
SQL Server 2017 brings a new query processing methods that are designed to mitigate cardinality estimation errors in query plans and adapt plan execution based on the execution results. This innovation is called Adaptive Query Processing and consist of the three features:
- Adaptive Memory Grant Feedback;
- Interleaved Execution;
- Adaptive Joins.
We have discussed two of them in the previous posts: SQL Server 2017: Sort, Spill, Memory and Adaptive Memory Grant Feedback and SQL Server 2017: Interleaved Execution for mTVF
In this post, we will discuss the last one – Adaptive Joins.
Adaptive Joins were publicly introduced in the CTP 2.0, I advise you to read a post by Joe Sack Introducing Batch Mode Adaptive Joins to get know about this feature, because I will give only a brief introduction before making a deep dive into the Adaptive Join internals.
Introduction
We have three types of physical join algorithms in SQL Server: hash, nested loops and merge. Adaptive join allows SQL Server automatically choose an actual physical algorithm on the fly between the first two – hash (HM) and nested loops (NL).
NL has two join strategies – naive nested loops join (inner loop scans the whole inner table or index) and index nested loops join (index on the join column of the inner table is used to find necessary rows and then those rows are applied to the outer row, also called Nested Loops Apply). Typically, the second one performs very well if you have rather small input on the outer side and indexed rather big input on the inner side.
HM is more universal and uses hash algorithms to match rows, so no indexes are necessary. You may refer to my previous article (Hash Join Execution Internals) for more details.
Adaptive Join starts execution as a Hash Join. It consumes all the input of the build phase and looks at the adaptive join threshold, if the number of rows is more or equal this threshold it will continue as a hash join. However, if the number of rows is less than this threshold, it will switch to a NL.
Threshold is a number of rows, which represents a point, at which NL is cheaper than a HM. This number of rows is calculated during the compilation and is based on the cost estimates.
In the first implementation, Adaptive Join could be used only if the optimizer considers a Batch execution mode during the optimization (a new execution mode introduced in SQL Server 2012 for Columnstore indexes). However, Itzik Ben-Gan invented a trick with a dummy filtered Columnstore index on a table to give an optimizer the chance to consider a batch mode.
In a query plan, Adaptive Join is implemented as a new operator “Adaptive Join”, which has three inputs. The first input is an outer (build) input, the second one is an input if a HM is picked and the third one if NL is picked.
Let’s look at the example. I’ll use sample DB AdventureWorks2016CTP3 and set the compatibility level to 140 as it is necessary for an Adaptive Join to be available. I’ll also create a dummy filtered Columnstore index so the optimizer could consider a batch mode execution.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
use AdventureWorks2016CTP3; go alter database [AdventureWorks2016CTP3] set compatibility_level = 140; go create nonclustered columnstore index dummy on Sales.SalesOrderHeader(SalesOrderID) where SalesOrderID = -1 and SalesOrderID = -2; go declare @TerritoryID int = 1; select sum(soh.SubTotal) from Sales.SalesOrderHeader soh join Sales.SalesOrderDetail sod on soh.SalesOrderID = sod.SalesOrderID where soh.TerritoryID = @TerritoryID; go |
The plan is:
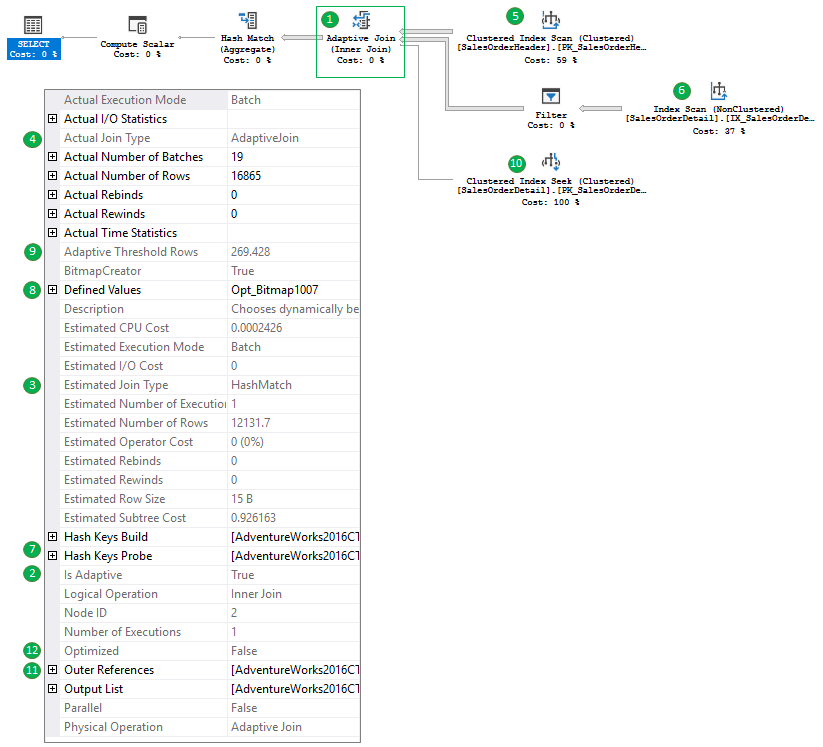
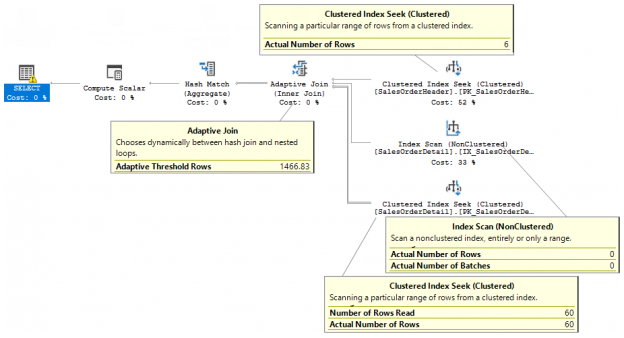
- You may see a new plan operator – Adaptive Join.
- Is Adaptive property is set to TRUE.
- The estimated join type, based on the estimated number of rows is Hash Match. If we add to the query “option (optimize for (@TerritoryID = 0))”, there are no rows for TerritoryID = 0, the estimated number of rows will go to 1 row and we will see Nested Loops in this property.
- Actual Join Type is Adaptive Join. This property is not yet implemented in the current version, it should show the actual join type that was picked.
- We see a Clustered Index Scan of the SalesOrderHeader as the first input – this is a build input if the HM is picked (7)
- We see an Index Scan of the SalesOrderDetail as the second input – this is a probe input if the HM is picked (7).
- We see a properties Hash Key Build and Probe that are properties for a HM.
- We also see a Bitmap filter defined, which is also used to be in a HM (or Merge) join usually.
- Then we may see an Adaptive Join Threshold – this is the number of rows which is used to switch between the join algorithms and input branches (6 for a HM and 10 for a NL)
- This is a branch that will be used by a NL join if the threshold 9 won’t be reached.
- Note the Outer Reference – the NL join’s property, which is SalesOrderID in our case.
- The Optimized property is also a NL join property, which is used to reduce random IO on the inner NL join side. You may refer to my post about this for more details.
Summarizing the plan – we see a new operator which has three inputs and depending on the threshold rows may use one or another input and the one or another join strategies either HM or NL. This operator contains properties for both of them.
For a more detailed description, I’ll refer you to the Joe Sack’s blog post mentioned above and we will move on to some internals and undocumented stuff.
Optimization Internals
It is interesting to know how this new operator is optimized. To look at the process we will use the undocumented trace flags 8607 which outputs the physical operator tree and the trace flag 7352 which outputs the tree after a post optimization rewrite phase. Let’s run our example query with those TFs and statistics IO turned on.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
alter database scoped configuration clear procedure_cache; go set statistics io on; declare @TerritoryID int = 1; select sum(soh.SubTotal) from Sales.SalesOrderHeader soh join Sales.SalesOrderDetail sod on soh.SalesOrderID = sod.SalesOrderID where soh.TerritoryID = @TerritoryID option(querytraceon 3604, querytraceon 8607, querytraceon 7352); set statistics io off; |
If we switch to the Message Tab in SSMS we will see the following.
Output physical tree (shorten for brevity):
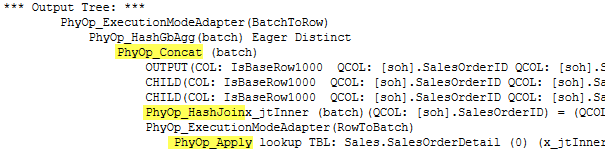
We see that after the optimization process the output tree is a concatenation (familiar to us Concat operator) of the output from the first table and two joins HM and NL (apply NL).
After the post optimization rewrite, we see an Adaptive Join operator.

You may also notice a spool operator, that one is used not to scan the first (build) input twice when we switch to a NL join. That is why we see a Worktable in the statistics IO output.

Interestingly, we may see this plan shape with a spool if we enable the undocumented trace flag 9415.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
alter database scoped configuration clear procedure_cache; dbcc traceon (9415); go declare @TerritoryID int = 1; select sum(soh.SubTotal) from Sales.SalesOrderHeader soh join Sales.SalesOrderDetail sod on soh.SalesOrderID = sod.SalesOrderID where soh.TerritoryID = @TerritoryID; go dbcc traceoff (9415); go |
The plan would be:
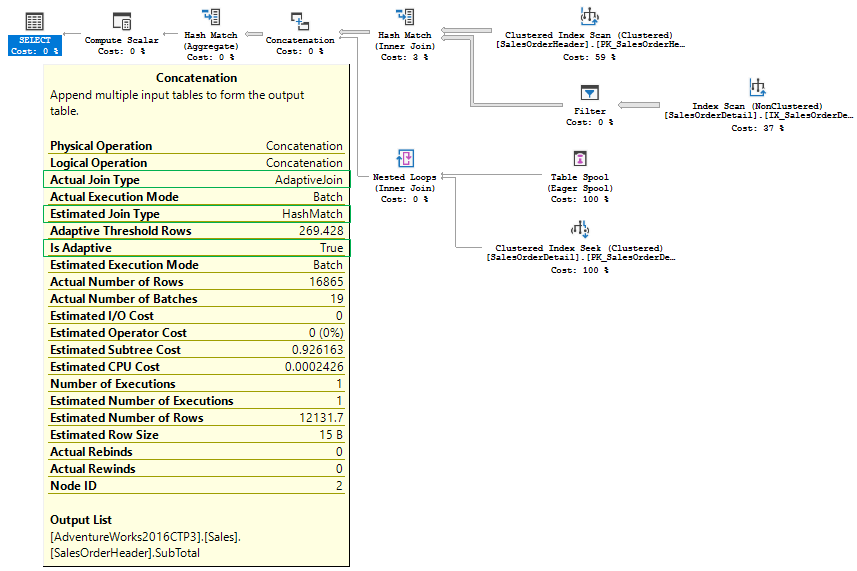
Notice some concatenation properties that we have seen earlier in the Adaptive Join operator. There is also a property Adaptive Threshold Rows (unfortunately, not shown in the tooltip). Both plans produced identical results in my experiments.
So far, we have found that an Adaptive Join undercover is a Concatenation operator with some extended properties. We’ll explore how it is physically executed later in the post.
Adaptive Threshold Rows
This is the number of rows when the switch to a NL join occurs if it is not reached. This threshold is based on the estimates. If we influence the number of rows in the first input and optimize it for different values – we may see how the threshold is changed. Here is an example:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
alter database scoped configuration clear procedure_cache; go declare @TerritoryID int = 1; select sum(soh.SubTotal) from Sales.SalesOrderHeader soh join Sales.SalesOrderDetail sod on soh.SalesOrderID = sod.SalesOrderID where soh.TerritoryID = @TerritoryID option(optimize for (@TerritoryID = 0)); select sum(soh.SubTotal) from Sales.SalesOrderHeader soh join Sales.SalesOrderDetail sod on soh.SalesOrderID = sod.SalesOrderID where soh.TerritoryID = @TerritoryID option(optimize for (@TerritoryID = 1)); select sum(soh.SubTotal) from Sales.SalesOrderHeader soh join Sales.SalesOrderDetail sod on soh.SalesOrderID = sod.SalesOrderID where soh.TerritoryID = @TerritoryID option(optimize for (@TerritoryID = 10)); go |
We may see the following values as an adaptive threshold:
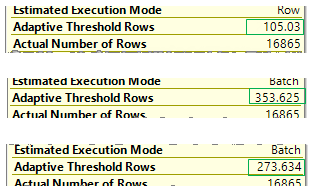
This means that a threshold depends on the estimates, so accurate estimates are still important. For example, estimates with parameter sniffing with parameters of the first input will also leverage the threshold. This situation is described very well in the Itzik’s post, referred above.
There is also one undocumented trace flag, that lowers the adaptive threshold to the minimum estimate (which is one row) plus one row, totaling 2 rows. That means that a NL join algorithm will be used only when there is one row of the first input.
Here is an example:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
alter database scoped configuration clear procedure_cache; go declare @TerritoryID int = 1; select sum(soh.SubTotal) from Sales.SalesOrderHeader soh join Sales.SalesOrderDetail sod on soh.SalesOrderID = sod.SalesOrderID where soh.TerritoryID = @TerritoryID option(querytraceon 9399); go |
If we look at the threshold we will see:
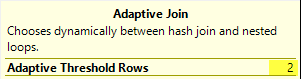
Disabling Adaptive Join
The first way is to switch to compatibility level 130. But if you switch to the Compatibility Level 130 you will also disable all the other optimizer improvements.
There are few other ways you can disable Adaptive Joins, all of them are undocumented at the moment of writing this post, however, some of them are very promising to be documented in the future.
TF 9398
If we apply the undocumented trace flag 9398 to our sample query, we may see that there is no adaptive join in the query plan.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
alter database scoped configuration clear procedure_cache; go declare @TerritoryID int = 1; select sum(soh.SubTotal) from Sales.SalesOrderHeader soh join Sales.SalesOrderDetail sod on soh.SalesOrderID = sod.SalesOrderID where soh.TerritoryID = @TerritoryID option(querytraceon 9398); go |
The plan has only a HM join:

Query hint DISABLE_BATCH_MODE_ADAPTIVE_JOINS
We may also use a query hint to disable and adaptive join.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
alter database scoped configuration clear procedure_cache; go declare @TerritoryID int = 1; select sum(soh.SubTotal) from Sales.SalesOrderHeader soh join Sales.SalesOrderDetail sod on soh.SalesOrderID = sod.SalesOrderID where soh.TerritoryID = @TerritoryID option(use hint('DISABLE_BATCH_MODE_ADAPTIVE_JOINS')); go |
The plan shape is the same as in the previous example:

Database Scoped Configuration Option DISABLE_BATCH_MODE_ADAPTIVE_JOINS
The exact same keyword is also available as a DB scoped configuration option in case you would like to turn off Adaptive Joins for the whole DB.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
alter database scoped configuration clear procedure_cache; alter database scoped configuration set DISABLE_BATCH_MODE_ADAPTIVE_JOINS = on; go declare @TerritoryID int = 1; select sum(soh.SubTotal) from Sales.SalesOrderHeader soh join Sales.SalesOrderDetail sod on soh.SalesOrderID = sod.SalesOrderID where soh.TerritoryID = @TerritoryID; go alter database scoped configuration set DISABLE_BATCH_MODE_ADAPTIVE_JOINS = off; go |
The plan is:

The last two methods (hint and config option) seem very promising to me to be documented at some point. Probably, it is not tested enough yet and not guaranteed to work properly, however, I hope they will be documented later.
Skipped Adaptive Join
In this section, we will talk about the situation when Adaptive Join is considered, but skipped due to some reasons. There is a new extended event adaptive_join_skipped which has a field reason. If we query the DMV dm_xe_map_values like this, we’ll see all the reasons:
|
1 |
select map_value from sys.dm_xe_map_values where name like 'adaptive_join_skipped_reason' |
We will get the following results:
- eajsrExchangeTypeNotSupported
- eajsrHJorNLJNotFound
- eajsrInvalidAdaptiveThreshold
- eajsrOuterCardMaxOne
- eajsrUnMatchedOuter
That is all about the optimization internals in this post, but this is a very first light touch of this topic. In the next part, we will talk about the execution internals of the Adaptive Join.
Execution Internals
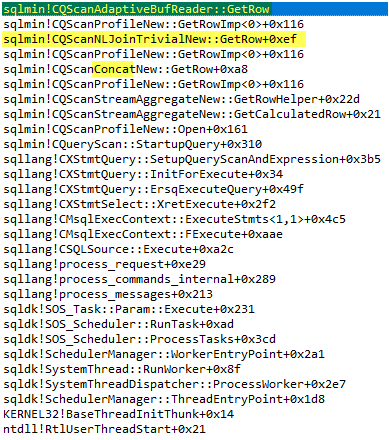
To look at how exactly the Adaptive Join is executed I used the WinDbg. I put a breakpoint on the method sqlmin!CQScanRangeNew::GetRow to see the call stack. Here is what I’ve got:
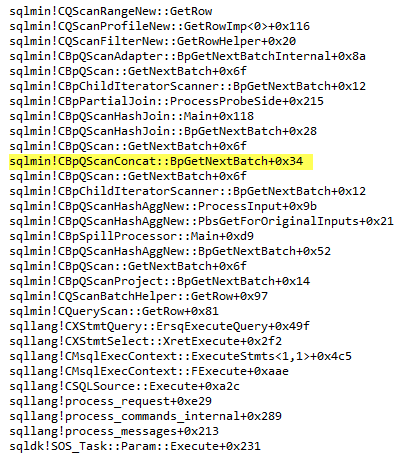
Reading bottom-top. At some point, you see that it is a batch mode Concatenation operator doing the Adaptive Join job and no separate adaptive join iterator.
One more interesting thing is a new iterator AdaptiveBufReader. If we set a breakpoint in the debugger on the method CQScanAdaptiveBufReader:: GetRow – we will hit it.
For example, for this query, we will hit it 7 times (6 rows + one more time to make sure there are no more rows):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
alter database scoped configuration clear procedure_cache; go declare @SalesOrderID int = 43664 select sum(soh.SubTotal) from Sales.SalesOrderHeader soh join Sales.SalesOrderDetail sod on soh.SalesOrderID = sod.SalesOrderID where soh.SalesOrderID <= @SalesOrderID option(optimize for(@SalesOrderID = 1000000)) go |
The plan is:
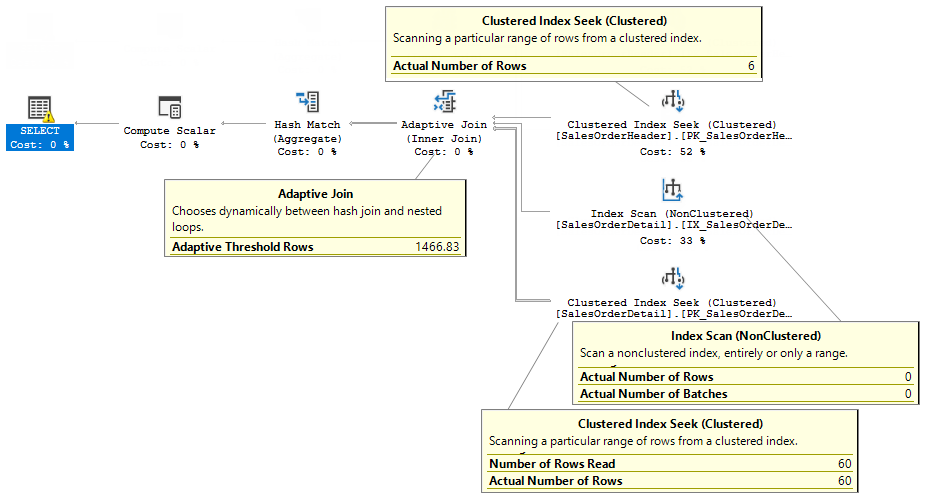
Adaptive Threshold is 1466 rows, however, the actual number of rows in the input is 6 rows and it is less than a threshold. Which is why Index Scan produced no rows, but the second branch with a Clustered Index Seek produced 60 rows.
As it was said earlier in the post, the input is not read twice from the source (SalesOrderHeader table), it is read from the internal structure, this structure was defined as a spool in the operator tree, but undercover it is called differently and has different properties – Adaptive Buffer Reader. But the physical operator is still Concatenation.
That’s all for that post. Thank you for reading!
Table of contents

Currently he works as a database developer lead, responsible for the development of production databases in a media research company. He is also an occasional speaker at various community events and tech conferences. His favorite topic to present is about the Query Processor and anything related to it. Dmitry is a Microsoft MVP for Data Platform since 2014.
View all posts by Dmitry Piliugin
- SQL Server 2017: Adaptive Join Internals - April 30, 2018
- SQL Server 2017: How to Get a Parallel Plan - April 28, 2018
- SQL Server 2017: Statistics to Compile a Query Plan - April 28, 2018