for analysis will help you solve the problem. From getting information about the latest backups, to saving information about waits or indexes and comparing that to other captured metrics, we will run into issues where being able to get, store and analyze data are important for decisions to solve urgent problems.
In this article, we look at three effective ways to format data in a manner that allows you to quickly look at your data sets, filter it further, and identify your problem. Since speed is the key in these situations, these tools will not be designed for retaining data or design for the most effective queries, so for longer term analysis needs, we would either want to expand on these tools or use other methods for saving and retaining data.
Discussion
If the output of data originates from a select statement in a stored procedure (return data, even if other CRUD operations exist), one quick way to obtain a data set for analysis is to save the output of the select query to a table. As a simple example of this, suppose that we had the below defined stored procedure, which starts with an insert statement and returns a joined select query:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
--Procedure example with an insert and returned select: CREATE PROCEDURE ExampleProcedure AS BEGIN INSERT INTO JoinTable SELECT OurVarcharColumn FROM CrudTable WHERE ID IN (2,5,9) SELECT t.OurIntColumn , tt.OurVarcharColumn , t.OurDateColumn , t.OurDateTimeColumn FROM OurTable t INNER JOIN JoinTable tt ON t.Name = tt.Name END |
This procedure would return four columns in the final select statement and we can save this output to a table for analysis by creating a table that matches the select statement’s data returned, inserting the data from the procedure, and running our analysis queries.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
-- We build the table, insert the data by executing the procedure, then look at the data CREATE TABLE SaveTable( OurIntColumn INT , OurVarcharColumn VARCHAR(5) , OurDateColumn DATE , OurDateTimeColumn DATETIME ) INSERT INTO SaveTable EXEC ExampleProcedure SELECT * FROM SaveTable WHERE OurVarcharColumn LIKE 'a%' |
Notice that the table we create matches the output of the query return in the stored procedure – this is key to avoid syntax errors. I will caution readers that this method only applies to situations in a few cases:
The stored procedure isn’t a simple select query. If it is, see the rest of the article for an even faster way to analyze this data, if needing to save it to a table.
The stored procedure’s select query doesn’t return too many columns. It may be inconvenient or require too much time if you must create a table with 100 columns when you may just edit the internal procedure process and save it with other methods in this article.
The stored procedure’s other CRUD operations don’t interfere with other processes whether in a testing or production environment.
Another option, especially if we have a select query is to create a table on-the-fly using the SELECT * INTO syntax. This will create a table from a query, using the return query’s data as the structure for the data in the returned table.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
SELECT OBJECT_ID('SaveTable') SELECT t.OurIntColumn , tt.OurVarcharColumn , t.OurDateColumn , t.OurDateTimeColumn INTO SaveTable FROM OurTable t INNER JOIN JoinTable tt ON t.Name = tt.Name WHERE OurVarcharColumn LIKE ‘a%’ SELECT OBJECT_ID('SaveTable') |
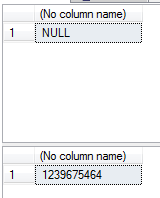
We can see in the below image that the table didn’t exist before this query created it, but now does:
For queries, this is one of the fastest ways to create a table for analysis and this is generally the most effective method to use. There are only a few drawbacks:
-
If the select query returns a huge amount of data, the database must have space to handle these data, so this may not be appropriate in all environments. For an example, in the below image, I see the row count and size of a table and I would probably select a portion of it, unless I absolutely needed all of it:

Structures like clustered columnstore indexes and statistics objects will not transfer over to the new table, so consider table and data size when using this. If using this with smaller data sets (relative to the environment), this will be less of a problem.
This may be incompatible with other data if you choose to add more data to the table. While you can create a new table by selecting everything into the new table, you cannot do it again with the same newly created table to add data to that table. This means that if ColumnOne is a VARCHAR(5) from your first creation, trying to insert a value that is VARCHAR(10) will fail for that column.

In general, this is also a quick way to create a table based on existing tables, such as tables used in joins with similar fields.
The other way to quickly analyze data is the common table expression or subquery. We can use common table expressions or subqueries as if they were their own table for quick analysis and we can even save them using the above method (adding an INTO NewTable, for an example) if we need, or if want to retain the data.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
-- CTE: ;WITH CTE AS( SELECT ROW_NUMBER() OVER (ORDER BY NumCalc) OrderedId , NumCalc , Outcome FROM ExampleCTE ) SELECT OrderedId , CASE WHEN Outcome = 1 THEN 'Pass' ELSE 'Fail' END AS Assessment , (NumCalc * (OrderedId/2)) Measure FROM CTE -- SUBQUERY: SELECT sub.OrderedId , CASE WHEN sub.Outcome = 1 THEN 'Pass' ELSE 'Fail' END AS Assessment , (sub.NumCalc * (sub.OrderedId/2)) Measure FROM ( SELECT ROW_NUMBER() OVER (ORDER BY NumCalc) OrderedId , NumCalc , Outcome FROM tblChangeSchema ) sub |
In some situations, these may involve more work than the above method of creating a table on the fly. However, in my view, they can make fine-tuning the analysis fast because it can be easy to add other sets of data with them, or allows for ease of converting a data set into a numerical format for faster analysis. The drawback that I see with some DBAs and developers is syntax – these must be written correctly. One of my favorite features of both CTEs and subqueries is how quickly they can be debugged by highlighting inner queries to verify that we have what we want; in the below image, I can return the query highlighted without selecting the full CTE for verification – this saves a lot of time during debugging:
Finally, if I need to retain the data, I can always add the INSERT before the from to save the data to a new table, or I can save these data by using a standard insert statement.
Some Useful Tips and Questions
When considering which of the above to use, some of the questions I like to ask are:
Will I only need this once, or is it possible that I might re-use this at some point? If I only plan to use it once, creating a new table on the fly is my preferred method, assuming it’s the most appropriate based on the above cautions.
What type of analysis am I performing? Will I possibly need other sets of data?
What’s the big picture here? If I need to analyze data for replication or availability groups, what would be more helpful than this in the long run? While we may not have time to architect a solution to a problem when we face one, one thing I like to do is keep a “wish list” of development items that I can return to later.
Final Thoughts
The purpose of each of these is to quickly analyze a data set without the overhead of too much architecture or design. We may want to keep some of these data for permanent use, or we may like the process we build and make it permanent. In these cases, I would suggest building methods for capturing these data in a manner that allows for ease of capture, but also one that doesn’t add overhead to the server.
It is worth noting that we will experience problem-solving sessions where we may use all three of the above methods. We might need to save the output of a stored procedure to a table and join it to another set of data with a subquery and save it also to a table, which involves all three of the above methods. The key is that we’re able to get data as quickly as possible, since our focus is on solving the problem.

He has spent a decade working in FinTech, along with a few years in BioTech and Energy Tech.He hosts the West Texas SQL Server Users' Group, as well as teaches courses and writes articles on SQL Server, ETL, and PowerShell.
In his free time, he is a contributor to the decentralized financial industry.
View all posts by Timothy Smith
- Data Masking or Altering Behavioral Information - June 26, 2020
- Security Testing with extreme data volume ranges - June 19, 2020
- SQL Server performance tuning – RESOURCE_SEMAPHORE waits - June 16, 2020