
In this post, we are going to look at the new feature in SQL Server 2017 – interleaved execution. You need to install SQL Server 2017 CTP 1.3 to try it, if you are ready, let’s start.
Now, when a CTP 2.0 of SQL Server 2017 is out, you don’t need to turn on the undocumented TF described further, and the plans are also different, so the examples from this post use CTP.1.3, probably not actual at the moment (I was asked to hold this post, until the public CTP 2 is out, and interleaved execution is officially announced). However, the post demonstrates Interleaved execution details and might be still interesting.
T-SQL Multistatement Table-valued Function
Function is a convenient way to decompose program logic and reduce a code complexity. However, T-SQL functions in SQL Server may lead to some problems with the performance.
There are three types of T-SQL functions in SQL Server (excluding In-Memory OLTP and CLR):
- Transact-SQL Inline Table-Valued Function
- Transact-SQL Scalar Function
- Transact-SQL Multistatement Table-valued Function
Inline Table-Valued Function could contain only one root SELECT statement that is used to describe its result, to keep it simple, we may say that this is a parameterized and named subquery. This is good from an optimization prospective, because the Query Optimizer may inline a function’s text into a query and optimize a query as a whole. That means it can do a lot of optimization tricks as well as estimate cardinality much better. That type of function used to be recommended for the most cases. However, it cannot contain any flow control operators, declarations or other procedural language elements.
Two other types of functions can contain procedural language elements and may implement more complex logic. We’ll leave scalar functions alone, because it is not the topic of this post, and focus on Multistatement table-valued functions (mTVF).
The fact that mTVF can implement complex procedural logic makes it more powerful for the code reuse, however more challenging from the optimization prospective. It is hard or impossible to estimate how many rows a function will return, i.e. estimate cardinality, before you start executing it, but cardinality estimation is crucial during the query compilation if you want to get an adequate plan.
In SQL Server 2012 and earlier, mTVF had a fixed estimate of 1 row, which sometimes lead to inefficient query plans. Starting from SQL Server 2014 the estimate was increased up to 100 rows but was still fixed.
Regular mTVF Execution
To demonstrate the estimation problem, we will use SQL Server 2017 CTP 1.3 and a sample AdvertureWorksDW database under the compatibility level (CL) 130.
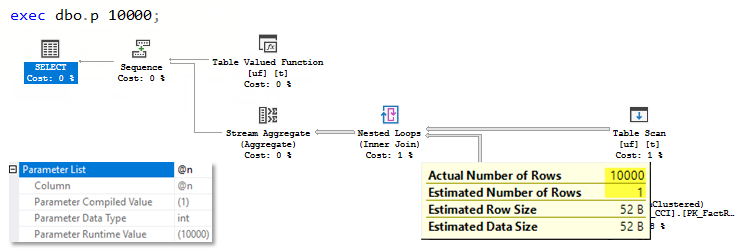
We create a test mTVF function, that populates top N rows in its result table depending on the parameter @n, and join it with a table that has a clustered Columnstore index.
Let’s clear a procedure cache, include actual execution plan and run the query:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
use AdventureworksDW2016CTP3; go -- Set compatibility level of SQL Server 2016 alter database AdventureworksDW2016CTP3 set compatibility_level = 130; go -- Create multistatement table-valued function create or alter function dbo.uf(@n int) returns @t table(SalesOrderNumber nvarchar(40), SalesOrderLineNumber tinyint) with schemabinding as begin insert @t(SalesOrderNumber, SalesOrderLineNumber) select top(@n) SalesOrderNumber, SalesOrderLineNumber from dbo.FactResellerSalesXL_CCI; return; end go -- Clear procedure cache for DB alter database scoped configuration clear procedure_cache; go -- Run the query with mTVF set statistics xml on; select c = count_big(*) from dbo.FactResellerSalesXL_CCI c join dbo.uf(10000) t on t.SalesOrderNumber = c.SalesOrderNumber and t.SalesOrderLineNumber = c.SalesOrderLineNumber ; set statistics xml off; go |
We see the following query plan:
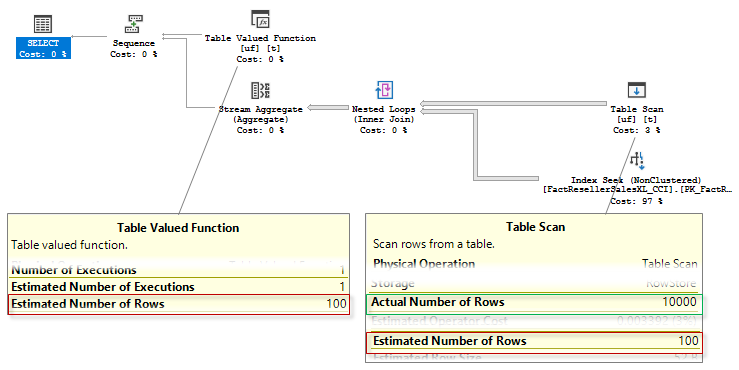
You see that a mTVF cardinality as well as the cardinality of the mTVF result table scan is estimated as 100 rows, as we have said earlier, this is a fixed estimate starting from 2014 (you may try USE HINT (‘FORCE_LEGACY_CARDINALITY_ESTIMATION’) to force the estimate before 2014 and observe 1 row estimate), but actually there were 10 000 rows.
Option RECOMPILE to Fix the Estimate
You may know that adding a query hint RECOMPILE to a query with a table variable allows the optimizer to sniff the actual number of rows and use this number to fix the cardinality estimate, see the following article for more details.
We may add the query hint to the query inside the mTVF or to the query itself, or to the both of them. Let’s try both of them.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
-- Create multistatement table-valued function create or alter function dbo.uf(@n int) returns @t table(SalesOrderNumber nvarchar(40), SalesOrderLineNumber tinyint) with schemabinding as begin insert @t(SalesOrderNumber, SalesOrderLineNumber) select top(@n) SalesOrderNumber, SalesOrderLineNumber from dbo.FactResellerSalesXL_CCI option(recompile); return; end go -- Clear procedure cache for DB alter database scoped configuration clear procedure_cache; go -- Run the query with mTVF set statistics xml on; declare @n int = 10001 select c = count_big(*) from dbo.FactResellerSalesXL_CCI c join dbo.uf(10000) t on t.SalesOrderNumber = c.SalesOrderNumber and t.SalesOrderLineNumber = c.SalesOrderLineNumber option(recompile) ; set statistics xml off; go |
Unfortunately, the plan and estimates are the same:
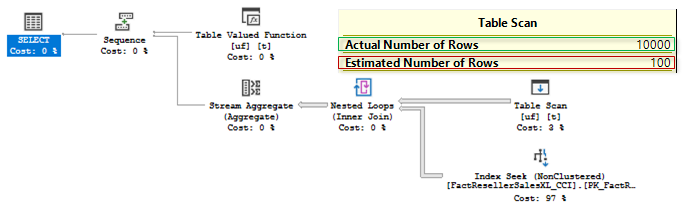
We can see that a regular trick with an OPTION (RECOMILE) is not helpful in this case. SQL Server 2017 may address this problem from the other angle under certain conditions.
Interleaved Execution
The idea of interleaved execution is to take a part of a query that might be executed independently, execute it, and then reuse the result and the result cardinality to recompile and execute the rest of the query. A good candidate for such approach is an mTVF that might be executed independently of the rest of a query, so it is taken as a first step in implementing the interleaved execution in a current CTP version of SQL Server 2017.
To enable interleave execution in CTP 1.3 we should use an undocumented trace flag 11005, starting from CTP 2.0 we only need to switch DB CL to 140 (and the TF disables interleaved execution). Under the CL level 140, I’ll also use an undocumented query hint DISABLE_BATCH_MODE_ADAPTIVE_JOINS, to avoid adaptive join in a query plan, because it will be a topic for the next blog post.
Let’s return function to the original state (without option recompile) and see, how the query plan will change if the interleaved execution feature is enabled.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
alter database AdventureworksDW2016CTP3 set compatibility_level = 140; go -- Create multistatement table-valued function create or alter function dbo.uf(@n int) returns @t table(SalesOrderNumber nvarchar(40), SalesOrderLineNumber tinyint) with schemabinding as begin insert @t(SalesOrderNumber, SalesOrderLineNumber) select top(@n) SalesOrderNumber, SalesOrderLineNumber from dbo.FactResellerSalesXL_CCI; return; end go -- Clear procedure cache for DB alter database scoped configuration clear procedure_cache; go -- Run the query with mTVF set statistics xml on; select c = count_big(*) from dbo.FactResellerSalesXL_CCI c join dbo.uf(10000) t on t.SalesOrderNumber = c.SalesOrderNumber and t.SalesOrderLineNumber = c.SalesOrderLineNumber option(use hint('DISABLE_BATCH_MODE_ADAPTIVE_JOINS')) -- disable adaptive join ; set statistics xml off; go |
The plan is now different:
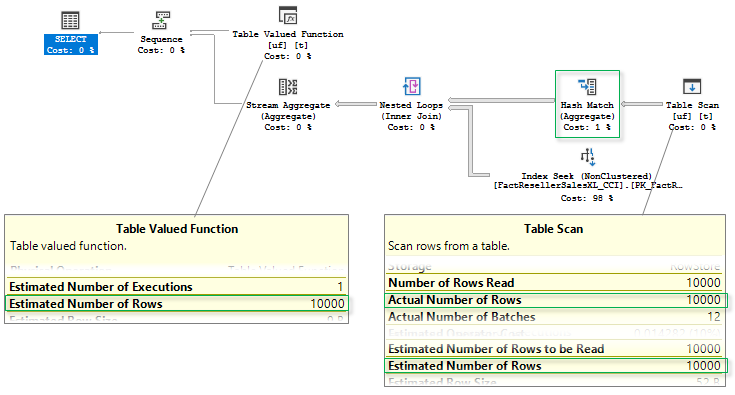
First of all, note that Estimated Number of Rows is 10 000 now, which is correct and equals Actual Number of Rows. Due to the correct estimate, the optimizer decided that there are enough rows to benefit from a partial (local/global) aggregation and introduced a partial Hash aggregate before the join.
If you take a Profiler, enable events SP:StmtStarting, SP:StmtCompleted, SQL:StmtStarting, SQL:StmtCompleted and run the query without and with a TF, you’ll see what does it actually mean “interleaved” in terms of the execution sequence.
During the regular execution the query starts executing, then the function is executed, the query continues execution and finishes the execution. We see the following event sequence:

During the interleaved execution, we see the following sequence:
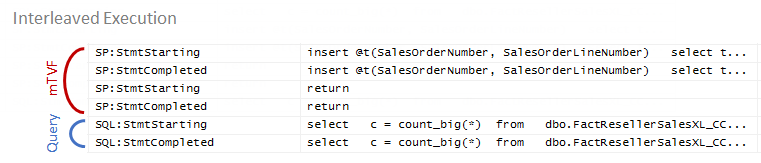
The execution of the mTVF and the query is interleaved, at first mTVF is executed, and then the query starts execution and reuses the mTVF result.
Interleaved Execution Process
To look at the interleaved execution process in more details, we will use extended events. We enable the following known extended events:
- query_post_compilation_showplan – Occurs after a SQL statement is compiled. This event returns an XML representation of the estimated query plan that is generated when the query is compiled.
- query_post_execution_showplan – Occurs after a SQL statement is executed. This event returns an XML representation of the actual query plan.
- sp_cache_insert – Occurs when a stored procedure is inserted into the procedure cache.
- sp_cache_miss – Occurs when a stored procedure is not found in the procedure cache.
- sp_statement_starting – Occurs when a statement inside a stored procedure has started.
- sp_statement_completed – Occurs when a statement inside a stored procedure has completed.
- sql_batch_starting – Occurs when a Transact-SQL batch has started executing.
- sql_batch_completed – Occurs when a Transact-SQL batch has finished executing.
- sql_statement_starting – Occurs when a Transact-SQL statement has started.
- sql_statement_completed – Occurs when a Transact-SQL statement has completed.
- sql_statement_recompile – Occurs when a statement-level recompilation is required by any kind of batch.
And some new extended events related to an interleaved execution in particular.
- interleaved_exec_stats_update – Event describe the statistics updated by interleaved execution.
- estimated_card – Estimated cardinality
- actual_card – Updated actual cardinality
- estimated_pages – Estimate pages
- actual_pages – Updated actual pages
- interleaved_exec_status – Event marking the interleaved execution in QO.
- operator_code – Op code of the starting expression for interleaved execution.
- event_type – Whether this is a start of the end of the interleaved execution
- time_ticks – Time of this event happens
- recompilation_for_interleaved_exec – Fired when recompilation is triggered for interleaved execution.
- current_compile_statement_id – Current compilation statement’s id in the batch.
- current_execution_statement_id – Current execution statement’s id in the batch.
I have also added a few additional columns: event_sequence, session_id and sql_text, and a filter by session_idequals SPID. The full script of the session definition is provided at the end of the post.
Let’s clear DB cache, turn on the session, click “Watch Live Data” in SSMS, run previous query, then stop the session and look what do we have in a Live data grid (I have chosen 5 columns to be displayed in the grid: event_sequence, name, object_type, sql_text and statement for sql_statement_… event, the rest of the columns will be available in the event details below).
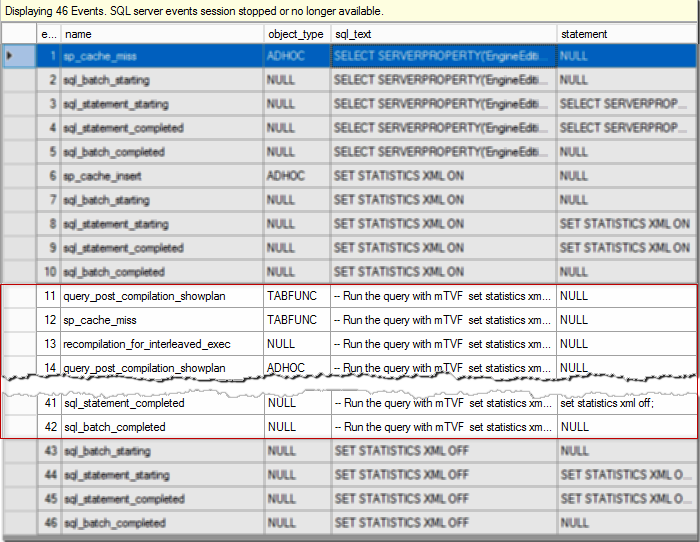
First 10 events and last 4 events are not interesting for us here, they are fired because SSMS issue some commands internally to run the query, get a plan, etc. We will focus on the events from 11 to 42 and look at them step by step in details to see what’s going on.
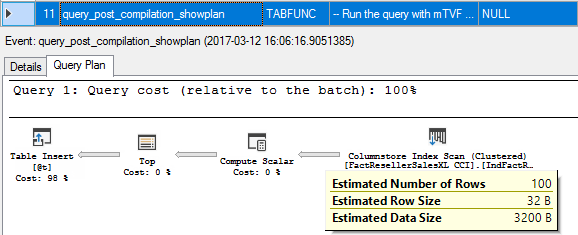
11. query_post_compilation_showplan
We start compiling our batch with compiling our mTVF. Note the estimated number of rows is 100.
12. sp_cache_miss
We have cleared the procedure cache before running the query so there is no plan for the mTVF and we see a cache miss.

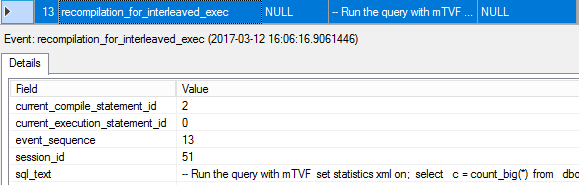
13. recompilation_for_interleaved_exec
SQL Server recognized that there is an mTVF in the batch, it might be executed independently of the rest of the query and the query is executed under a TF that enables interleaved execution, so the query may benefit from it and the optimizer marks the statement for recompilation.
14. query_post_compilation_showplan
SQL Server tries to compile our query; however, it is marked for a recompilation due to the interleaved execution on the previous step, so it inserts a kind of a plan stub instead of fully compiling the query.
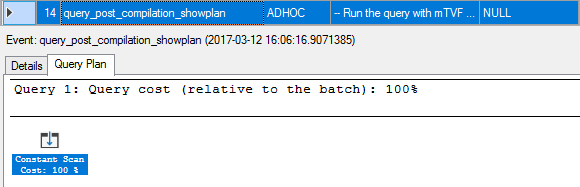
You may identify that this is a plan for our select query statement if you look into the event details offset columns.
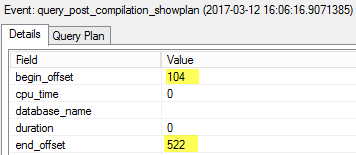
Number 104 is the position when our select statement starts and 522 is the position where it ends.
15. sp_cache_insert
This plan stub is also inserted into a cache. Now we have our batch compiled and may start executing it.

16. sql_batch_starting
Starting execution of the batch.

17, 18. sql_statement_starting, sql_statement_completed
These events are fired because of the execution of the first statement in our batch, which sets a statistics xml mode on.

19. sql_statement_starting
Now we start executing the second statement in the batch – our query. Note the offsets of the statement, 104 and 522, we have seen them already, when a plan stub for the statement was created.
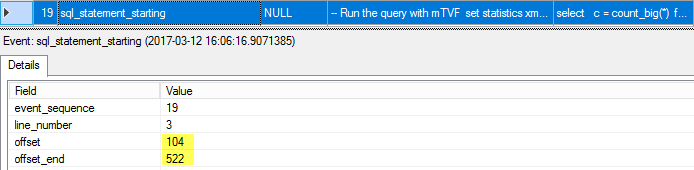
20. sql_statement_recompile
We still have no plan for the statement (because it was marked for the interleaved execution at step 13), but only a plan stub, we need to recompile a statement. Note the reason for the recompilation – it is an “Interleaved execution required recompilation”.
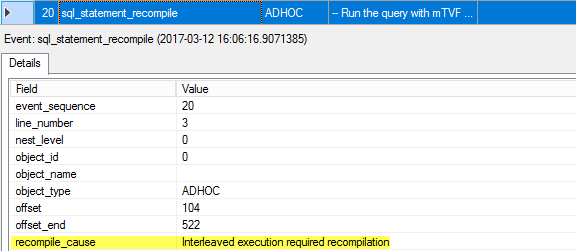
21. query_post_compilation_showplan
At first, we recompile the mTVF module and we see the compiled plan, the estimated number of rows is 100.
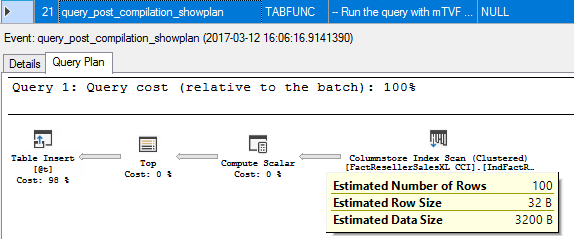
22. sp_cache_miss
New recompiled plan is not cached, so there is a cache miss for table function.

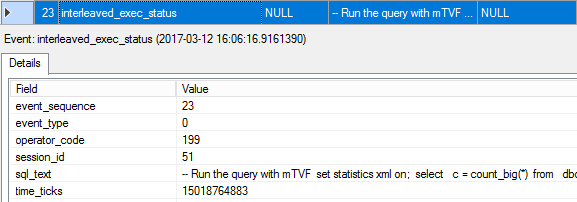
23. interleaved_exec_status
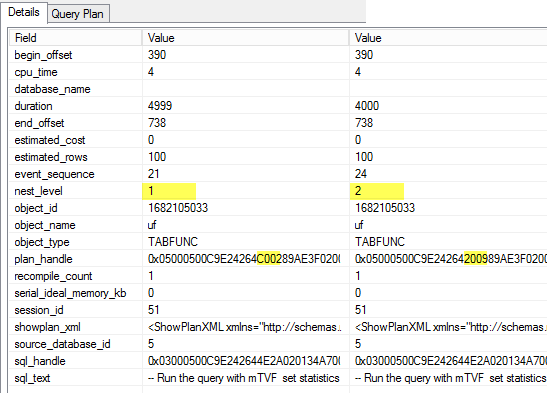
This is the event that is marking the interleave execution; note the event type is 0, which stands for start interleaved execution. The operator_code is the internal class number, 199 stands for mTVF.
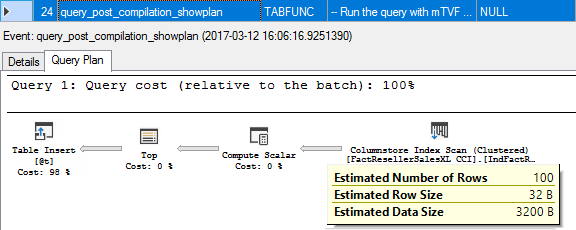
24. query_post_compilation_showplan
Identical plans, but different details: nest_level and a plan_handle.
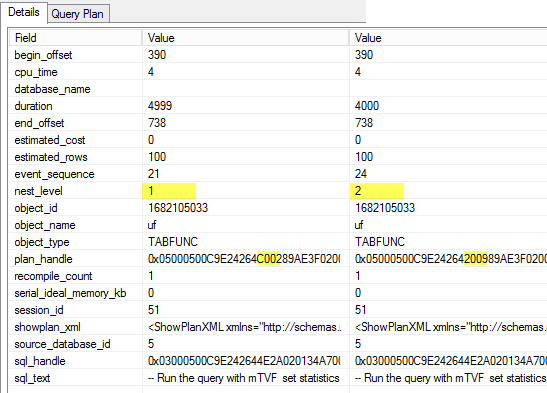
25. sp_cache_miss
There is no such plan in the cache also.

26. query_post_compilation_showplan
Finally, we have a plan that is compiled with a sniffed value 10 000 due to a recompilation, note the number of estimated rows is now 10 000. This plan is used for the mTVF execution, but the value 10 000 from this plan is not used to optimize the rest of the query, because a post execution plan with an actual cardinality is used for that purpose.
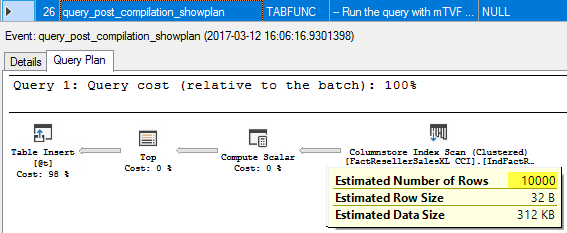
27. sp_cache_insert
This plan is cached for a later reuse.

28. sp_statement_starting
At this point, we have a plan for the mTVF and ready to execute it. The first statement in mTVF is an INSERT statement and it starts executing.

29. query_post_execution_showplan
The first statement of mTVF is executed and we see an actual, post execution plan with an actual number of rows. The actual number of rows for Columnstore Index Scan is slightly more than 10 000, which is because it is executed in a Batch Mode, there are 12 batches (you may see it in the plan), each batch may be up to 900 rows, and so 900*12 gives us 10800. That is not a problem, because the Top operator will take only first 10 000 and insert them in the result table.
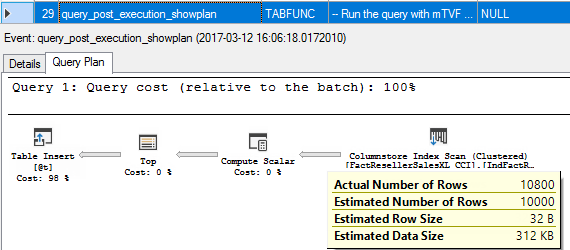
30. sp_statement_completed
The execution of the first statement of the mTVF is completed.

31, 32. sp_statement_starting, sp_statement_completed
The second statement in the mTVF is a RETURN statement. It is executed so we see the “starting” and “completed” events.

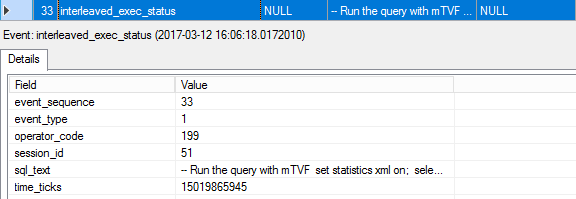
33. interleaved_exec_status
One more event about the interleaved execution status is fired; the event_type equals 1, which stands for “ready to execute the main query”.
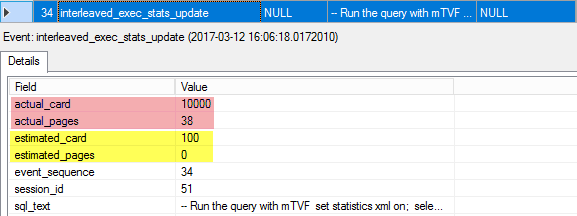
34. interleaved_exec_stats_update
This event describes the statistics that was updated for the interleaved execution. You may see the initial estimated cardinality and the number of pages, as well as the actual number of rows and pages. Those actual values will be used to optimize the rest of the query.
35. query_post_compilation_showplan
The plan for the rest of the query is compiled, note this is a post compilation plan, but it has 10 000 rows estimate for the mTVF and the result table scan.

36. sql_statement_starting
At this point we have a compiled plan for the whole query and we are ready to start executing the rest of the query. Note, the mTVF is not executed the second time, the results saved to the mTVF table are reused. Also, note that a state of the query is “Recompiled”, because it was marked for recompilation due to the interleaved execution (step 13).
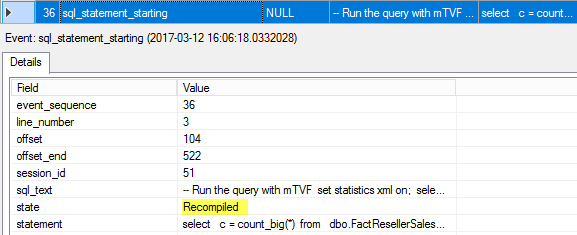
37. interleaved_exec_status
We saw the interleaved status event the last time in this execution; the event_type is 2, which says that the interleaved execution has finished.
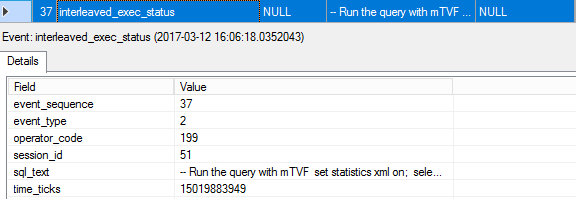
38. query_post_execution_showplan
Finally, we get a post execution actual plan of the whole query.
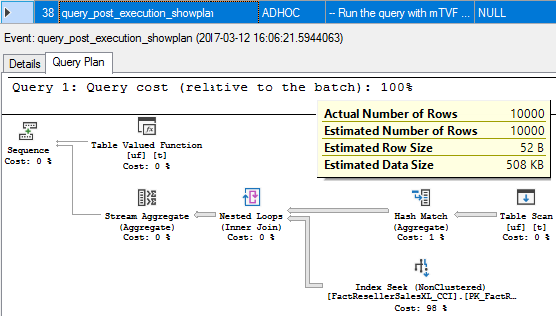
39, 40, 41, 42. sql_statement_completed, sql_statement_starting, sql_statement_completed, sql_batch_completed
The last events fired for the query completed, “set statistics xml off” completed and the whole batch is completed.

Actual Cardinality is taken
I would like to repeat the idea of the interleaved execution one more time; we take an actual cardinality from the part of the query. We have seen the event interleaved_exec_stats_update at the step 34, which showed us that operator statistics was updated.
However, the estimated number of rows in the post compilation plan at the step 29 is also 10 000, so I’d like to take one more experiment to see that an actual cardinality was really picked for the query optimization. For that purpose, let’s introduce an expression in a Top operator, which includes some calculation, for example like this.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
-- Create multistatement table-valued function create or alter function dbo.uf(@n int) returns @t table(SalesOrderNumber nvarchar(40), SalesOrderLineNumber tinyint) with schemabinding as begin insert @t(SalesOrderNumber, SalesOrderLineNumber) select top(@n + datepart(ms,getdate())) SalesOrderNumber, SalesOrderLineNumber from dbo.FactResellerSalesXL_CCI; return; end go |
In that case, the Top expression with a runtime constant function GETDATE prevents the optimizer from estimating the correct number of rows, if you rerun the query with the extended events trace enabled, you will see the post compilation query plan difference at the step 26, it is now 100 rows guess estimate.
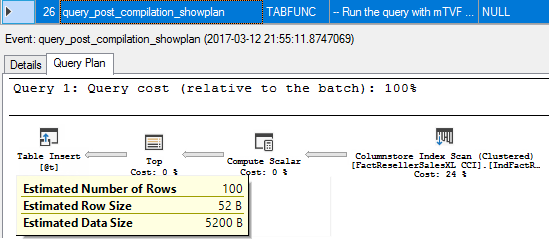
When the function is executed and there is a post execution plan (step 29), you may see that the Top expression is calculated and some value (876) is added to a 10 000 constant, so you see the actual number of rows is now 10 876, though, the estimated is 100.
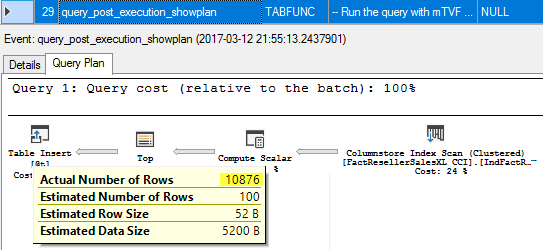
If you then look at the post execution plan (step 38) for the whole query, you will see, that an actual number of rows is 10 876, but the estimated number of rows is also 10 876, which means 10 876 was really used to estimate a cardinality.
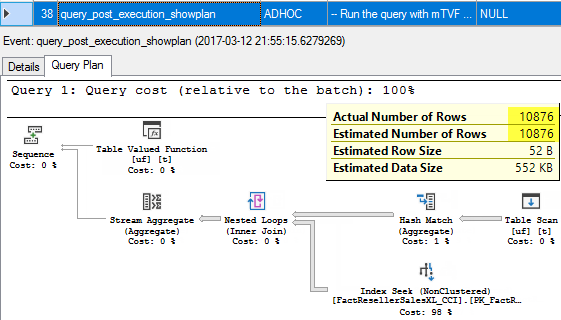
If you run the query a couple of times, each time you will see the new estimated value, depending, on what second’s portion is added to a top expression and what is the actual number of rows in the mTVF plan. As we can see the actual number of rows from the function is really used to estimate cardinality.
Correlated Parameters
Let’s introduce some correlated parameters in our function and provide values from the outer query.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
-- Create multistatement table-valued function create or alter function dbo.uf(@n int, @SalesOrderNumber nvarchar(40)) returns @t table(SalesOrderNumber nvarchar(40), SalesOrderLineNumber tinyint) with schemabinding as begin insert @t(SalesOrderNumber, SalesOrderLineNumber) select top(@n) SalesOrderNumber, SalesOrderLineNumber from dbo.FactResellerSalesXL_CCI where SalesOrderNumber = @SalesOrderNumber; return; end go -- Clear procedure cache for DB alter database scoped configuration clear procedure_cache; go -- Run the query with mTVF set statistics xml on; select c = count_big(*) from dbo.FactResellerSalesXL_CCI c cross apply dbo.uf(5, c.SalesOrderNumber) t where c.DueDate > '20150101' ; set statistics xml off; go |
You may see, the plan shape is different now.
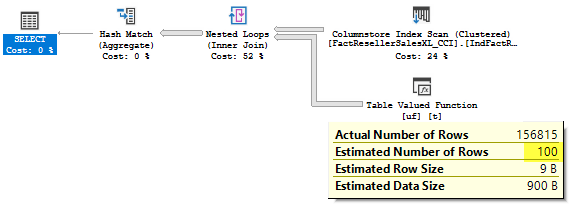
We don’t have a Sequence operator any more, the part of the query can’t be executed independently and there is no interleaved execution and no interleaved execution extended events. In the current version of SQL Server 2017, this query pattern is not supported.
Parameter Sniffing
To look at how the interleaved execution works with parameters we make a simple procedure and put our query inside it.
|
1 2 3 4 5 6 7 8 9 10 11 |
-- Procedure with the query with mTVF and enabled interleaved execution create or alter proc dbo.p (@n int) as select c = count_big(*) from dbo.FactResellerSalesXL_CCI c join dbo.uf(@n) t on t.SalesOrderNumber = c.SalesOrderNumber and t.SalesOrderLineNumber = c.SalesOrderLineNumber option(use hint('DISABLE_BATCH_MODE_ADAPTIVE_JOINS')) -- disable adaptive join ; go |
Now let’s clear procedure cache, run this procedure with different parameters and look at the query plans.
|
1 2 3 4 5 6 7 |
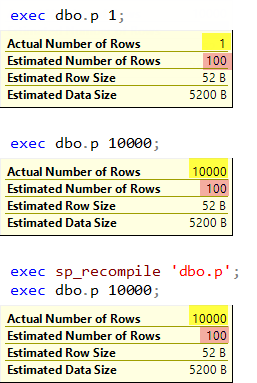
set statistics xml on; exec dbo.p 1; exec dbo.p 10000; exec sp_recompile 'dbo.p'; exec dbo.p 10000; set statistics xml off; go |
During the first execution, there was no plan in the cache so the procedure was compiled. The parameter value 1 was sniffed and then used during the interleaved execution. You may see that Estimated Number of Rows equals Actual Number of rows and equals 1 row.
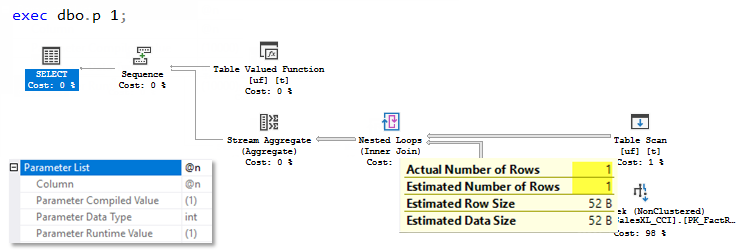
During the second execution, the plan is already cached and it is simply reused without any recompilation and interleaved execution. You may observe the Actual Number of Rows is 10 000, while the Estimated Number of Rows is still 1 row and the plan has no partial Hash aggregate.
When we marked the procedure for a recompilation and executed it, the recompilation and the interleaved execution occurred, the new value 10 000 was sniffed and used to optimize the query. You may see the actual and the estimated number of rows equals 10 000 and we see a Hash aggregate in the plan.

This example shows that interleaved execution uses sniffed parameter value during the compilation. That means that a bad parameter sniffing problem applies to the interleaved execution as well, as to the other cases also.
Disabling Parameter Sniffing
Now let’s try to disable parameter sniffing, we have several ways to do this:
- Query hint USE HINT (‘DISABLE_PARAMETER_SNIFFING’)
- Query hint OPTIMIZE FOR UNKNOWN or value
- Trace Flag 4136
- Disabling at the DB level with a SCOPED CONFIGURATION options
Let’s modify our procedure and add a USE HINT to the query.
|
1 2 3 4 5 6 7 8 9 10 11 |
-- Procedure with the query with mTVF, enabled interleaved execution and disabled parameter sniffing create or alter proc dbo.p (@n int) as select c = count_big(*) from dbo.FactResellerSalesXL_CCI c join dbo.uf(@n) t on t.SalesOrderNumber = c.SalesOrderNumber and t.SalesOrderLineNumber = c.SalesOrderLineNumber option(use hint ('DISABLE_BATCH_MODE_ADAPTIVE_JOINS','disable_parameter_sniffing')) ; go |
If we rerun procedures from the previous step, we’ll see that the estimate is 100 rows guess in all three cases (I’ll post only the estimates of the mTVF table scan from the plans to save space).
Also, if you enable an extended events trace you will not see any interleaved execution events.
The same behavior is for all the other options, all of them disable interleaved execution, even if you write, for example, option (optimize for (@n = 5000)) – the estimated number of rows would be 100 and there will be no interleaved execution.
Interesting to note, that disabling interleaved execution with all these methods also works if you take a query out of a stored procedure.
Option Recompile
As a final step, we will find out, how the interleaved execution works with a RECOMPILE hint. Again, we will modify our stored procedure and run it with the different parameter values.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
create or alter proc dbo.p (@n int) as select c = count_big(*) from dbo.FactResellerSalesXL_CCI c join dbo.uf(@n) t on t.SalesOrderNumber = c.SalesOrderNumber and t.SalesOrderLineNumber = c.SalesOrderLineNumber option(recompile, use hint ('DISABLE_BATCH_MODE_ADAPTIVE_JOINS')) ; go -- Clear procedure cache for DB alter database scoped configuration clear procedure_cache; go -- Run procedure with different parameters set statistics xml on; exec dbo.p 1; exec dbo.p 1000; exec dbo.p 10000; set statistics xml off; go |
The estimates of the mTVF table scan from the plans are:

As you can see, the estimates equal actual and you may also observe interleaved extended events every time you run a procedure, so the option RECOMPILE works nicely with the interleaved execution.
As my last experiment with option RECOMPILE I tried to pass a 0 value as a parameter. You may probably know, that if you run a query, for example: “declare @n int = 0; select top (@n) * from dbo. FactResellerSalesXL_CCI option (recompile);” – the value 0 will be embedded into the query and optimized as a top (0), and top (0) will be simplified out by the optimizer at the simplification stage of the query compilation. As a result, you will get a simple “Constant Scan” plan, and that’s it. Unfortunately, this doesn’t work in this case (even if you add an option recompile inside a function also).
Other Questions
A few other questions that have come to my mind while experimenting with this new feature. I tested them, but won’t post the scripts, because I don’t want to make this long post even longer.
Should be a function defined with schema_binding?
No, not necessary.
Are there any other operators available for the interleave execution?
No, the first implementation of the interleaved execution includes only mTVF.
Will it work with a table variable?
No, however, for better cardinality estimation of a table variable you may use a regular approach, like option RECOMPILE or trace flag 2453.
Will it work in a Row Mode?
Yes, it works in a Row, Batch or mixed mode.
Conclusion
The Query Processor of SQL Server is getting smarter from version to version; in this post, we have tried a new feature – interleaved execution, which is a part of the adaptive query processing features family. I believe this feature will increase performance of existing solutions with mTVFs and make mTVF functions more usable in terms of performance in general. Will look at how this approach will evolve in future, probably for some other operators.
I would like to thank Joe Sack from MSFT (t) for reviewing this post and providing invaluable help.
Thank you for reading!
Table of contents

Currently he works as a database developer lead, responsible for the development of production databases in a media research company. He is also an occasional speaker at various community events and tech conferences. His favorite topic to present is about the Query Processor and anything related to it. Dmitry is a Microsoft MVP for Data Platform since 2014.
View all posts by Dmitry Piliugin
- SQL Server 2017: Adaptive Join Internals - April 30, 2018
- SQL Server 2017: How to Get a Parallel Plan - April 28, 2018
- SQL Server 2017: Statistics to Compile a Query Plan - April 28, 2018