In this article, we will explore ‘ Clustered columnstore online index build and rebuild’ feature of SQL Server 2019 including comparing execution plans, offline builds and more
Read more »
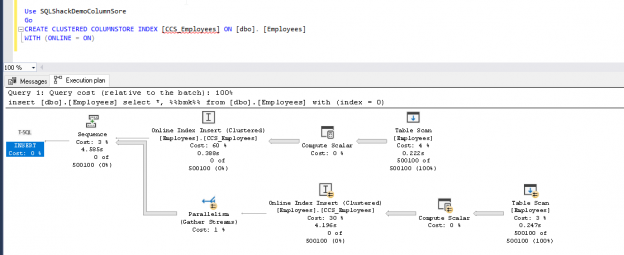
In this article, we will explore ‘ Clustered columnstore online index build and rebuild’ feature of SQL Server 2019 including comparing execution plans, offline builds and more
Read more »
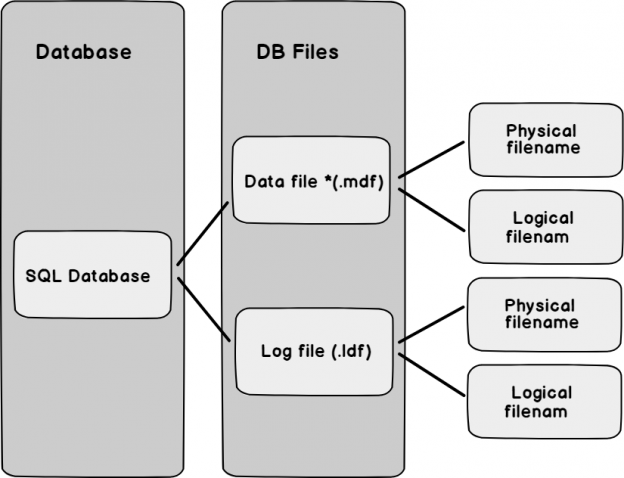
Each database in SQL Server contains at least two files i.e. Data file (*.mdf) and log file (*.ldf). These database files have a logical name and the physical file name. Below we can view the simple architecture of a database in SQL Server.
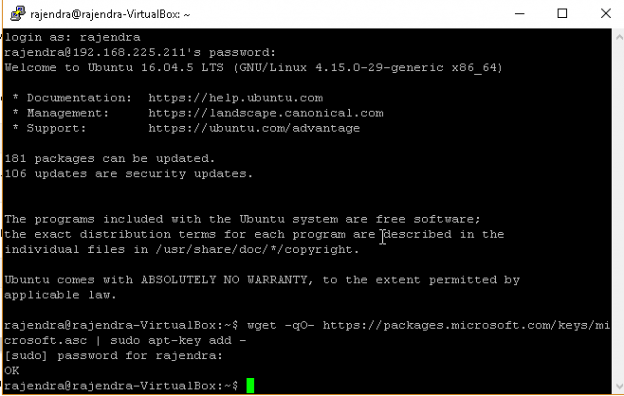
Until now, we learned to install and configure SQL Server 2019 using the Docker container. In this article, we will directly install SQL Server on the Ubuntu Linux and explore more on this.
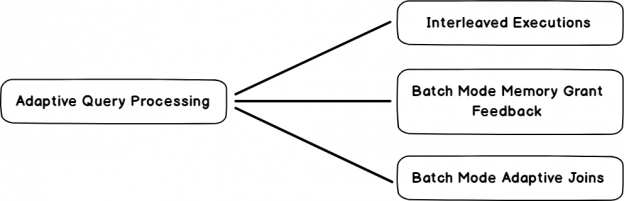
In this article, I’ll be exploring another new feature with SQL Server 2019, row mode memory grant feedback, along with a retrospective on adaptive query processing, examples and more.
Read more »
In my previous articles, we installed SQL Server 2019 on the windows environment (vs Linux / Ubuntu). We also explored some of the important enhancements in SQL Server 2019
In the first article of the series on SQL Server 2019 and Ubuntu, we prepared the virtual machine environment and installed Ubuntu 18.10 in it. In this part of the article, we will install the latest SQL Server 2019 Preview CTP 2.1.
Read more »
In the previous articles of this series on using SQL Server 2019 on Ubuntu, we have explored the following
Read more »
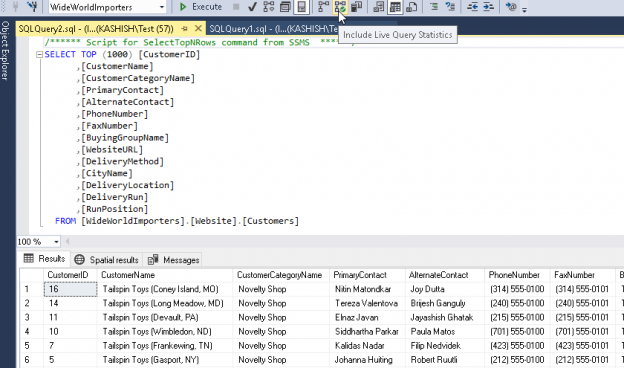
Database administrators are used to dealing with query performance issues. As part of this duty, it is an important aspect to identify the query and troubleshoot the reason for its performance degradation. Normally, we used to enable SET STATISTICS IO and SET STATISTICS TIME before executing any query.
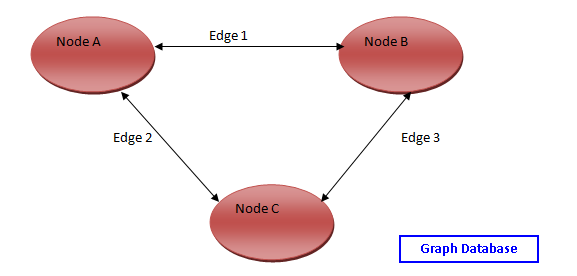
SQL Server 2017 introduced Graph database features where we can represent the complex relationship or hierarchical data. We can explore the following articles to get familiar with the concept of the Graph database.
Read more »
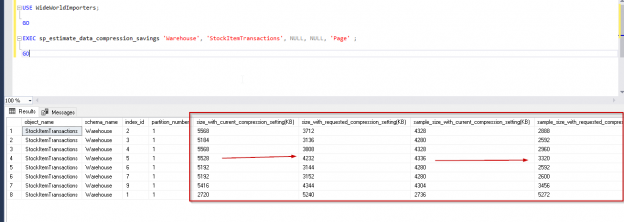
Data compression is required to reduce database storage size as well as improving performance for the existing data. SQL Server 2008 introduced Data compression as an enterprise version feature. Further to this, SQL Server 2016 SP1 and above supports data compression using the standard edition as well.
Read more »
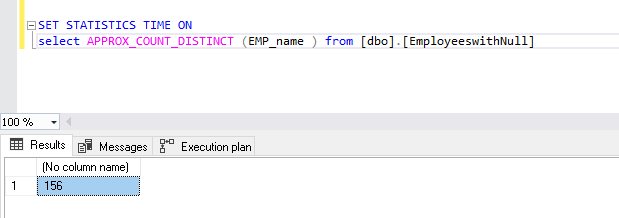
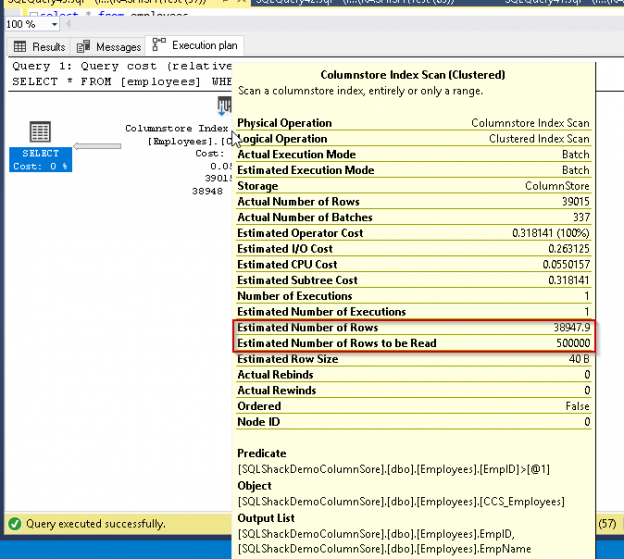
SQL Server 2019 has a rich set of enhancements and new features. In particular, there are many new feature improvements in the database engine for better performance and query tuning.
Read more »
SQL Server was launched in 1993 on WinNT and it completed its 25-year anniversary recently. SQL Server has come a long way since its first release. At the same time, Microsoft announced a preview version of SQL Server 2019. SQL Server 2019 provides the ability to extend its support to big data, Apache Spark, Hadoop distributed file system (HDFS) and provides enhancements to database performance, security, new features, and enhancements to SQL Server on Linux.
Read more »
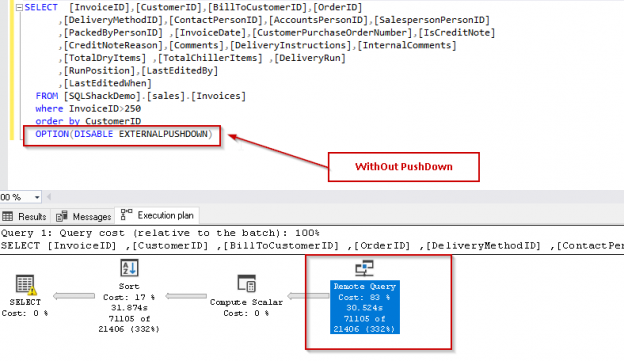
This article is part 4 of the series for SQL Server 2019 Enhanced PolyBase. Let quickly recap the previous articles.
Read more »
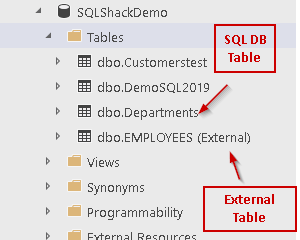
In this article on PolyBase, we will explore more use case scenarios for external tables using T-SQL.
Read more »
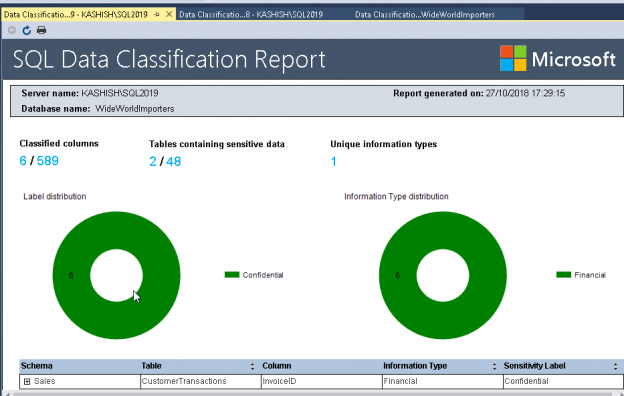
SQL Server 2019 offers powerful new features to help in safeguarding your data and complying with various privacy regulations, which we’ll be covering in this article
Read more »
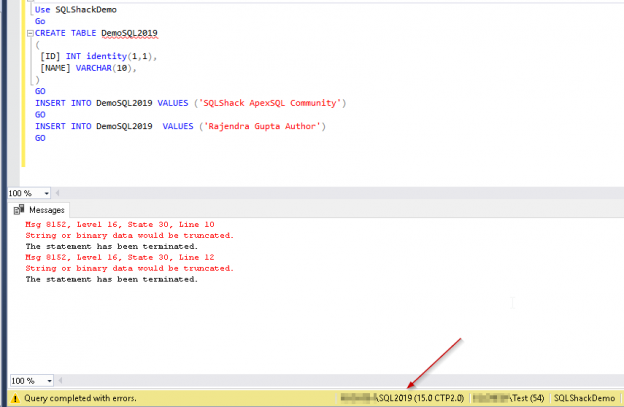
In this article, we’ll take a look into SQL truncate improvement in SQL Server 2019.
Data inserts and updates are a normal and regular task for the developers and database administrators as well as from the application. The source of the data can be in multiple forms as if direct insert using T-SQL, stored procedures, functions, data import from flat files, SSIS packages etc.
Read more »
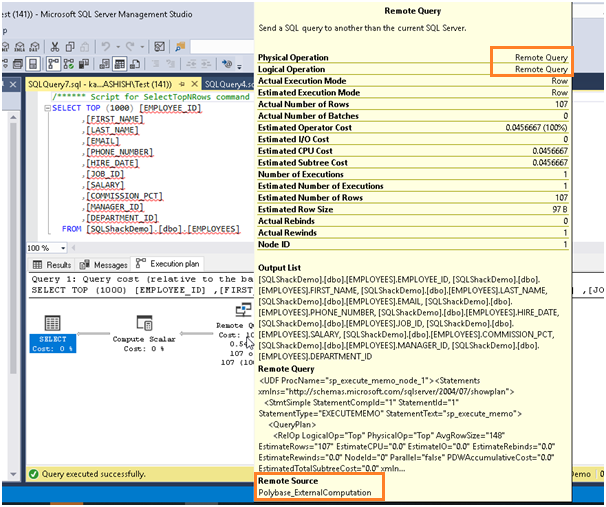
In the previous article of the series, we took an overview of PolyBase in SQL Server 2017. We also learned about the Azure Data Studio and SQL Server 2019 preview extension to explore SQL Server 2019 features.
Read more »
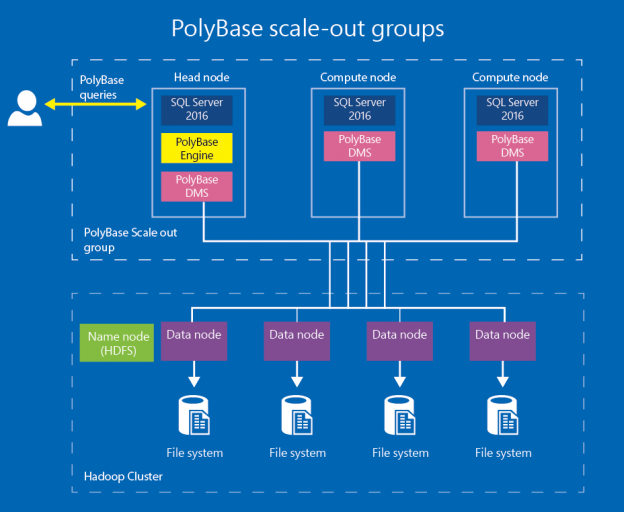
SQL Server 2019 is recently launched in the ignite 2018 event by Microsoft. We can get an overview of SQL 2019 preview version and learn how to install it on Windows environment by following up the article SQL Server 2019 overview and installation.
Read more »
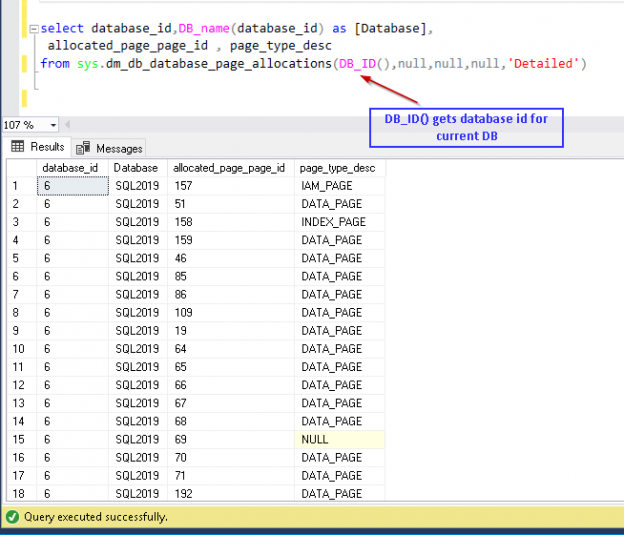
Microsoft released preview of SQL Server 2019 recently in Ignite 2018. With every release of SQL Server is enriched with new dynamic management view and functions along with enhancements to existing features.
In this article, we will view the newly introduced dynamic management function (DMF) sys.dm_db_page_info and explore the different scenarios around it.
Read more »
On September 24th, 2018, Microsoft launched SQL Server 2019 preview version (SQL Server vNext 2.0) in the ignite 2018 event. As you know, SQL Server 2017 is still being adopted by the organizations, we are now ready with this preview version.
Read more »
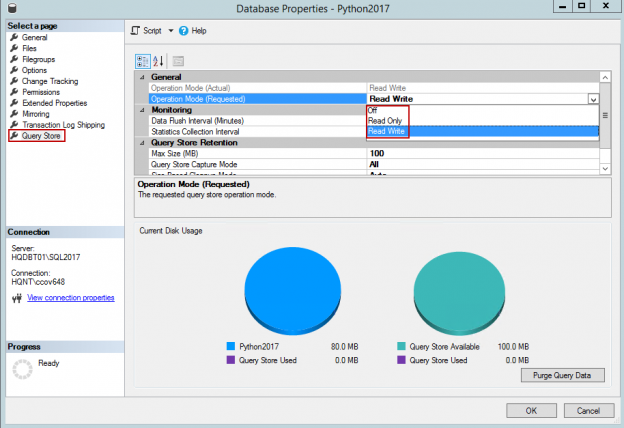
Monitoring databases for optimal query performance, creating and maintaining required indexes, and dropping rarely-used, unused or expensive indexes is a common database administration task. As administrators, we’ve all wished, at some point, that these tasks were simpler to handle.
Read more »
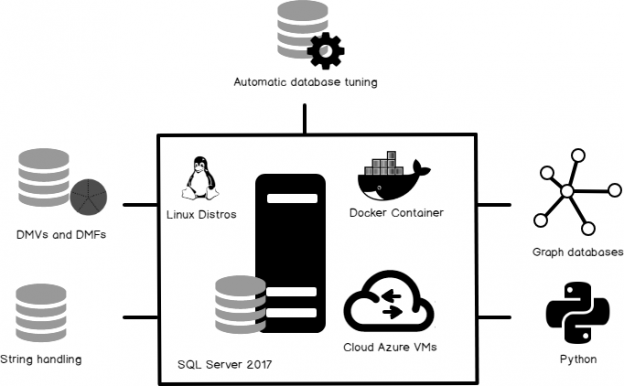
SQL Server 2017 is considered a major release in the history of the SQL Server life cycle for various reasons. From my personal point of view, SQL Server 2017 is indeed an interesting release. After writing lot about it and testing various features of SQL Server 2017, I’d like to walk you through some of its interesting features.
Read more »
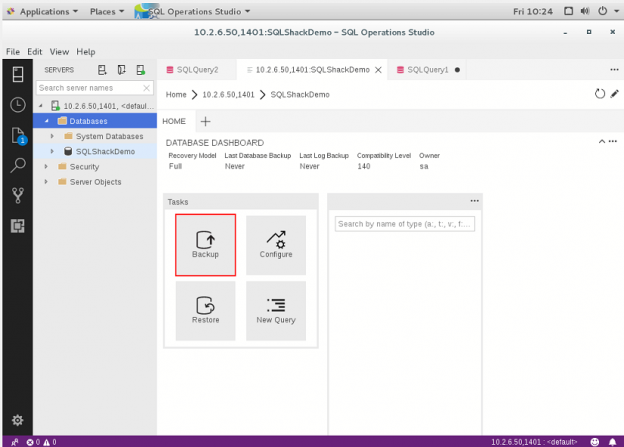
In this 18th article of the series, we will discuss the concepts of database backup-and-restore of SQL Server Docker containers using Azure Data Studio. Before proceeding, you need to have Docker engine installed and Azure Data Studio configured on your host machine.
This article covers the following topics:

I’ve always been in favor of an orthodox strategy when it comes to applying SQL Server updates which often goes like:

The new SQL Server 2017 comes with new features in the installation. It now supports Machine Learning Services that support R and Python. It also includes SSIS Scale Out Master and Scale Out Worker. It also includes scale out options in PolyBase.
Read more »© Quest Software Inc. ALL RIGHTS RESERVED. | GDPR | Terms of Use | Privacy