
In this post, we will continue to look at the cardinality estimation changes in SQL Server 2016. This time we will talk about scalar UDF estimation. Scalar UDFs (sUDF) in SQL Server have quite bad performance and I encourage you try to avoid them in general, however, a lot of systems still use them.
Scalar UDF Estimation Change
I’ll use Microsoft sample DB AdventureworksDW2016CTP3 and write the following simple scalar function, it always returns 1, regardless of the input parameter. I run my queries against Microsoft SQL Server 2016 (SP1) (KB3182545) – 13.0.4001.0 (X64)
|
1 2 3 4 5 6 7 8 9 10 11 12 |
use [AdventureworksDW2016CTP3]; go drop function if exists dbo.uf_simple; go create function dbo.uf_simple(@a int) returns int with schemabinding as begin return 1; end go |
Now let’s run two queries, the first one under compatibility level (CL) of SQL Server 2014, the second one under CL 2016 and turn on actual execution plans:
|
1 2 3 4 5 6 7 8 |
alter database [AdventureworksDW2016CTP3] set compatibility_level = 120; go select count_big(*) from dbo.DimDate d where dbo.uf_simple(d.DateKey) = 1; go alter database [AdventureworksDW2016CTP3] set compatibility_level = 130; go select count_big(*) from dbo.DimDate d where dbo.uf_simple(d.DateKey) = 1; go |
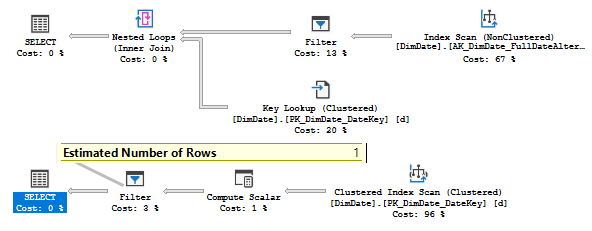
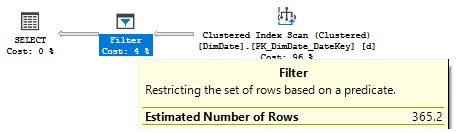
We have got two plans and If we look at them we will see that they are of the same shape, however, if we look at the estimates, we will find some differences in the Filter operator.
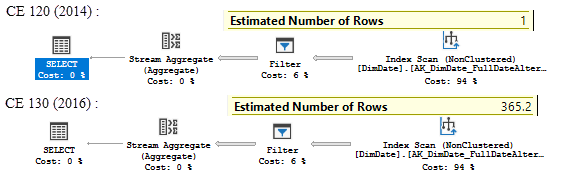
You may notice that in the first case the estimate is 1 row, in the second case the estimate is 365 rows. Why they are different? The point is that MS has changed the estimation algorithm, i.e. the calculator for sUDF estimation.
In 2014 it was a CSelCalcPointPredsFreqBased, the calculator for point predicates based on a frequency (Cardinality*Density). DateKey is a PK and it is unique, the frequency is 1. If you multiply the number of rows 3652 by the all_density column (from the dbcc show_statistics(DimDate, PK_DimDate_DateKey) command) 0.0002738226 you will get one row.
In 2016 the calculator is CSelCalcFixedFilter (0.1) which is a 10% guess of the table cardinality. Our table has 3652 rows and the 10% is 365, which we may observe in the plan.
This change is described here: FIX: Number of rows is underestimated for a query predicate that involves a scalar user-defined function in SQL Server 2014.
You may wonder, why 2014, if we are talking about 2016? The truth is, that the new Cardinality Estimator (CE) was introduced in 2014 and evolved in 2016, but all the latter fixes for the optimizer in 2014 (introduced by Cumulative Updates (CU) or Service Packs (SP)) are protected by TF 4199 as described here, in 2016 all these fixes are included so you don’t need TF 4199 for them, but if have 2014 you should apply TF 4199 to see the described behavior.
Estimation Puzzle
Now, let’s modify our queries and replace count with “select *”. Then turn on the statistics IO, actual plans and run them again:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
alter database [AdventureworksDW2016CTP3] set compatibility_level = 120; go set statistics io on; select * from dbo.DimDate d where dbo.uf_simple(d.DateKey) = 1; set statistics io off; go alter database [AdventureworksDW2016CTP3] set compatibility_level = 130; go set statistics io on; select * from dbo.DimDate d where dbo.uf_simple(d.DateKey) = 1; set statistics io off; go |
The results are:
Table ‘DimDate’. Scan count 1, logical reads 7312
Table ‘DimDate’. Scan count 1, logical reads 59
That’s a great difference in the logical reads, and we may see why, if we look at the query plans:
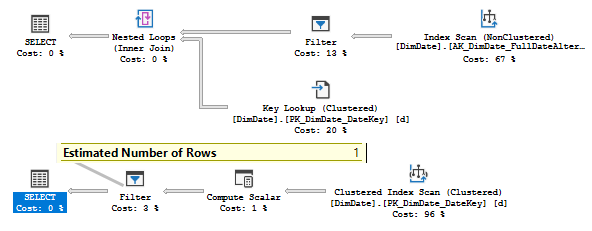
If we remember, for the CE 120 it was a one row estimate, and in this case, server decided, that it is cheaper to use a non-clustered index and then make a lookup into clustered. Not very effective if we remember that our predicate returns all rows.
In CE 130 there was a 365 rows estimate, which is too expensive for key lookup and server decided to make a clustered index scan.
But, wait, what we see is that in the second plan the estimate is also 1 row!
That fact seemed to me very curious and that’s why I’m writing this post. To find the answer, let’s look in more deep details at how the optimization process goes.
Explanation
The optimization process is split by phases, before the actual search of the plan alternatives starts, there are a couple of preparation phases, one of them is Project Normalization. During that phase, the optimizer matches computed columns with their definition or deals with other relational projections in some way. For example, it may move a projection around the operator’s tree if necessary.
We may see the trees before and after normalization and their cardinality information with a couple of undocumented TFs 8606 and 8612 applied together with a QUERYTRACEON hint, for instance.
For the 2014 CL the relational Select (LogOp_Select) cardinality (which represents a Filter operator in query plan) before project normalization is 1 row:
|
1 2 3 4 5 6 7 |
*** Tree Before Project Normalization *** LogOp_Select [ Card=1 ] LogOp_Get TBL: dbo.DimDate … [ Card=3652 ] ScaOp_Comp x_cmpEq ScaOp_Udf dbo.uf_simple IsDet ScaOp_Identifier QCOL: [d].DateKey ScaOp_Const TI(int,ML=4) XVAR(int,Not Owned,Value=1) |
For 2016 CL, before project normalization, it is 365.2 rows:
|
1 2 3 4 5 6 7 |
*** Tree Before Project Normalization *** LogOp_Select [ Card=365.2 ] LogOp_Get TBL: dbo.DimDate … [ Card=3652 ] ScaOp_Comp x_cmpEq ScaOp_Udf dbo.uf_simple IsDet ScaOp_Identifier QCOL: [d].DateKey ScaOp_Const TI(int,ML=4) XVAR(int,Not Owned,Value=1) |
Which is totally understandable, because we remember, that there is a cardinality estimation change to 10% guess for sUDFs in 2016 CL. However, this estimate is not what we see in the final query plan for the second query, we see 1 row there. Project Normalization is the place where this estimation is introduced.
If we examine the trees after project normalization, we see the following picture (the tree is the same for both queries):
|
1 2 3 4 5 6 7 8 9 10 11 |
*** Tree After Project Normalization *** LogOp_Select LogOp_Project LogOp_Get TBL: dbo.DimDate … [ Card=3652 ] AncOp_PrjList AncOp_PrjEl COL: Expr1001 ScaOp_Udf dbo.uf_simple IsDet ScaOp_Identifier QCOL: [d].DateKey ScaOp_Comp x_cmpEq ScaOp_Identifier COL: Expr1001 ScaOp_Const TI(int,ML=4) XVAR(int,Not Owned,Value=1) |
You may notice a new Project operator, that converts our sUDF uf_simple to an expression Expr1001, projects it further to the tree upper node and over this projection, the relational Select should filter out the rows, i.e. we are now filtering on the expression, not on the sUDF directly.
The optimizer doesn’t know the cardinality for that new Select operator and the estimation process starts. The thing is that filtering over such an expression is unchanged both under 2014 CL and 2016 CL– it still uses CSelCalcPointPredsFreqBased calculator and the result is the same – 1 row. We may see the result of this cardinality estimation of the tree after Project Normalization with a TF 2363. Both statistics trees for both queries have the same shape and estimate:
|
1 2 3 |
CStCollFilter(ID=4, CARD=1) CStCollProject(ID=3, CARD=3652) CStCollBaseTable(ID=1, CARD=3652 TBL: dbo.DimDate AS TBL: d) |
Then the optimization process starts to search different alternatives and stores them in a Memo structure, internal structure to store plan alternatives (I described it a couple of years ago in my Russian blog). For the CL 2016 – the sUDF estimation change of 10% guess plays its role during that search, the predicate is estimated as 365 rows and the plan shape with Clustered Index Scan is selected, however, this plan alternative goes to the Memo group which has the cardinality estimated to 1 row, during the very first Project Normalization phase. For the CL 2014 no surprise if the estimate both for sUDF and Predicate over expression – is 1 row, so the plan with lookup is selected.
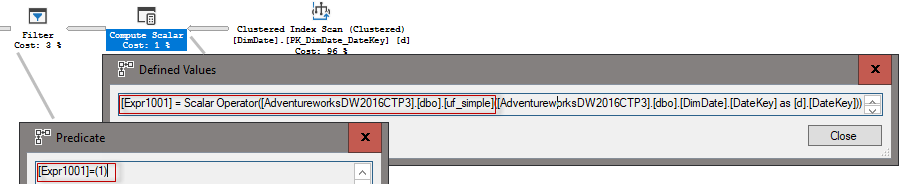
You may observe different predicates in the query plans also. For the 2014 CL the predicate is inside the Filter.

For 2016 CL the sUDF is computed as a separate Compute Scalar and the Filter is on the Expr1001 predicate.
There is an undocumented TF 9259 to disable a project normalization phase, let’s re-run our query with this TF.
|
1 2 3 4 |
alter database [AdventureworksDW2016CTP3] set compatibility_level = 130; go select * from dbo.DimDate d where dbo.uf_simple(d.DateKey) = 1 option(querytraceon 9259); go |
The estimate is now 365.2 which is much more clearly explains, why a server decided to choose a Clustered Index Scan instead of Index Scan + Lookup.
Microsoft is aware of this situation and considers it to be normal, I would agree with them, but that one row estimate combined with Clustered Index Scan puzzled me and I decided to write about it.
Conclusion
In 2016 (as well as in 2014 + TF 4199 and latest SPs or CUs) there is a cardinality estimation change in sUDFs estimation – the old version uses the density from base statistics and the new version uses 10% guess. The estimation for the expression predicates over sUDFs are not changed. Sometimes you may see little artifacts of project normalization in a query plan, but that shouldn’t be a problem.
Both of the estimations, in 2014 and 2016, are guesses, because sUDF is a black box for the optimizer (and also not good in many other ways), so avoid using it in general, especially in predicates.
Note
Please, don’t use TF 9259 that disables Project Normalization step in a real production system, besides it is undocumented and unsupported, it may hurt your performance. Consider the following example with computed columns.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
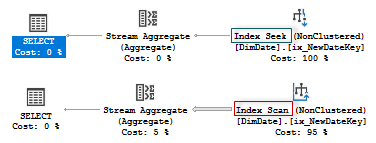
use AdventureworksDW2016CTP3; go alter table dbo.DimDate add NewDateKey as DateKey*1; create nonclustered index ix_NewDateKey on dbo.DimDate(NewDateKey); go set statistics xml on; select count_big(*) from dbo.DimDate where NewDateKey = 1; select count_big(*) from dbo.DimDate where NewDateKey = 1 option(querytraceon 9259); set statistics xml off; go drop index ix_NewDateKey on dbo.DimDate; alter table dbo.DimDate drop column NewDateKey; |
The query plans are Index Seek in the first case and Index Scan in the second one.
Thank you for reading!

Currently he works as a database developer lead, responsible for the development of production databases in a media research company. He is also an occasional speaker at various community events and tech conferences. His favorite topic to present is about the Query Processor and anything related to it. Dmitry is a Microsoft MVP for Data Platform since 2014.
View all posts by Dmitry Piliugin
- SQL Server 2017: Adaptive Join Internals - April 30, 2018
- SQL Server 2017: How to Get a Parallel Plan - April 28, 2018
- SQL Server 2017: Statistics to Compile a Query Plan - April 28, 2018