
Some time ago, SQL Server 2017 was released and issued as CTP. The most exciting release in that CTP was that SQL Server now supports Linux! This is awesome and I consider it to be great news for many people.
I am personally interested in the new features of query processing, and finally I had some time to install the SQL Server 2017 and dig a little bit into it. Currently, it is CTP 1.2 available, and I will use this version for my experiments.
While exploring new extended events, I’ve found an interesting event compilation_stage_statistics and one of the columns of this event was trivial_plan_scanning_cs_index_discarded with the following description “Number of trivial plans discarded or could have been discarded which scan Columnstore index”. That pushed me to do some investigations of the topic.
Let’s try to make some experiments.
I use AdventureworksDW2016CTP3 and make a test table with a single clustered Columnstore index on it.
|
1 2 3 4 5 6 7 |
use AdventureworksDW2016CTP3; go -- Create a test table with Clustered columnstore index drop table if exists dbo.FactResellerSales_CCI; select * into dbo.FactResellerSales_CCI from dbo.FactResellerSales; create clustered columnstore index cix on dbo.FactResellerSales_CCI; go |
Let’s run a couple of queries that result in a trivial plan under compatibility level 130 (SQL Server 2016) and look at their plans.
|
1 2 3 4 5 |
-- set compatibility level of SQL Server 2016 alter database AdventureworksDW2016CTP3 set compatibility_level = 130; go select count_big(*) from [dbo].[FactResellerSales_CCI] f where f.CurrencyKey > 0; select sum(SalesAmount) over(order by OrderDateKey) from dbo.FactResellerSales_CCI; |
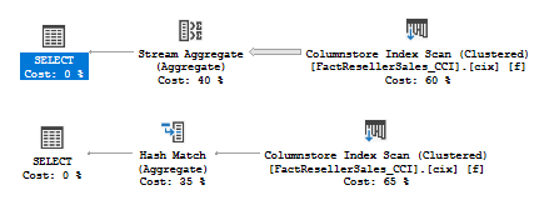
The plans are:

Both plans qualify trivial plan conditions so both of them are trivial and run in a Row Mode.
There is a TF 8757, that I described a few years ago, in my Russian blog, that forces the optimizer to skip trivial plan phase. Let’s turn it on and run our queries again.
|
1 2 3 4 5 6 7 |
alter database scoped configuration clear procedure_cache; dbcc traceon (8757); go select count_big(*) from [dbo].[FactResellerSales_CCI] f where f.CurrencyKey > 0 select sum(SalesAmount) over(order by OrderDateKey) from [dbo].[FactResellerSales_CCI]; go dbcc traceoff (8757); |
What we see in the query plans is completely different from what we have seen earlier.
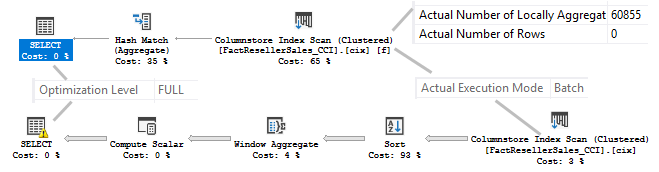
Both queries are now fully optimized and that lead to different plans. First of all, both queries run in a Batch Mode, which is much faster than a Row Mode.
In the first query, we see Hash Match Aggregate instead of Stream Aggregate, more to the point you may see that Actual Number of Rows is 0 because all the rows were aggregated locally at the Storage Engine level, you may see property Actual Number of Locally Aggregated Rows = 60855. This is faster than a regular aggregation and is known as Aggregate Pushdown.
In the second query, you may observe a new Window Aggregate operator which is faster than a Window Spool and runs in Batch Mode also.
Turning on Compatibility level SQL Server 2017Let’s turn on Compatibility level for SQL Server 2017, which is 140 in CTP 1.2, and re-run two queries without any TFs.
|
1 2 3 4 5 6 |
alter database AdventureworksDW2016CTP3 set compatibility_level = 140; alter database scoped configuration clear procedure_cache; go select count_big(*) from [dbo].[FactResellerSales_CCI] f where f.CurrencyKey > 0 select sum(SalesAmount) over(order by OrderDateKey) from [dbo].[FactResellerSales_CCI]; go |
You may see almost the same fully optimized plans, without any TFs.
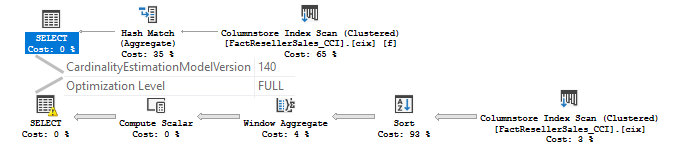
So, it seems, at least in CTP 1.2, that in SQL Server 2017 some plans with Columnstore indexes may skip trivial plan phase to have more benefits from the full optimization phase.
Undocumented TFsSome features in the query processor of SQL Server may have trace flags to control their behavior. This may be helpful in case of testing or if the new feature hurts performance.
Skipping trivial plan if Columnstore index is involved also have TFs. They are not documented and not supported (though, CTP itself is not intended for production and support) and might be removed in RTM, but at the moment of writing this post – they work.
If you want to try this feature (skip trivial plan for Columnstore) under Compatibility level 130, you may use trace flag 11002.
|
1 2 3 4 5 6 |
alter database AdventureworksDW2016CTP3 set compatibility_level = 130; alter database scoped configuration clear procedure_cache; go select count_big(*) from [dbo].[FactResellerSales_CCI] f where f.CurrencyKey > 0 select count_big(*) from [dbo].[FactResellerSales_CCI] f where f.CurrencyKey > 0 option(querytraceon 11002); go |
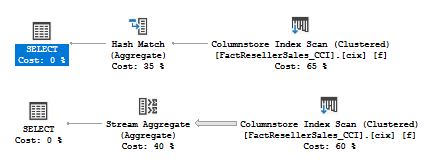
The plans are, accordingly:
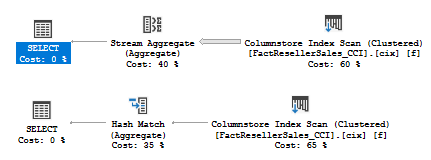
If you want to disable this feature in the new Compatibility level 140, you may use trace flag 11012.
|
1 2 3 4 5 6 |
alter database AdventureworksDW2016CTP3 set compatibility_level = 140; alter database scoped configuration clear procedure_cache; go select count_big(*) from [dbo].[FactResellerSales_CCI] f where f.CurrencyKey > 0 select count_big(*) from [dbo].[FactResellerSales_CCI] f where f.CurrencyKey > 0 option(querytraceon 11012); go |
The plans are, accordingly:
That’s all for today, but there a lot of other intriguing additions in SQL Server 2017.
Stay tuned, thank you for reading.
Table of contents

Currently he works as a database developer lead, responsible for the development of production databases in a media research company. He is also an occasional speaker at various community events and tech conferences. His favorite topic to present is about the Query Processor and anything related to it. Dmitry is a Microsoft MVP for Data Platform since 2014.
View all posts by Dmitry Piliugin
- SQL Server 2017: Adaptive Join Internals - April 30, 2018
- SQL Server 2017: How to Get a Parallel Plan - April 28, 2018
- SQL Server 2017: Statistics to Compile a Query Plan - April 28, 2018