
Nowadays a lot of developers use Object-Relational Mapping (ORM) frameworks. ORM is a programming technique that maps data from an object-oriented to a relational format, i.e. it allows a developer to abstract from a relational database (SQL Server, for example), use object-oriented language (C#, for example) and let an ORM to do all the “talks” to a database engine by generating query texts automatically. ORMs are not perfect, especially if they are used in a wrong way. Sometimes they generate inefficient queries, e.g. a query with redundant expressions. SQL Server has a mechanism to struggle with that inefficiency called a query simplification.
Query simplification is a pre-optimization phase that is run during the query compilation, but before the actual optimization search is started. During that phase the optimizer applies simplification rules against a query tree. The simplification rule represents an algorithm that transforms some portion of a query tree or the whole tree into a simpler form. In this post, we will talk about the new optimizer rule in SQL Server 2017 – CollapseIdenticalScalarSubquery.
Collapsing Subqueries
I have tried different variants of scalar subqueries to make this rule work, but fortunately, the optimizer team was kind enough to guide me – a query pattern for this rule is:
|
1 |
SELECT CASE WHEN EXISTS (subquery) THEN … END, CASE WHEN EXISTS (the same subquery) |
I asked myself, who may write a query like this, and I think the answer might be an ORM.
Let’s look at the example. We run three queries, the first query is under compatibility level of 2016 (130), the second one under 2017 (140), the third also under 2017, but with the rule CollapseIdenticalScalarSubquery turned off.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
use [Adventureworks2016CTP3]; go -- Query under Compatibility Level 2016 alter database [Adventureworks2016CTP3] set compatibility_level = 130; go set showplan_xml on; go select case when exists (select * from Sales.SalesOrderDetail f where f.SalesOrderID= d.SalesOrderID) then 1 else 0 end, case when exists (select * from Sales.SalesOrderDetail f where f.SalesOrderID = d.SalesOrderID) then 2 else 3 end from Sales.SalesOrderHeader d; go set showplan_xml off; go -- Query under Compatibility Level 2017 alter database [Adventureworks2016CTP3] set compatibility_level = 140; go set showplan_xml on; go select case when exists (select * from Sales.SalesOrderDetail f where f.SalesOrderID= d.SalesOrderID) then 1 else 0 end, case when exists (select * from Sales.SalesOrderDetail f where f.SalesOrderID = d.SalesOrderID) then 2 else 3 end from Sales.SalesOrderHeader d; go -- Query under Compatibility Level 2017 with turned off Rule CollapseIdenticalScalarSubquery select case when exists (select * from Sales.SalesOrderDetail f where f.SalesOrderID= d.SalesOrderID) then 1 else 0 end, case when exists (select * from Sales.SalesOrderDetail f where f.SalesOrderID = d.SalesOrderID) then 2 else 3 end from Sales.SalesOrderHeader d option(queryruleoff CollapseIdenticalScalarSubquery); go set showplan_xml off; go |
The plans are accordingly:
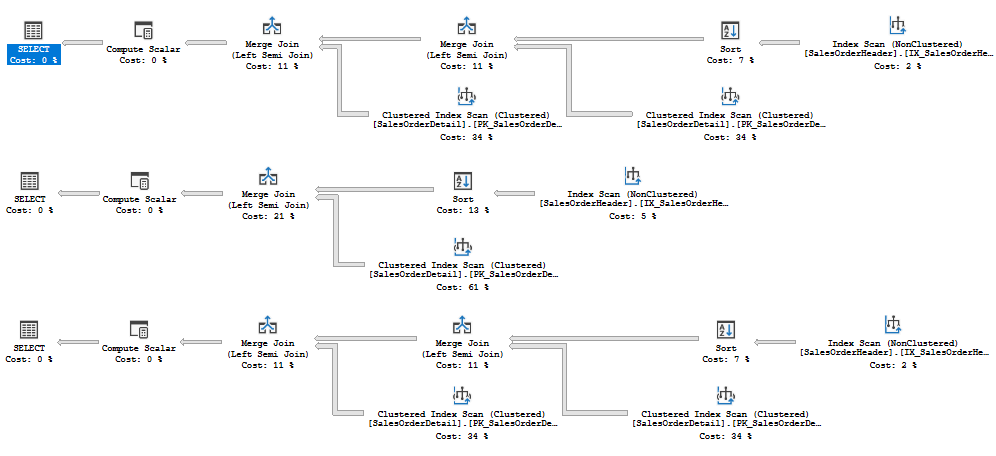
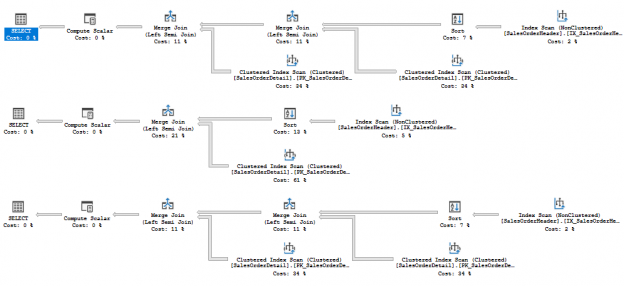
You may see that in the first plan, there are two clustered index scans of the table SalesOrderDetail, however the subquery is exactly the same “exists (select * from Sales.SalesOrderDetail f where f.SalesOrderID = d.SalesOrderID)” but referenced twice.
In the second case, compiled under next compatibility level, the double reference of the subquery is collapsed and we see only one reference to the SalesOrderDetails table and more efficient plan, despite the query still has two subqueries with SalesOrderDetails.
In the third case, also compiled under 2017 level, we see the second branch with the SalesOrderDetail again, but that is because we turned off the rule CollapseIdenticalScalarSubquery with an undocumented hint queryruleoff (which I originally described in my blog post).
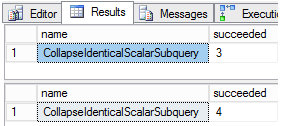
If you look into the DMV sys.dm_exec_query_transformation stats, you will see the succeed counter has increased after the rule was used during the query compilation:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
select name, succeeded from sys.dm_exec_query_transformation_stats where name = 'CollapseIdenticalScalarSubquery' go use [Adventureworks2016CTP3]; go -- Query under Compatibility Level 2016 alter database [Adventureworks2016CTP3] set compatibility_level = 140; go set statistics xml on; select case when exists (select * from Sales.SalesOrderDetail f where f.SalesOrderID= d.SalesOrderID) then 1 else 0 end, case when exists (select * from Sales.SalesOrderDetail f where f.SalesOrderID = d.SalesOrderID) then 2 else 3 end from Sales.SalesOrderHeader d option(recompile); set statistics xml off; go select name, succeeded from sys.dm_exec_query_transformation_stats where name = 'CollapseIdenticalScalarSubquery' go |
The result is:

|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
use [AdventureworksDW2016CTP3] go alter database [AdventureworksDW2016CTP3] set compatibility_level = 140; go set showplan_xml on; go select case when exists (select * from dbo.FactResellerSales f where f.DueDate = d.DateKey) then 1 else 0 end, case when exists (select * from dbo.FactResellerSales f where f.DueDate = d.DateKey) then 2 else 3 end from dbo.DimDate d go set showplan_xml off; go |
The plan is:

The plan uses FactResellerSales table twice and do not benefit from the new simplification rule. Probably, this functionality will be evolved in the future, but nowadays it works in this way.
Conclusion
Unfortunately, this rule also does not solve a quite popular problem, that was described by Erland Sommarskog on the Connect site: Unnecessarily bad performance for coalesce(subquery), however, I hope that, as far as Microsoft invests some time to this kind of problems, the problem from the Connect site might be addressed in future.
That’s all for today, thank you for reading and stay tuned!
Table of contents

Currently he works as a database developer lead, responsible for the development of production databases in a media research company. He is also an occasional speaker at various community events and tech conferences. His favorite topic to present is about the Query Processor and anything related to it. Dmitry is a Microsoft MVP for Data Platform since 2014.
View all posts by Dmitry Piliugin
- SQL Server 2017: Adaptive Join Internals - April 30, 2018
- SQL Server 2017: How to Get a Parallel Plan - April 28, 2018
- SQL Server 2017: Statistics to Compile a Query Plan - April 28, 2018