
One of the challenges we face when using SQL bulk insert from files flat can be concurrency and performance challenges, especially if the load involves a multi-step data flow, where we can’t execute a latter step until we finish with an early step. We also see these optimization challenges with constraints as well, as fewer steps to complete a data flow results in saved time, but possibly less accurate data.
We’ll look at solving concurrency issues, where we prevent a data flow process from accessing data too early in a central repository situation. In addition, we’ve also looked at some techniques to specify options which ensure that our business rules and constraints are followed while data are being inserted. We’ll also look at optimizing our data structures to strengthen performance for when we load data from files using this native tool in T-SQL.
SQL Bulk Insert in Transactions
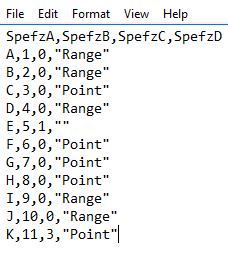
Identical to other CRUD operations, bulk loads, including SQL Bulk Insert, can be wrapped in a transaction and rolled back entirely if we don’t get our expected results, or if we experience a failure. In the below file and code snippet, we see that the last line of our file doesn’t match the expected bit value of either 0 or 1 and we know based on other tips in this series that this will fail this line. If our software in this example depended on 11 records after the insert and this test failed because there were only 10 records, then we would roll back this insert.
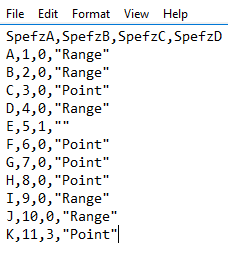
Our file’s last line has an incorrect bit value of 3.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
IF EXISTS (SELECT OBJECT_ID('etlImport5')) BEGIN DROP TABLE etlImport5 END CREATE TABLE etlImport5( VarcharSpefzTen VARCHAR(10), IntSpefz INT, BitSpefz BIT, VarcharSpefzMax VARCHAR(MAX) ) BEGIN TRAN BULK INSERT etlImport5 FROM 'C:\ETL\Files\Read\Bulk\daily_20180101.txt' WITH ( FIELDTERMINATOR = ',', ROWTERMINATOR = '\n', FIRSTROW = 2, MAXERRORS = 10 ) ---- Query before rollback SELECT COUNT(*) CountRecs FROM etlImport5 ROLLBACK TRAN ---- Query after rollback SELECT * FROM etlImport5 |
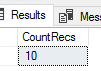
Our query result prior to our rollback.

Our query of the table after the rollback – all inserted records were rolled back.
This helps us test conditions in our data flows so that we prevent bad data from being fed further into our data sets. Following this insert after the transaction begins and prior to committing, we can run many tests against our data set, such as a count of records, an average of numeric columns or a check of their ranges, a length comparison on text-based columns, etc. If any of these validations fails, we can rollback our insert and our table will have none of the inserted records. In the below code snippet, we see how another transaction (in a separate query window) which may use our table is blocked from using our table until we’ve either committed or rolled back our transaction.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
---- In our main query window BEGIN TRAN BULK INSERT etlImport5 FROM 'C:\ETL\Files\Read\Bulk\daily_20180101.txt' WITH ( FIELDTERMINATOR = ',', ROWTERMINATOR = '\n', FIRSTROW = 2, MAXERRORS = 10 ) ---- In a new query window SELECT * FROM etlImport5 |
Since a commit or rollback hasn’t been executed, the new query is waiting.
Blocking can be useful to prevent access to data too early in flows (in this case, non-validated data): we don’t want any developer or process using data that hasn’t been validated since we know that no data is better than bad data. Since some of these processes may be other DML operations, like updates, this could also delay the data being added to the table from the file. This second transaction being blocked may be a feature in this case preventing data use that hasn’t been checked, or further steps in our flow from disrupting it. While we tend to develop for multiple transaction access, in strict step-by-step data flows, we want to restrict this access until completion.
This is a useful design when we create central data repositories from flat files where we may have multiple ETL processes that use these central repositories – relative to where and how we validate these data, we may want these further processes blocked until validation is completed.
Indexing around SQL Bulk Insert
Removing indexes prior to large inserts on a table, including when using SQL Bulk Insert, may be a best practice to increase performance. Are there scenarios that might change this practice of removing indexes prior to inserting a large amount of data? Let’s consider a few scenarios where we may avoid dropping indexes before a large insert statement:
- Are we inserting data into a table that already has records or an empty table? If it’s an empty table, we can drop and re-add the indexes following the insert. If the table has records with little or no fragmentation, this may not be efficient. Also, if we tend to truncate the table following an insert, validation and extraction, we may re-create the table at the first step, insert the data, then add indexing, if the indexing increases validation performance
- If the table has records in it from the above point, how many records are we adding relative to the existing table size? For an example, suppose our table has 1 million records and we’re adding 500,000. That means that with the new insert and existing table, we’re adding a volume of 33% (500,000 out of 1,500,000). In this case, I would consider removing indexes prior to the insert and re-adding them following the insert. However, if we’re adding 500,000 to a table with 100,000,000 existing rows of data, I would want to evaluate the data further
- If we’re using SQL bulk insert to add a well-proportioned size of data relative to the existing data size, are the new data sequential or random? If our data are sequential in that they add on to our existing data set, we may not need to drop and add indexes, relative to the proportions as these are sequential data (such as the newest records being the latest date). If they are random in that these new values are inserted among existing values, we may find it useful to drop and recreate our indexes
- Is this a staging table that we reload each time we insert data and validate on the entire data set before migrating the data elsewhere, then removing the data? If so, we may not use the drop-and-recreate multiple index technique, but use a drop and re-create table or we may use a clustered column store index, as the queries will be against the full table and this may be a better performing solution than multiple indexes. Creating an index isn’t a free operation, so the performance gains we get from increased query speed in validation must account for the creation cost
Even considering these steps, we ultimately want to increase performance, so exceptional situations that generate strong performance will exist.
Overriding Defaults with SQL Bulk Insert
In some cases, default constraints enforce our business rules and if we want to reduce steps in our data flow, enforcing these constraints early in our data flow can help us maintain only a few steps and increase the speed of producing our data for clients. The performance boost of reducing steps can be significant and how we reduce steps or if we determine it will assist us is key. Even if it adds another step, we may want to avoid a table’s default constraints, such as importing a new data set than our standard data sets, allowing a file’s information to override table constraints to be useful for filtering out records (the below example), or other possible scenarios where a table default may need to be replaced file a file’s information.
In the below example prior to calling SQL bulk insert, we add an identity field to our file and we change the order of 8 and 9. We also remove the incorrect bit value of the last line in our file to be a null. When we create our table again in this example, we’ve added an identity column which increments by 1 and we see that our bit column has a default of 0. With the below transaction, we specify the options to keep nulls and identity values from the file regardless of what the table specifies and we see the result shows the file’s values, not the table’s default values.
We’ve removed the invalid 3, replacing it with a null and added an identity column that is out of order for rows 8 and 9.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
IF EXISTS (SELECT OBJECT_ID('etlImport5')) BEGIN DROP TABLE etlImport5 END CREATE TABLE etlImport5( SpefzId SMALLINT IDENTITY(1,1), VarcharSpefzTen VARCHAR(10), IntSpefz INT, BitSpefz BIT DEFAULT 0, VarcharSpefzMax VARCHAR(MAX) ) BULK INSERT etlImport5 FROM 'C:\ETL\Files\Read\Bulk\daily_20180101.txt' WITH ( FIELDTERMINATOR = ',', ROWTERMINATOR = '\n', FIRSTROW = 2, MAXERRORS = 10, KEEPNULLS, KEEPIDENTITY ) SELECT * FROM etlImport5 |
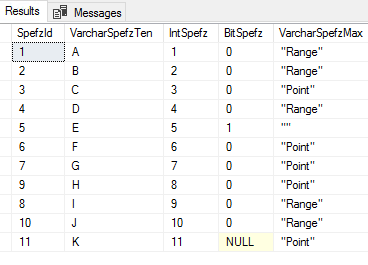
Our specifications overrode the defaults of the table.
Using this example, if these records don’t follow our business rules, we may want the table’s defaults replaced by the file’s defaults because these will disqualify these records for this source of data. We may also have them override the default to check on these records with the data vendor, or with another source of information. By contrast, if we have one table per file source, we may never need to use these options. Situations where we may be using the same table for multiple sources may call for us to override the table defaults for some file imports.
Conclusion
We’ve looked at wrapping SQL bulk insert in transactions to prevent access until data validation occurs in situations where data validation must occur before next steps. We’ve also looked at performance design around large inserts from files, especially involving possibly dropping tables or removing and adding indexes. In addition, we’ve also seen options that we can specify within this tool that enforces our business rules, like constraints and prevents access during the insert operation, which may increase the performance of our data flow. Some of these options will be appropriate in different data flow scenarios and this helps us get a picture of how dynamic this tool can be used alongside other tools T-SQL offers.
Table of contents
| T-SQL’s Native Bulk Insert Basics |
| Working With Line Numbers and Errors Using Bulk Insert |
| Considering Security with SQL Bulk Insert |
| SQL Bulk Insert Concurrency and Performance Considerations |
| Using SQL Bulk Insert With Strict Business Rules |

He has spent a decade working in FinTech, along with a few years in BioTech and Energy Tech.He hosts the West Texas SQL Server Users' Group, as well as teaches courses and writes articles on SQL Server, ETL, and PowerShell.
In his free time, he is a contributor to the decentralized financial industry.
View all posts by Timothy Smith
- Data Masking or Altering Behavioral Information - June 26, 2020
- Security Testing with extreme data volume ranges - June 19, 2020
- SQL Server performance tuning – RESOURCE_SEMAPHORE waits - June 16, 2020