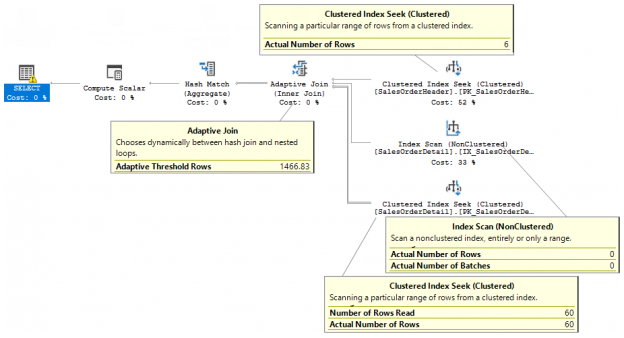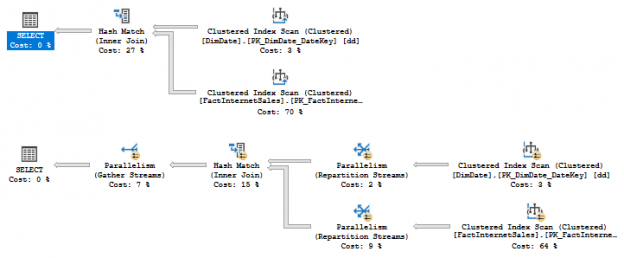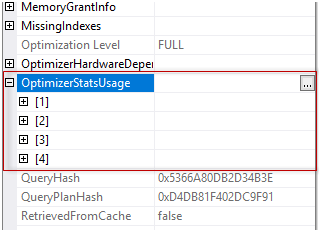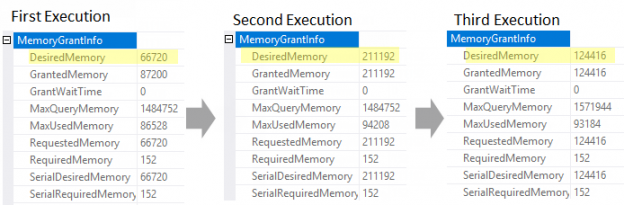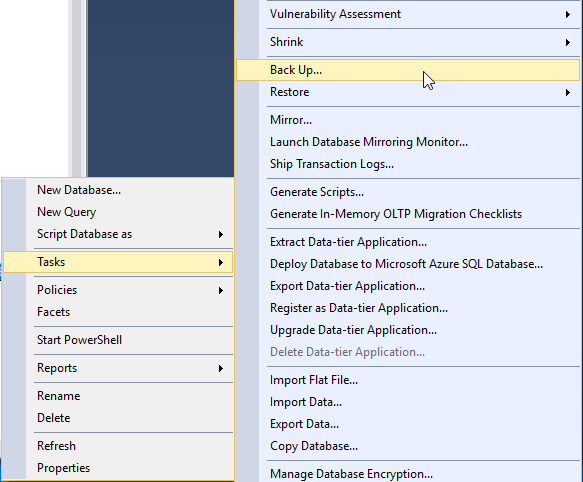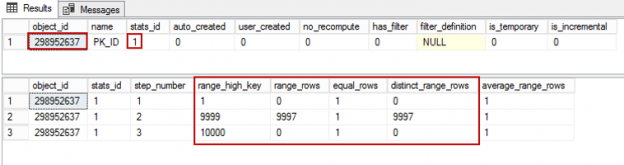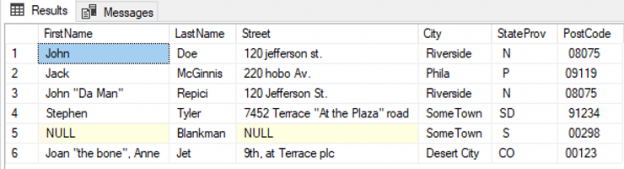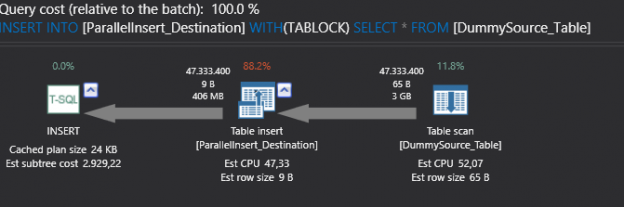
So far, we’ve discussed several phases of backup that starts with planning, creating, strategizing and implementing. In this article, we are going to see how database administrators can define the strategy to improve backup performance and efficiently manage backups in SQL Server 2017. The following are the topics of discussion:
- Discuss checkpoints
- Discuss the enhancements made in the Dynamic Management View (DMV) sys.dm_db_file_space_usage for smart differential backups
- Discuss the enhancements made for the Dynamic Management function (DMF) sys.dm_db_log_stats for smart transactional log backup
- Understand the functioning of smart differential backup and its internals
- Understand the Smart transaction log backup process and its internals
- T-SQL scripts
- And more…