In this article, we will install and configure SQL Server Linux (2017 version) on SUSE Linux in the Amazon EC2 Instance.
Read more »
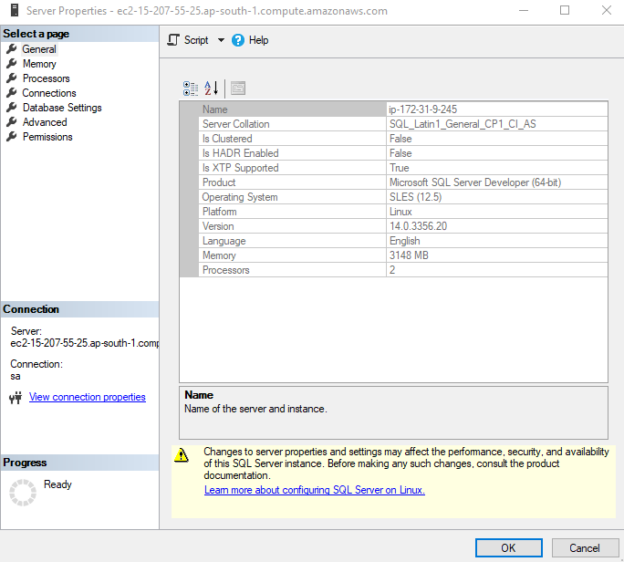
In this article, we will install and configure SQL Server Linux (2017 version) on SUSE Linux in the Amazon EC2 Instance.
Read more »
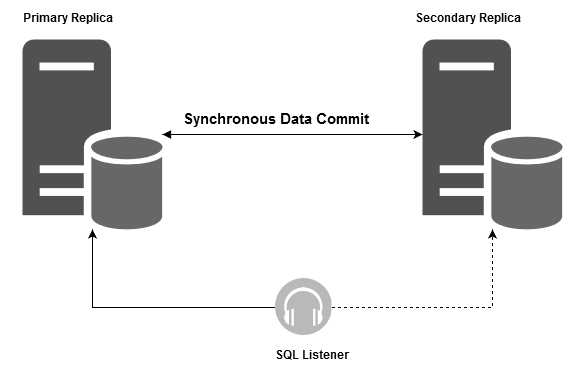
It is the 30th article in the SQL Server Always On Availability Groups series and explores column-level SQL Server encryption with AG groups.
Read more »
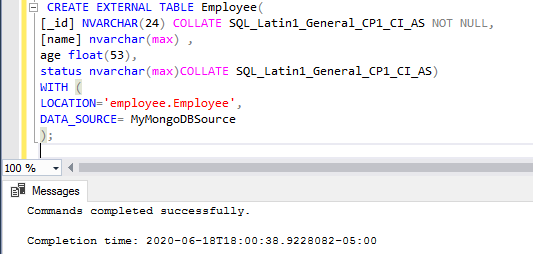
In this article, you’ll learn the approach to integrate MongoDB data source using data virtualization technique in SQL Server 2019. In this article, you can see how SQL Server 2019 provides a platform to create a modern enterprise data hub using data virtualization technology and the PolyBase technique.
Read more »
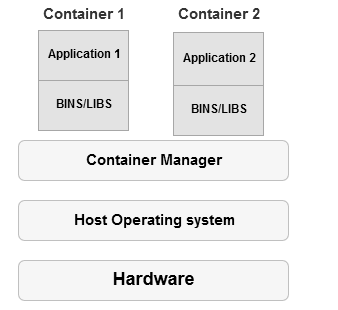
In this article, we will install the SQL Server Express edition on Windows Server 2016 using a SQL Server Docker container.
Read more »
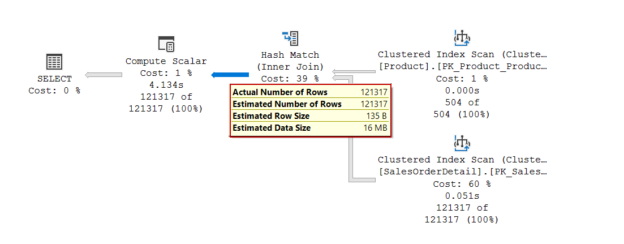
In this article, we will explore a new SQL Server 2019 feature which is Scalar UDF (scalar user-defined) inlining. Scalar UDF inlining is a member of the intelligent query processing family and helps to improve the performance of the scalar-valued user-defined functions without any code changing.
Read more »
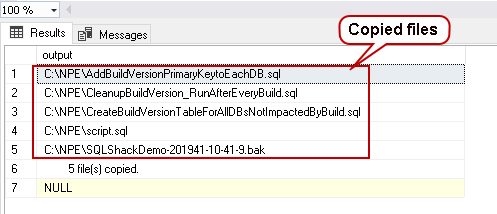
Sometimes database professionals need to perform specific tasks at the operating system level. These tasks can be like copying, moving, deleting files and folders. A use case of these tasks might be removing the old backup files or copying backup files to a specific directory after a particular time. In SQL Server, we can use xp_cmdshell extended stored procedure to execute commands directly in the Windows command prompt(CMD). You need a sysadmin role or proxy account configured to use this extended procedure. We can also use the SSIS package for the file transfer, but it also requires you to build a package with the relevant tasks.
Read more »
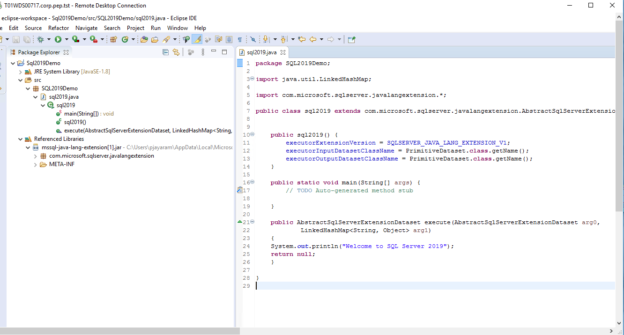
In this article, we will discuss SQL Server 2019 new feature—Java Language Extensions. With the advent of SQL Server 2019, Microsoft always strives to expand its footprint on the capabilities of MLS (Machine Learning Services). It builds a deeper integration between the data-platform and data science under the data science umbrella. The Microsoft SQL Server 2019 MLS extensibility framework provides a solid base for allowing extensions in R, Python, and now Java.
Read more »
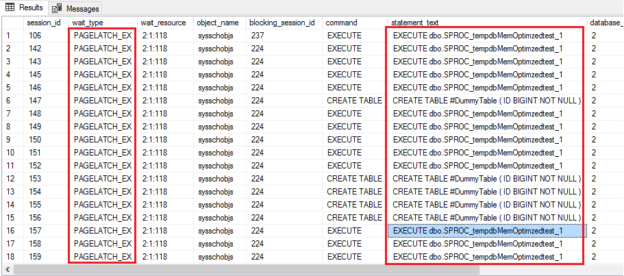
In this article, I will walk you through the new feature in SQL Server 2019, memory-optimized TempDB metadata. The most commonly faced performance problems in SQL Server world is known to be TempDB resource contention. Don’t you agree? Let us find the answer in this article.
Read more »
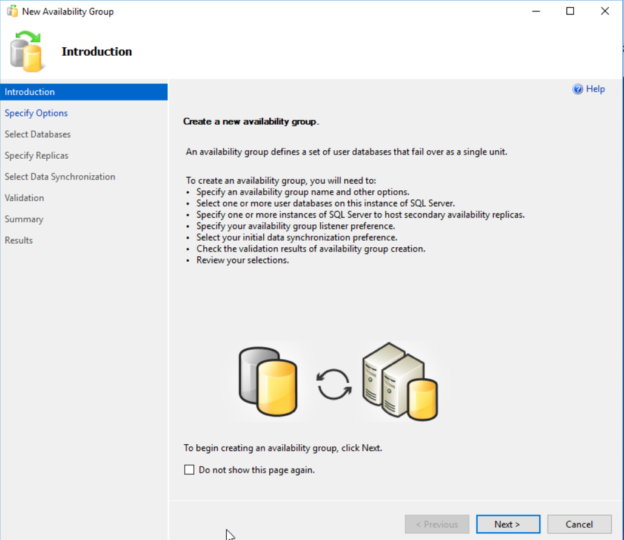
In this article, we will proceed with configuring a SQL Server Always On Availability Groups and perform failover validations.
Read more »
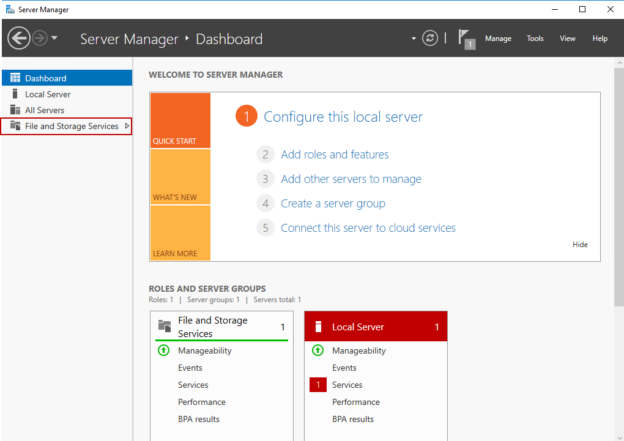
In this article, I am going to explain how we can install and configure the iSCSI Target Server Role on Windows Server 2016. iSCSI stands for Internet Small Computer System Interface and iSCSI Target Server allows you to boot multiple computers from a single operating system (OS) image.
Read more »
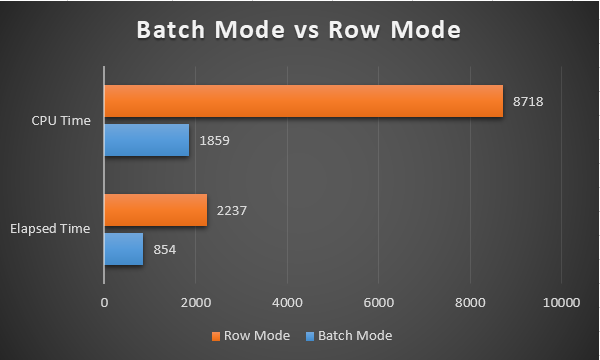
In this article, we will explain batch mode on rowstore feature, which was announced with SQL Server 2019. The main benefit of this feature is that it improves the performance of analytical queries, and it also reduces the CPU utilization of these types of queries. Behind the scene, this performance enhancement uses the batch mode query processing feature for the data, which is stored in row format. Also, this feature has been using by columnstored indexes for a long time.
Read more »
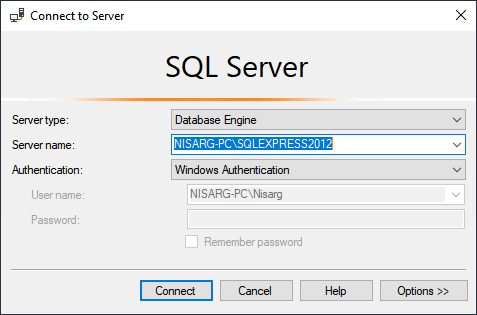
In this article, I am going to explain how we can install SQL Server 2012 express edition using the SQL Server installation center. Additionally, I will also explain how we can use the SQL Server installation configuration file to perform an unattended (silent) installation. First, download the SQL Server express edition from this location. Once the installation file is downloaded, let us begin the installation process.
Read more »
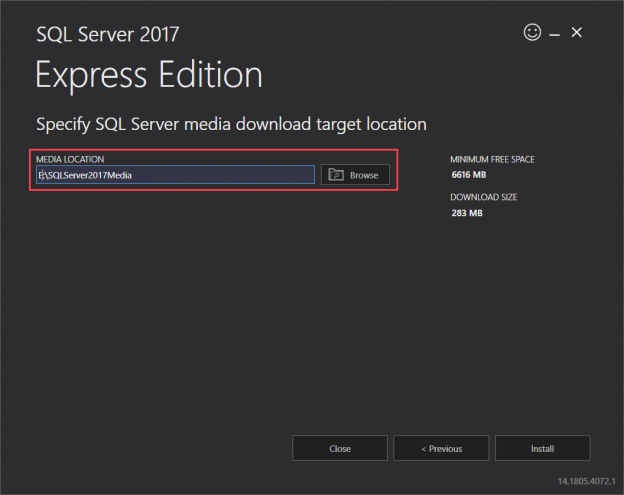
In this article, I am going to explain how to install the SQL Server Express edition. We will download the SQL Server 2017 Express edition and perform the custom installation. Before we dive-in into the installation and configuration process, let me introduce you to the SQL Server Express edition.
Read more »
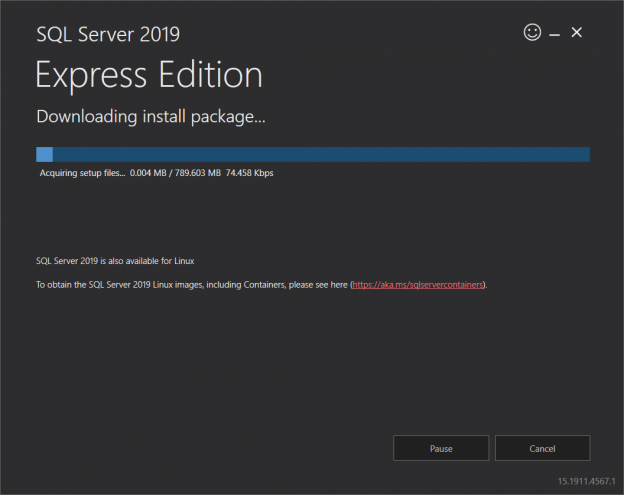
SQL Express is a free and feature-limited edition of SQL Server that has been being published since the SQL Server 2005 version and it still continues to be published by Microsoft. Nowadays, Microsoft has released the Express edition of SQL Server 2019. We can use this edition for lightweight data-driven mobile, desktop or web applications. However, when we decide to use this edition, the supported features have to be checked in the Editions and supported features of SQL Server 2019. For example, the database size can not exceed 10 GB and the SQL Server Agent feature is not supported by the Express editions. As a result, we must take the limited features into consideration before planning to use the SQL Express Editions.
Read more »
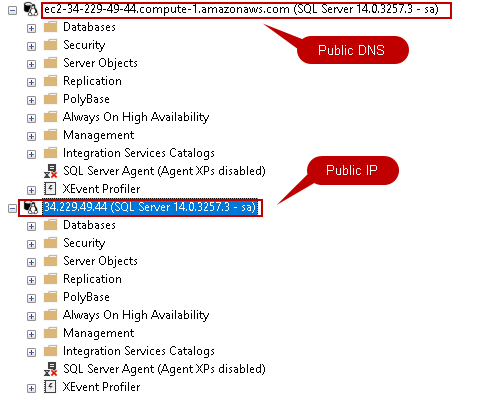
This article installs SQL Server on Linux on the Amazon EC2 instance with Red Hat OS prepared in the earlier article.
Read more »
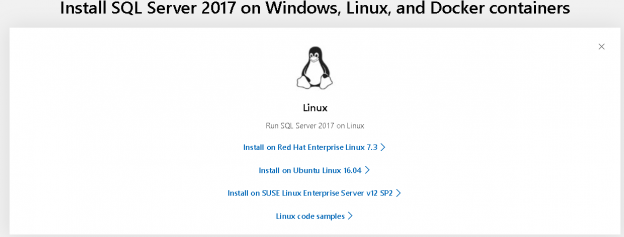
This article explores the configuration of the Red hat Amazon EC2 instance for SQL Server installation.
Read more »
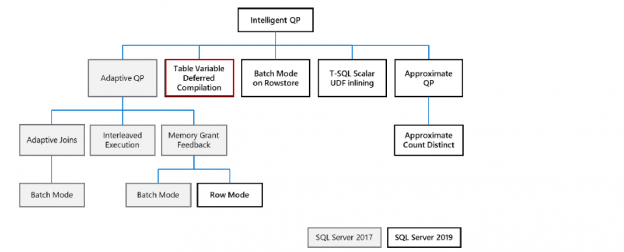
In an article, An overview of the SQL table variable, we explored the usage of SQL table variables in SQL Server in comparison with a temporary table. Let’s have a quick recap of the table variable:
Read more »
On November 4th, 2019, during the Ignite conference at Orlando, Microsoft released the General Availability of its flagship product Microsoft SQL Server 2019. SQL 2019 provides various enhancements to its core database engine and offers integration with Big data (Apache Spark, Data Lake), Machine learning, Linux/container compatibility with Kubernetes.
Read more »

This article serves as a SQL Server Download guide for both beginners and beyond. Some years ago, it was pretty simple to download the installer because you had all the components installed. Now, it is harder because you need to install several components, there are several versions and editions. This guide will help you to understand which version and edition needs to be downloaded.
Read more »

In-memory technologies are one of the greatest ways to improve performance and combat contention in computing today. By removing disk-based storage and the challenge of copying data in and out of memory, query speeds in SQL Server can be improved by orders of magnitude.
Read more »
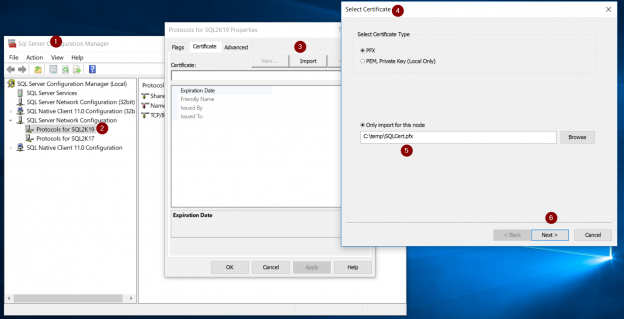
Certificate Management in SQL Server 2019 has been enhanced a lot when compared with previous versions of SQL Server, and it is part of a large set of new features and enhancements in SQL Server 2019. The most significant enhancement is that that it now allows you to directly import SSL/TLS certificates into SQL Server, thus simplifying the entire process a lot.
Read more »
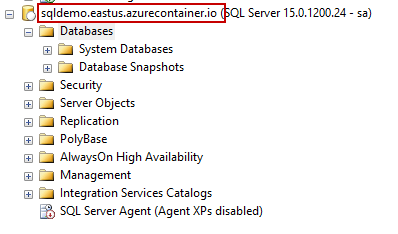
This guide is all about provisioning SQL Server 2019 using Azure Container Instance (ACI), including the installation and configuration. In this article, we talk about the Azure Container Instance (ACI), the Azure PowerShell module, installation and configuration of SQL Server using the Azure PowerShell module, and automation of installation and deployment using templates.
Read more »
In SQL Server, we normally use user-defined functions to write SQL queries. A UDF accepts parameters and returns the result as an output. We can use these UDFs in programming code and it allows writing up queries fast. We can modify a UDF independently of any other programming code.
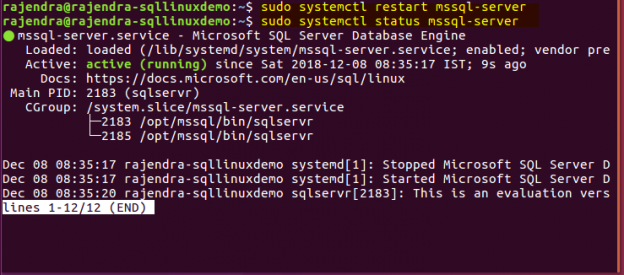
In my previous articles, we installed the SQL Server 2019 CTP 2.1 on Ubuntu Linux. You can follow the below articles to prepare the SQL instance on Linux.
In this 5th part of the ongoing series of SQL Server 2019 Enhanced PolyBase, we will learn how to install and configure MongoDB and create an external table.
Read more »© Quest Software Inc. ALL RIGHTS RESERVED. | GDPR | Terms of Use | Privacy